Bib20-0402-2 【図解】コレ1枚でわかる最新ITトレンド
【2018年7月5日】第0章更新
表紙
第0章 ITの最新トレンド
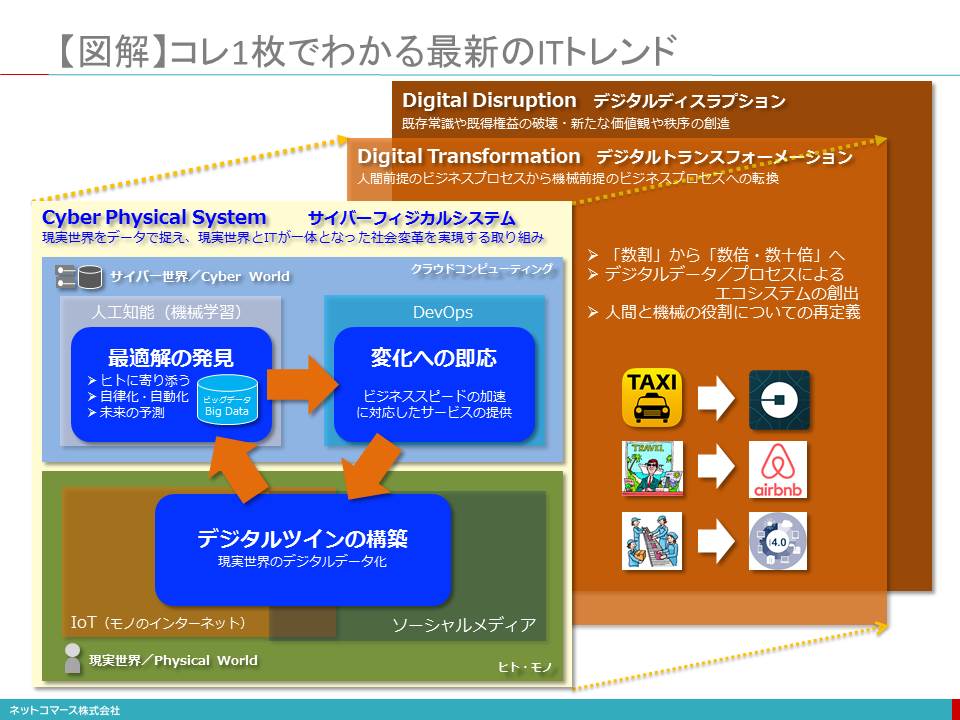
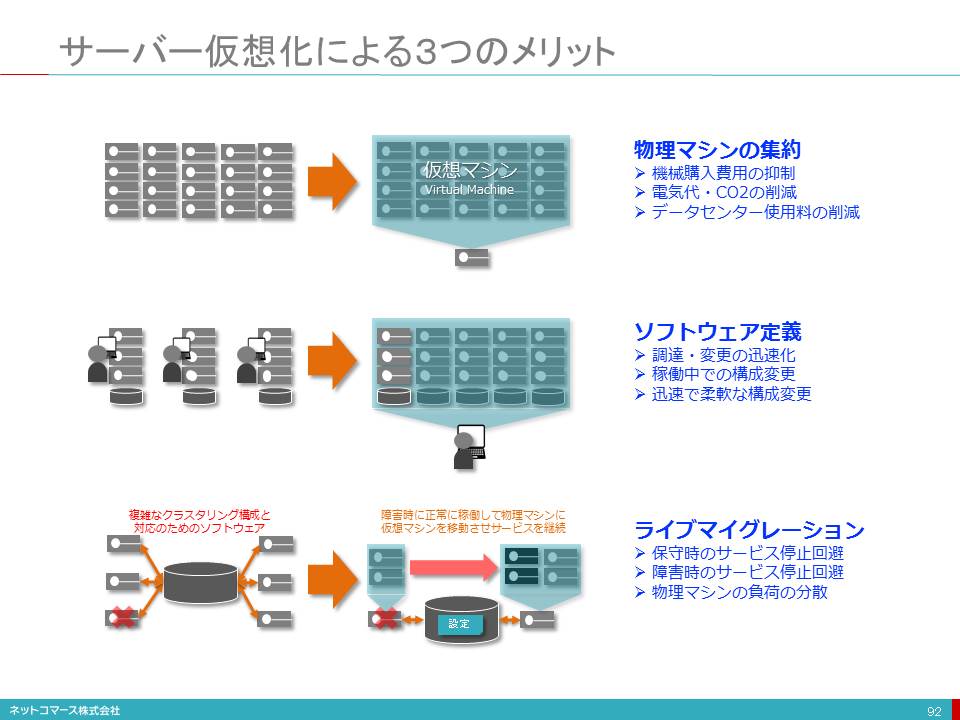
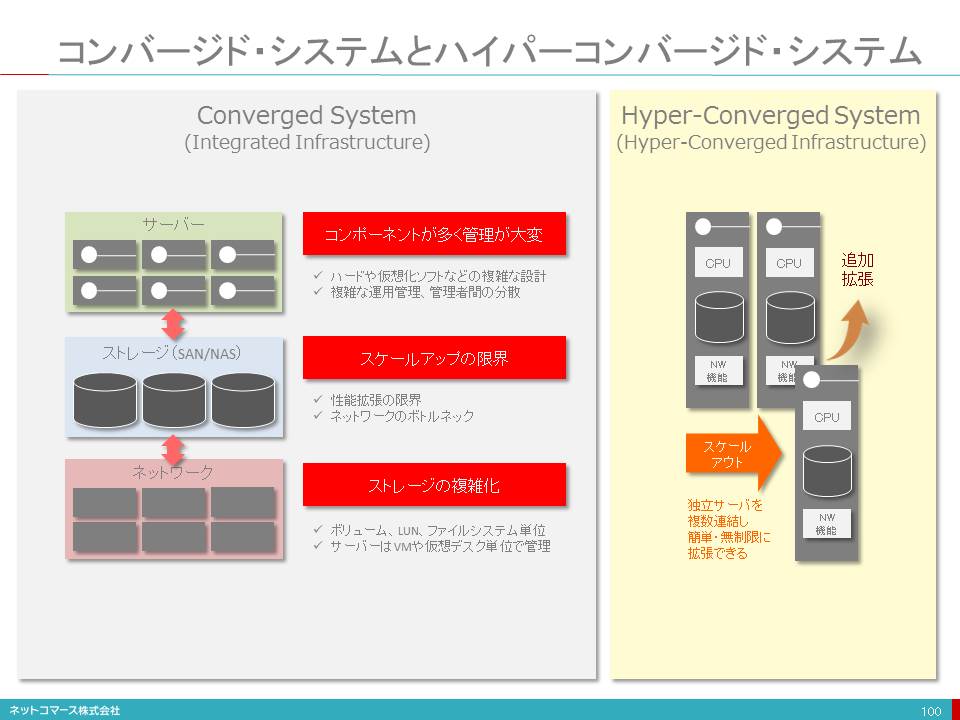
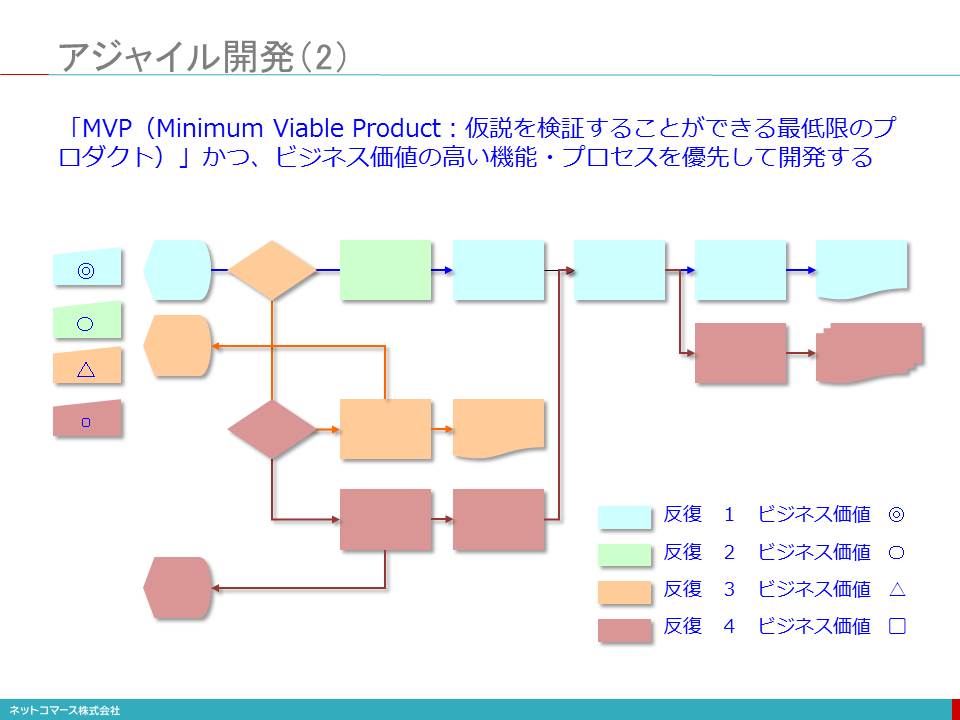
【図解】コレ1枚でわかる最新のITトレンド
図解
■トレンドを知るとはどういうことか?
トレンドとは「過去から現在を通り越して未来に向かう流れ」
「トレンド(Trend)」という言葉を辞書で調べると「流行」、「傾向」、「動向」と説明されています。古典英語では、「回転する」、あるいは「向く」といった説明もありました。こんな説明を頼りに考えてみると、「過去から現在を通り越して未来に向かう流れ」すなわち「時流」という解釈もできそうです。
そう考えれば、「トレンドを知る」とは、ネットや雑誌、書籍に散在する最新のキーワードを脳みそにコピペして並べることでもなければ、その説明を辞書のように暗記することでもなさそうです。ならば、つぎのように整理してみてはどうでしょう。
過去を知る:歴史的背景や当時のニーズを知ること
現在を知る:お互いの役割や関係、構造を知ること
未来を知る:これから起こる変化や影響を知ること
世の中のニーズに応えようとしてテクノロジーは完成度を高める
特に「ニーズ」を知ることは、とても大切なことです。例えば「クラウド」は、始めに「クラウド」というテクノロジーがあったから世の中が注目したのではありません。まずはクラウドを求める理由が世の中にあったのです。そして、「クラウド」は世の中に受け入れられ生き残ってきました。そして世の中のニーズにさらに応えようとして完成度を高め、ますます注目を集めるようになったのです。やがては新しいテクノロジーと融合することや置き換えられることで、その役目を終えてゆくのです。
ニーズを知れば、その価値が分かります。
ニーズの変化を知れば、やがて私たちの社会やビジネスが、どのようになってゆくかを予測することができます。
そんな時間の流れを、ひとつの物語として捉えることが「トレンドを知る」ということなのです。
■ITは、いまどこに向かっているのでしょうか?
これまでの常識を上書きするようなテクノロジーの登場が折り重なり、お互いに影響を及ぼし合っている
いま私たちはこれまでにないパラダイムの転換に直面しています。1990年代の前半に登場したインターネットが、ITと私たちの関係を大きく変えることとになりました。それを土台に、クラウド、人工知能、IoT(モノのインターネット)など、これまでの常識を上書きするようなテクノロジーの登場が折り重なり、お互いに影響を及ぼし合っています。
「機能や役割はそのままに、その繋がり方や役割分担が変わった」といった分かりやすいものではない
かつて大型コンピューターであるメインフレームが、小型のオフコンやミニコン、PCに置き換わったような、あるいは集中処理から分散処理やクライアントサーバーに移行してきたような、「機能や役割はそのままに、その繋がり方や役割分担が変わった」といった分かりやすいものではありません。そのことがITトレンドの理解を難しくしているのです。
ただ、それは無秩序なものではありません。
キーとなるテクノロジーは、お互いに役割を分かちながら大きな仕組みとして機能しています。
そんな「ITトレンド」を1枚のチャートにまとめてみました。解説と共にご覧頂ければ、その全体像を大きく見渡していだくことができるはずです。
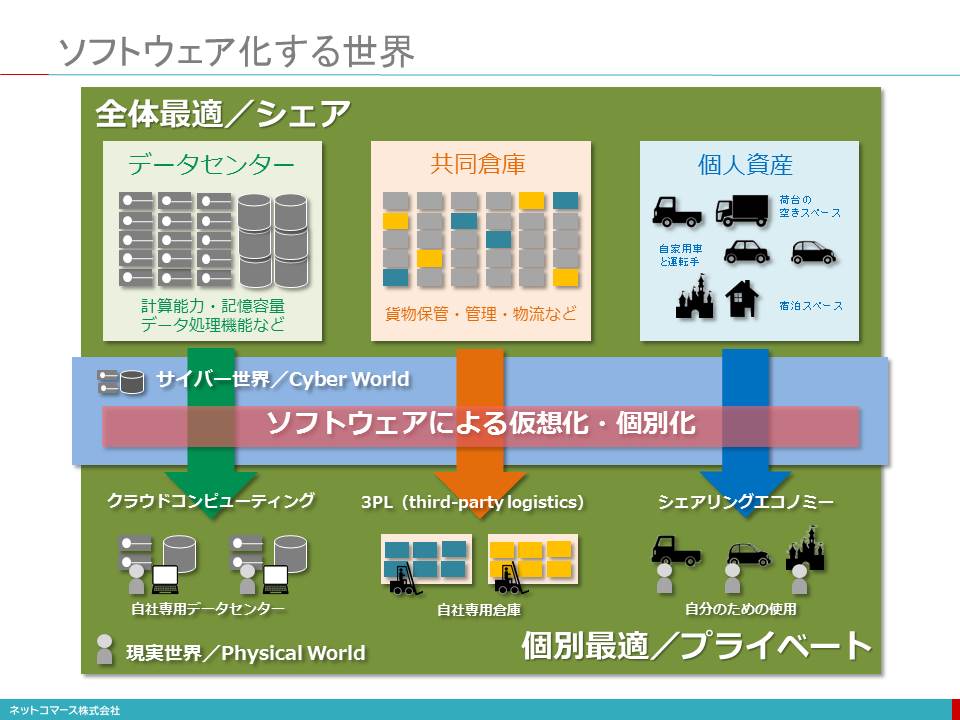
■現実世界をデジタル・データ化するIoTとソーシャル・メディア
現実世界(Physical World)
私たちの住む「現実世界(Physical World)」は、様々なモノと多くのヒトで満ちあふれています。それらが、お互いに関係を持ち、影響を及ぼし合いながら社会や経済を動かしています。そんな現実世界はアナログで、連続的で途切れることのない時間と物質によって満たされています。地理的な距離はモノやヒトを隔てる絶対的な壁であり、時間は不可逆的で巻き戻すことはできません。
「現実世界のデジタル・コピーが作られてゆく」
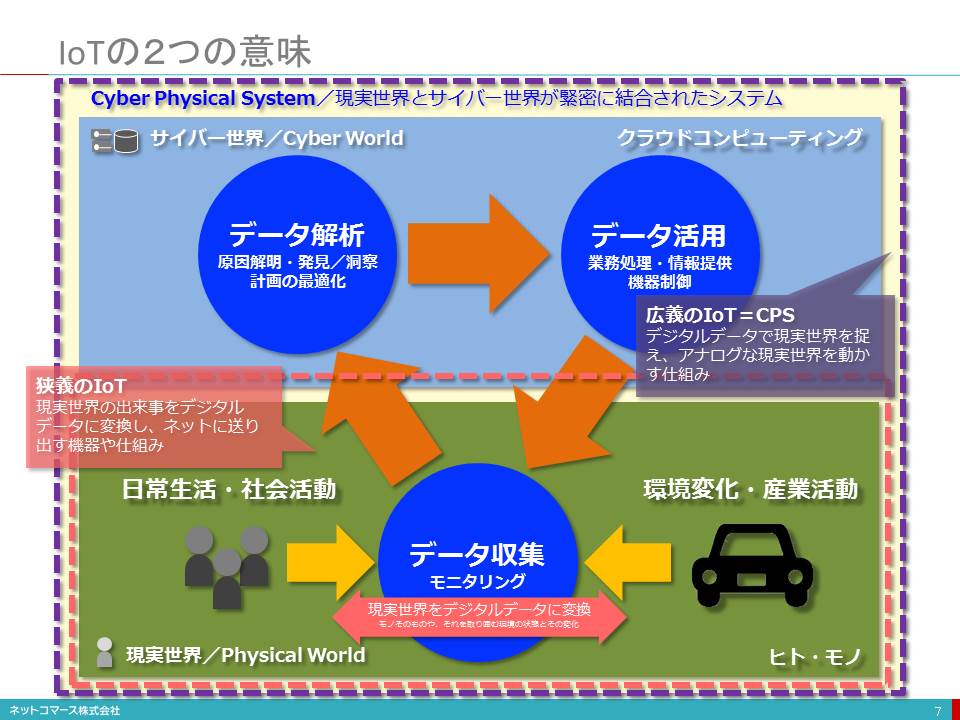
そんなアナログな現実世界をモノに組み込まれたセンサーによってデジタル・データとして捉えようという仕組みがIoT(モノのインターネット/Internet of Things)です。
IoTにより、「現実世界のデジタル・コピーが作られてゆく」と解釈することもできます。
デジタル・コピーが「サイバー世界(Cyber World)」へ送られていく
そんな時々刻々の状態を写し撮ったデジタル・コピーが、インターネットの向こうにあるクラウド・コンピューティングの世界、すなわち「サイバー世界(Cyber World)」に送られ、積み上げられてゆきます。
デジタル・コピーは、「デジタル・ツイン(Digital Twin)」とも呼ばれる
このデジタル・コピーは、「現実世界とうりふたつのデジタルな双子の兄弟」という意味で「デジタル・ツイン(Digital Twin)」とも呼ばれています。
デジタル・ツインの効果
そんなデジタル・ツインはサイバー世界のデータですから、地理的距離を一瞬にして行きでき、時間を自由に遡ることができます。それにより、
これまでには考えられなかった新しいヒトやモノ、あるいはプロセスの組合せを生みだす。
過去のデジタル・ツインに埋め込まれている事実から、ものごとの因果関係や原因を見つけ出す。
いまどうなっているかをリアルタイムに教えてくれる。
データに刻み込まれた規則性を見つけ出し、そこから未来を予見できる。
スマートフォン、ウェアラブル
具体的には、スマートフォンには、位置情報を取得するGPSや身体の動きや動作を取得する様々なセンサーが組み込まれています。私たちが、それを持ち歩き使用することで、日常の生活や活動がデータ化されます。ウェアラブルは身体に密着し、脈拍や発汗、体温などの身体状態がデータ化されます。
自動車
自動車には既に100ほどのセンサーが組み込まれています。住宅や家電製品、空調設備や照明器具などの「モノ」にもセンサーが組み込まれ、様々な出来事がデータ化されようとしています。それらがインターネットにつながり、取得したデータを送り出す仕組みが作られつつあります。
「ソーシャル・メディア」は、デジタル・ツインのもう一つの役割を担う
デジタル・ツインを築く役割を担うもうひとつの仕組みが「ソーシャル・メディア」です。例えば、私たちはスマートフォンやタブレットを使い、FacebookやLINEなどで、写真や動画、自分の居場所の情報をデジタル・データにしてネットに送り出しています。また、流行や話題、製品やサービスの評判について、地域や時間を越えて様々な人たちと意見を交換しています。
また「友達になる」や「フォローする」ことで、ヒトとヒトとのつながり(ソーシャル・グラフ)についての情報を生みだし、インターネットに送り出しています。
ソーシャル・メディアは、IoTとも融合
これらソーシャル・メディアはスマートフォンやタブレットだけではなく、IoTと融合して自動車や住宅、家電製品とも繋がり、持ち主に必要な情報を送り出します。また、それらを遠隔から操作できるようにもなります。さらに、自動車会社や様々なサービス提供会社とも繋がり、自動車の点検や整備に関するお知らせを受け取ったり、お勧めのレストランに案内したりするなどの便宜をもたらしてくれます。
また、自動車や家電製品、工場の設備などの動作や使用状況は、IoT機能によってデータとしてメーカーに送られると、それらを分析して保守点検のタイミングを知らせ、製品開発にも活かされます。また家庭の電球に組み込まれたセンサーがインターネットにつながれば、そろそろ電球が切れることをスマートフォンに知らせ代替製品の注文までしてくれるかもしれません。
IoTはソフトウェアによって制御され、データはビジネスに活用される
モノは、そこに組み込まれたソフトウェアによって制御されています。そのソフトウェアを遠隔から入れ替えることで性能を向上させたり、機能を追加したりすることができるようになります。その一方で、そこでやり取りされるデータは、個々人の行動や趣味嗜好を捉え、マーケティングのためにも利用されることになります。
「現実世界をデジタル・データ化」する巨大な仕組みになろうとしている
インターネットにつながっているモノやスマートフォン、タブレットは、2009年に25億個だったものが2020年には300〜500億個へと急増するとされています。
このように見てゆくとIoTとスマート・メディアは、「現実世界をデジタル・データ化」する巨大な仕組みになろうとしているのです。
■最適解を見つけ出す人工知能
ビッグデータとは
IoTやソーシャル・メディアから生みだされるデータは、インターネットを介して、クラウドに送られます。インターネットにつながるデバイスの数が劇的な拡大を続ける中、そのデータ量は、急速な勢いで増え続けています。このようなデータを「ビック・データ」と呼びます。
ビッグ・データとして集まった現実世界のデータを、どのような意味や規則性があるを解析し、価値ある情報とした
ビッグ・データとして集まった現実世界のデータは、分析(アナリティクス)されなければ、活かされることはありません。しかし、そのデータの内容や形式は多種多様であり、しかも膨大です。
そのため、単純な統計解析だけでは、そこにどのような意味や規則性があるのか分からず、価値ある情報を引き出せないのです。
解決する手段として、「人工知能(AI : Artificial Intelligence)」や「機械学習(ML:Machine Learning)」が注目を浴びている
この課題を解決する手段として、「人工知能(AI : Artificial Intelligence)」や、その技術のひとつである「機械学習(ML:Machine Learning)」に注目が集まっています。
例えば、日本語の文書や音声でのやり取りなら、言葉の意味や文脈を理解しなければなりません。また、写真や動画であれば、そこにどのような情景が写っているか、誰が写っているかを解釈できなければ役に立ちません。さらには、誰と誰がどの程度親しいのか、商品やサービスについてどのような話題が交わされたのかといった意味を読み取り、それには何らかの対処が必要なのかといった解釈や判断を行わなくてはなりません。このようなことに「人工知能」が活躍するのです。
実用レベルに達した人工知能
「人工知能」は、かつて人間の経験や知見を整理したルールや判断基準を登録し、それに基づいて知的(に見える)作業をこなすやり方が主流でした。
しかし、昨今はビッグ・データを解析し、知的作業をおこなうためのルールや判断基準を作り出す「機械学習」という人工知能の技術を使ったやり方が主流となっています。
その背景には、「機械学習」に必要なコンピューターやストレージなどのハードウェアの劇的なコスト低下と高性能化、大規模なデータから効率よく規則性や特徴を見つけ出す「人間の脳活動を参考にした」計算方式(アルゴリズム)である「深層学習(Deep Learning)」が開発されたことがあります。
そのおかげで、画像認識や音声認識、翻訳などの分野では、十分に実用性を持つに至っています。
また、囲碁の世界チャンピオンに5番勝負を挑み打ち負かしたのも、そんなディープ・ラーニングの成果のひとつであり、特定の知的作業領域では人間の能力を超えるまでになっています。
人工知能の技術により、「ITがヒトに合わせる」つまり、ヒトに寄り添うITが普及する。
そんな人工知能の技術を使い、全体としての効率を落とすことなく、個々人や個別の事情に「最適化された答え(最適解)」を見つけ出すことができるようになります。それにより、
「ヒトがITにあわせる」のではなく、「ITがヒトに合わせる」つまり、ヒトに寄り添うITが普及する。
自ら状況を学習し、判断・行動する自動化や自律化の仕組みが、人間にしかできなかったことを代わりにやってくれる。
膨大なデータから見つけ出した規則性や関係性から、未来に何が起こるかを高い精度で予見できる。
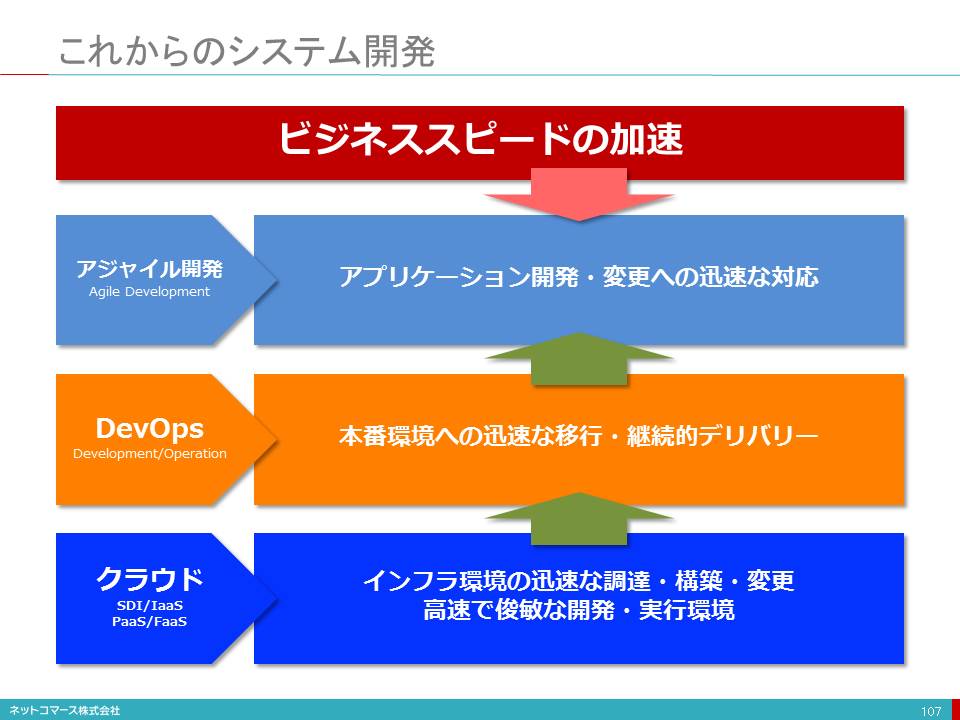
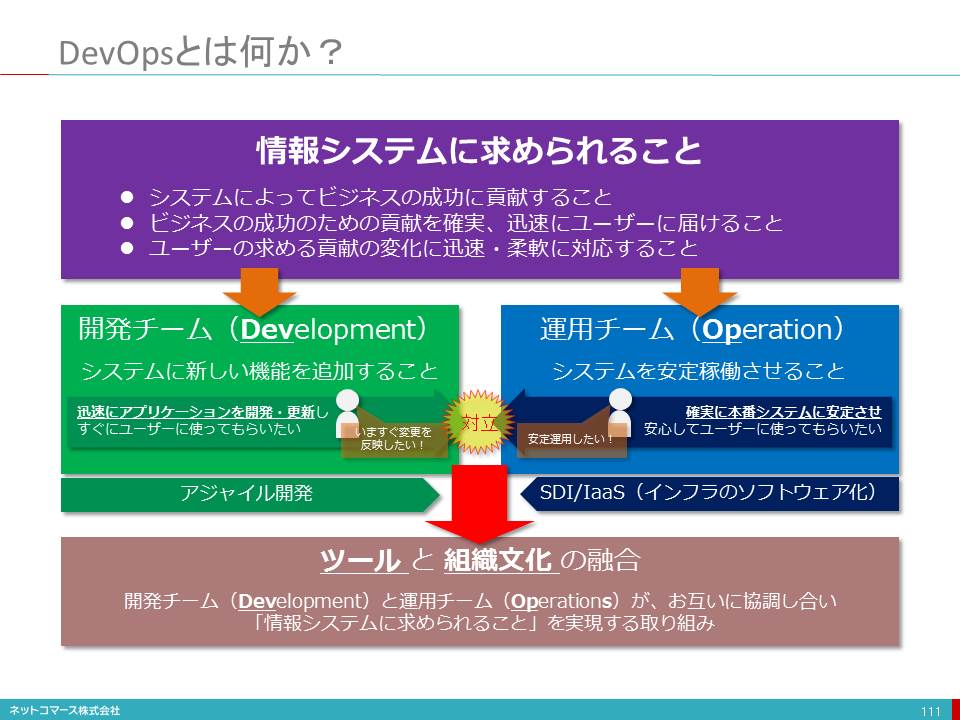
■ビジネス環境の変化に即応するためのDevOps
新たなビジネスの仕組み作りは、ヒトが役割を担う
インターネットでつながる世の中では、どこかで起きた出来事が、直ちに世界の隅々に知れ渡り、人々の行動やビジネス判断に影響を与えます。IoTやソーシャル・メディアは、その影響力をさらに増幅しています。
人工知能が、そんなビジネス環境の変化を受け取り、ある程度の柔軟性は担保してくれるかもしれません。しかし、変化に対応して新たなビジネスの仕組みを作り出すほどの能力はなく、そこはヒトが役割を担うことになります。
ビジネス環境の変化に即応できることが生き残りの条件
ビジネス環境が変化すれば、その変化に対応して新たなビジネス・プロセスを作らなければなりません。その変化のスピードは加速しています。そのスピードに即応できることが、生き残りの条件となるでしょう。
アジャイル開発や、「DevOps(DevelopmentとOperation)」が不可欠になる
そうなれば、これまでのようにハードウェアを購入してインフラを構築し、業務要件を洗い出し、仕様書を固めてプログラムを書いているようでは対応できません。
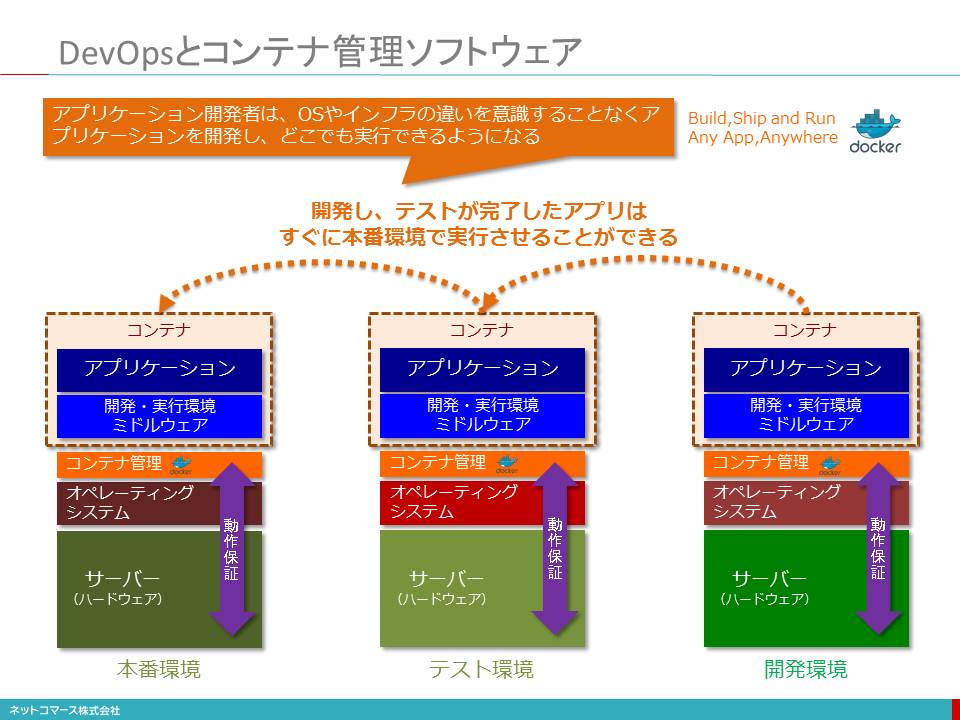
変化に即応し、変更変化にも柔軟に対応できるアジャイル開発や、開発したアプリケーションを直ちに本番環境で実行するための開発と運用の新たな取り組みである「DevOps(DevelopmentとOperation)」は不可欠となります。
DevOpsの実現を支えるのが、クラウドサービス
そうなると開発や運用はインフラの存在を意識していては、とても迅速で柔軟な対応は実現できません。
そこで、クラウドが提供するアプリケーション・サービス(SaaS:Software as a Service)やアプリケーションに必要となる機能モジュールや開発、実行環境を提供してくれるPaaS(Platform as a Service)といった、インフラを意識せず、その運用も必要としないサービスや、開発や運用の自動化を支援してくれるソフトウェアが、DevOpsの実現を支えてくれるようになります。
■サイバー・フィジカル・システム
IoTやソーシャル・メディアによって、現実世界の出来事はデジタル・データに変換されインターネットを介してクラウドに送り出されます。
デジタル・ツインが築かれていく
このデジタル・データを受け取り処理するクラウドやそこにつながる一連の仕組みは「サイバー世界と呼ばれ、現実世界の出来事や状態のデジタル・コピー、すなわち「デジタル・ツイン」が築かれてゆきます。
アナログな現実世界をデジタル・データで捉え、現実世界とITが一体となった社会変革を実現する仕組み
このように、アナログな現実世界をデジタル・データで捉え、現実世界とITが一体となった社会変革を実現する仕組みを「サイバー・フィジカル・システム(Cyber-Physical System)」と呼んでいます。
これからの社会基盤
インターネットにつながるモノの数は増加し、ソーシャル・メディアでのやり取りもますます盛んになってゆきます。そうなれば、データはさらに増え、きめ細かくなってゆき、より精度の高い現実世界のデジタル・ツインがサイバー世界に築かれてゆきます。それを使って、さらに正確な予測や最適な計画、アドバイスができるようになります。その情報を利用して現実世界が動けば、その変化は再びIoTやソーシャル・メディアによって取得されサイバー世界に送られます。いま、そんな仕組みが作られ、私たちの社会や生活の基盤になろうとしているのです。
■ヒトを前提としないビジネス・プロセスへの転換を模索するデジタル・トランスフォーメーション
サイバー・フィジカル・システムが、これまでの仕事のやり方や人と人のつながりを大きく変えようとしています。この変化を「デジタル・トランスフォーメーション(Digital Transformation)」と呼んでいます。トランスフォーメイションとは、形を変える、あるいは転換するという意味があります。では、いったい何をどのように転換するのでしょうか。
「人間が行うことを前提に最適化されたビジネス・プロセスから、機械が行うことを前提に最適化されたビジネス・プロセスへの転換」
ITの進化は、これまで「人間のできること」を機械に置き換え、効率化やコストの削減を実現してきました。さらに、インターネットやクラウド、IoTや人工知能の普及は、「人間にしかできなかったこと」や「人間にはできないこと」をどんどんできるようにしています。ならば、そんなITや機械の新しい常識を前提に、人間が行うのではなく、ITや機械が全てを行うことを前提に、それに最もふさわしい仕事の流れを実現してもいいはずです。
どうしても「人間にしかできないこと」が残るとすれば、それは人間がやりましょう
と、発想を逆転して考えてみると、これまでの常識では考えられなかったことが実現するかもしれません。これが、「デジタル・トランスフォーメーション」の目指しているところです。
この「デジタル・トランスフォーメーション」により仕事流れを変革し、「数割」ではなく「数倍/数十倍」もの変革を成し遂げようとしています。「デジタル・トランスフォーメーション」とは、こんな常識の大転換なのです。
「デジタル・ディスラプション(Digital Disruption)」
一方で、「デジタル・トランスフォーメーション」は、これまで人間が関わることを前提にしていた仕事の流れを、人間を介さずITだけで完結する仕組みに置き換えることで、既存の業界秩序や既得権益を破壊してしまう「デジタル・ディスラプション(Digital Disruption)」を生みだすことでも覚悟しなければなりません。また、ヒトと機械の役割分担も変えてゆかなければなりません。
■ITトレンドとこれからのビジネス
様々なテクノロジーは、それ自身が独立して存在しているわけではありません。それぞれに連携しながら、それぞれの役割を果たしています。私たちは、この一連のつながりを理解して、始めてテクノロジーがもたらす価値を理解することができるのです。
本書で紹介していることは、必ずしも全てが現時点で実現しているわけではありません。しかし、「トレンド=過去から現在を通り越して未来に向かう流れ」からみれば、近い将来必ず実現するものです。
ビジネスはITトレンドと切り離して考えることはできない
ビジネスはこのようなITトレンドと切り離して考えることはできません。冒頭でも説明したように、これまでの常識を大きく塗り替えるテクノロジーが重なり合い、影響を及ぼしあっています。この様相は、かつてとは明らかに異質な状況です。また、ITとビジネスが、これまでに無く深く結びついていることもかつてとは大きく異なることです。
これまでにないビジネスや生活のあり方、さらには新しい価値観や働き方が、生みだされつつある
例えば、これまでITは業務の生産性や効率を高める手段として主に使われてきましたが、いまはそれだけではなく「ITを活かして新たなビジネスを創る」ことへと役割を拡げつつあります。そしてこれまでにないビジネスや生活のあり方、さらには新しい価値観や働き方が、生みだされつつあるのです。
そんな現実を過去から現在、そして未来につながる一連の物語として捉えることです。辞書の解説のように言葉の綴りを暗記しても、意味や価値は分かりません。
ビジネスとテクノロジーのキーワードを当てはめてみる
ITトレンドを大きな物語として捉え、そこに自分たちのビジネスやテクノロジーのキーワードを当てはめて考えてみることが、ITトレンドを理解することであり、ビジネスに役に立てることができるのです。
第1章 IoT
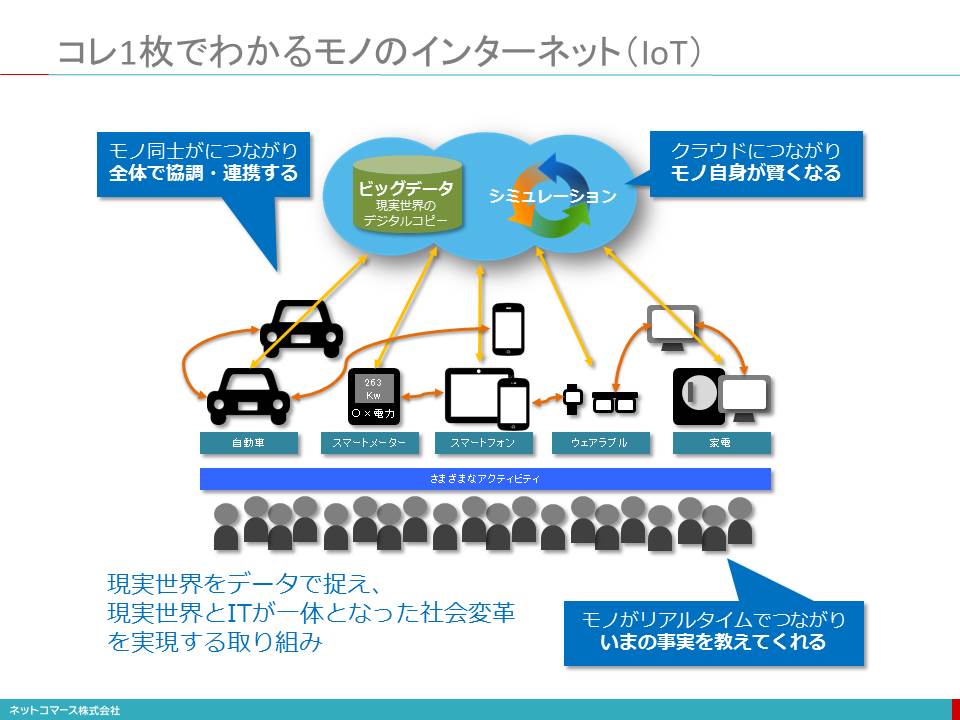
コレ1枚でわかるモノのインターネット(IoT)
■■■■モノ同士がつながり全体で協調・連携する
前を走っている自動車がスピードを落とせば、後方の自動車もそれにあわせてスピードを落とします。自動車と信号機がつながり、通行量に応じて信号機の点灯を制御しますのでもっとスムーズな走行ができます。その結果、渋滞は解消され、無駄なガソリンの消費も抑えられ、環境にやさしい輸送が実現します。
このように、モノ同士がつながることでモノがお互いに協調・連携しながら、全体最適を実現してくれるのです。
■■■■クラウドにつながりモノ自身が賢くなる
電子レンジはクラウド・サービスからいま話題の料理のレシピを手に入れ最適な時間や調理法を設定してくれます。
冷蔵庫は少なくなった常備食材を検知して自動で発注してくれます。
自動車に今日食べたい料理を話しかけるとおすすめのレストランを紹介し予約までしくれます。そして渋滞のない快適なルートに沿って自動車を走らせてくれるでしょう。
ひとつひとつのモノに大きなデータや頭脳を持たせることには限界がありますが、モノにつながったインターネットの先には、ほぼ無尽蔵のデータ格納場所であり膨大な処理能力を持った頭脳であるクラウドがあります。モノは、このクラウドにデータを送り様々なデータ処理を行うことで、モノ単体ではなしえない強力な頭脳を持つことができるのです。
■■■■モノがリアルタイムでつながり、いまの事実を伝えてくれる
航空機のジェット・エンジンの稼働状況がリアルタイムに分かることで、故障や不具合を即座に把握できパイロットに適切な指示を与えることや、着陸先の空港で交換部品やエンジニアを事前に待機させておき、着陸後すぐに点検修理して次のフライトを欠航させないといった対応ができます。
そのときの道路の混み具合や今後の渋滞予測に応じて、自分の乗っている自動車を最適なルートに誘導してくれます。
災害が起きたとき、スマートフォンやウェアラブルを持っている人の動きをリアルタイムで捉えながら、安全な避難経路へと誘導してくれます。
このようにモノがリアルタイムにつながることで、これまでとは大きく異なるビジネス・モデルの実現します。
IoTの2つの意味
1つは、「現実世界の出来事をデジタルデータに変換し、ネットに送り出す機器や仕組み」
もう一つは、「デジタルデータで現実世界を捉え、アナログな現実世界を動かす仕組み」
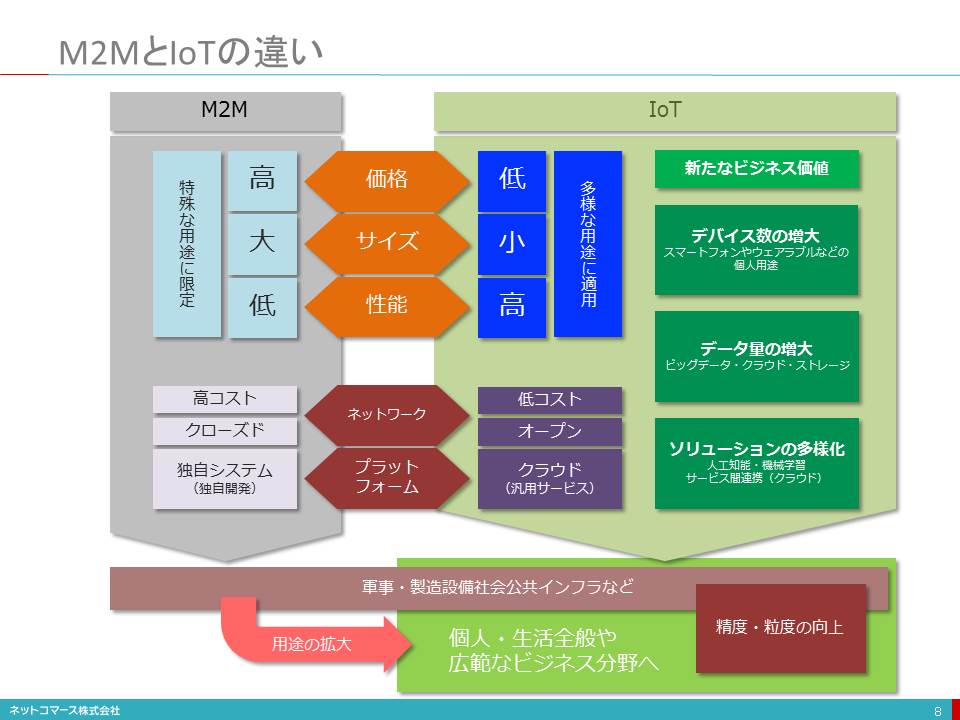
M2MとIoTの違い
【図解】コレ一枚で分かるM2MとIoTの違い
モノにセンサーを組み込み、データを収集し監視するという仕組みはIoTという言葉が登場する遙か以前からありました。1964年に開通した新幹線、1974年に運用が始まった「地域気象観測システム:アメダス」、1970年代に始まった生産設備の自動化などでも、同様の仕組みが使われていました。しかし、それらはどれも特定の業務目的に特化した仕組みで、他のサービスで再利用されるといったことは想定されていませんでした。このような仕組みは、やがてM2M (エム・ツー・エム:Machine to Machine)と呼ばれるようになります。
その後、センサーやコンピューターの小型・高性能化、低価格化が進み、通信も高速・高性能化とともに料金が大幅に下がりました。また、インターネットやクラウドの普及とともに、M2Mの適用領域は大きく拡がります。そして、様々な「モノ」がインターネットに接続され、さらにはモノ同士がお互いにつながるようになり、IoT(アイ・オー・ティー:Internet of Things)という用語がM2Mに置き換わるように広く使われるようになりました。
「IoT」という用語は、1999年に無線ICタグの専門家であるケビン・アシュトンが初めて使ったとされています。彼は、当初は無線ICタグを使った商品管理システムをインターネットに例えて使っていたようですが、商品だけではなく様々なモノをインターネットにつなぐ概念として、その後転用されたと言われています。
IoTがかつてのM2Mと本質的に違うのは、センサーを搭載した機械やモノの数が桁違いに多いことに加え、インターネットやクラウドというオープンな仕組みの上で使われ、自社以外の企業ともつながり、新たな組合せを生みだすことができることです。例えば、
あなたが持っているスマートフォンのGPSを使えば自分の位置が分かります。そんなGPSのデータを大量に集め、その移動時間やルートを解析することで、地図上に「道路の渋滞状況」を表示させることができます。
自動車に組み込まれたセンサーによって運転手の運転の仕方を分析し、運転手ごとに省エネ運転や安全運転のアドバイスを行うことができます。さらにそのデータを保険会社と共有することで、安全運転をしている運転手の保険料を割り引く自動車保険が登場しています。
損保会社は、気象情報企業が集めた気象データを用いることで、将来における住宅や設備の損害請求を予測し、悪天候や災害が起こるリスクや影響を地域ごとに定量化することができます。そのリスク情報に基づいて、契約者個別の保険内容を組むことや財務上のリスクを減らすための取り組みができるようになります。 また、天候の悪化が予想される地域を走行しているドライバーにスマートフォンから注意を促し、近辺のスターバックスでやり過ごすように促し、そのための割引クーポンを発行できるようになります。それによって、事故を未然に防ぎ保険料の支払いを減らすことができます。
データで様々なサービスがつながることで、IoTはビジネスに新しい組合せを生みだすエコシステムを築きます。それが、これまでには無かった便利で効率のよいサービスや社会システムを登場させる基盤となるのです。
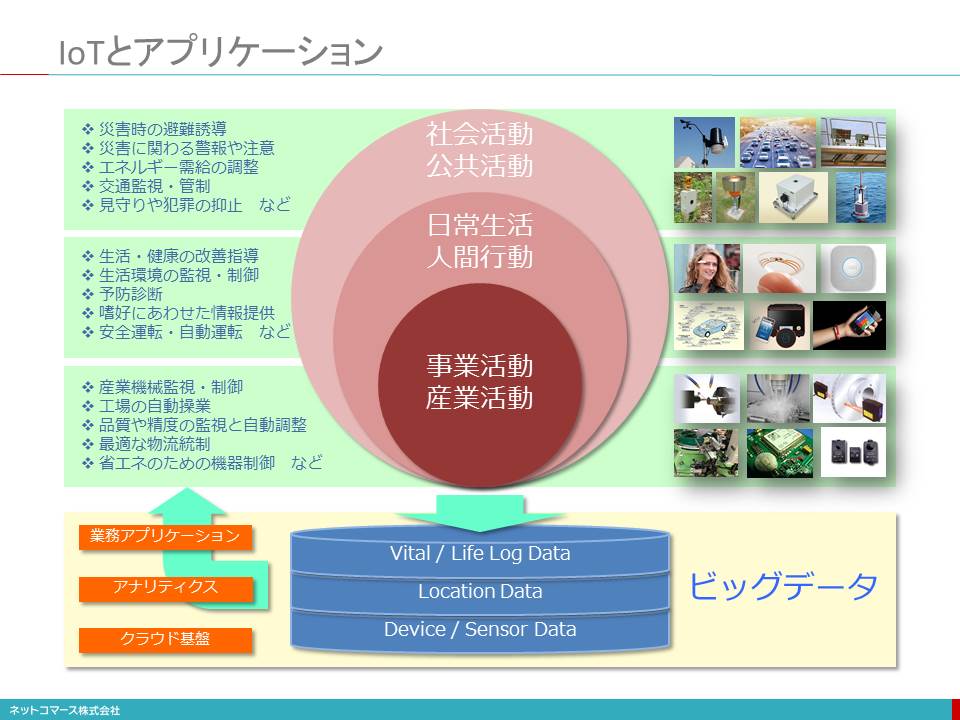
IoTとアプリケーション
【図解】コレ1枚でわかるIoTアプリケーション
IoTは、私たちの日常生活や社会活動といったアナログな現実世界の出来事をデジタル・データに置き換え、インターネットを介してクラウドに集めてゆきます。IoTの普及・拡大により、そのデータ量はどんどん増加してゆくでしょう。そんなビッグデータをただ溜め込んでいても意味がありません。それを統計的な手法や人工知能を使い、解析・解釈することですることで、そのデータに潜む規則性や関係性、データ相互のつながりや構造を見つけ出し、様々なアプリケーションで使われるようになります。
社会活動・公共活動
【データ発生源】建物、公共設備、気象、環境、交通機関、道路など
【データ】振動、ゆがみ、交通量、騒音、気温、湿度、風向、水量など
【価値や便益】災害時避難誘導・災害に関わる警報や注意・エネルギー需給調整・交通監視・管制・見守りや犯罪の抑止など
日常生活・人間活動
【データ発生源】ウェアラブル・デバイス、センサー内蔵のホームスタットや家電製品、自動車、衣服や靴、携帯品など
【データ】体温や脈拍、発汗、人の動き、室温や湿度、涙や汗の成分、位置情報、車載機器の状況など
【価値や便益】生活・健康の改善指導、生活環境の監視・制御、予防診断、個人の嗜好にあわせた情報提供、安全運転・自動運転など
事業活動・産業活動
【データ発生源】工作機械やロボットに組み込まれる様々なセンサーや計測装置など
【データ】距離、高度、位置、温度、流量、確度、加速度、加重、光度など
【価値や便益】産業機械監視・制御、工場の自動操業、品質や精度の監視と自動調整、最適物流統制、省エネのための機器制御など
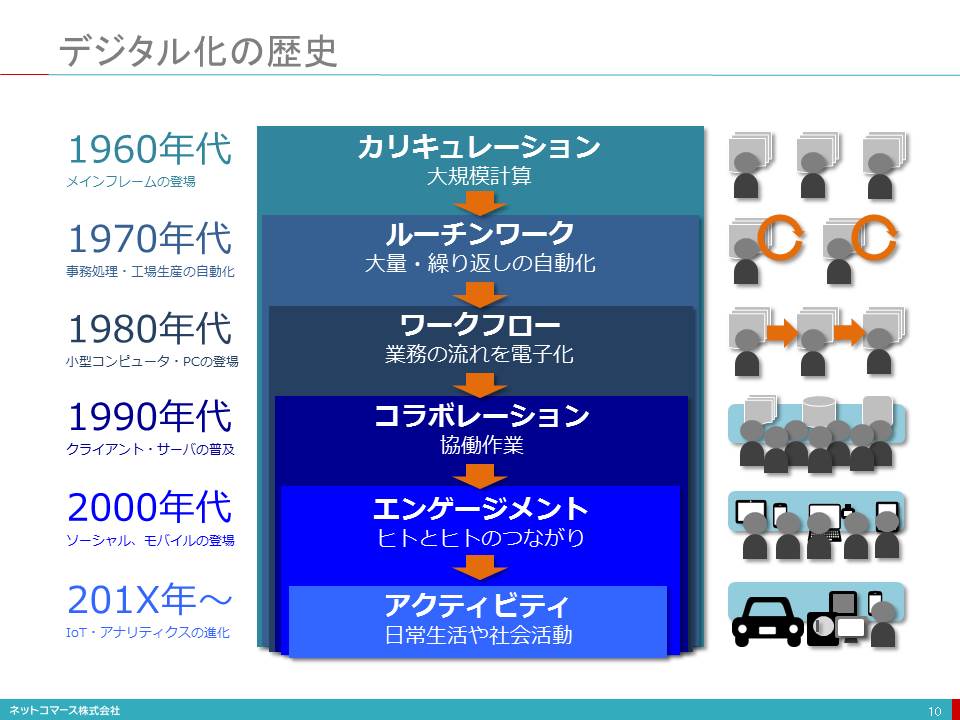
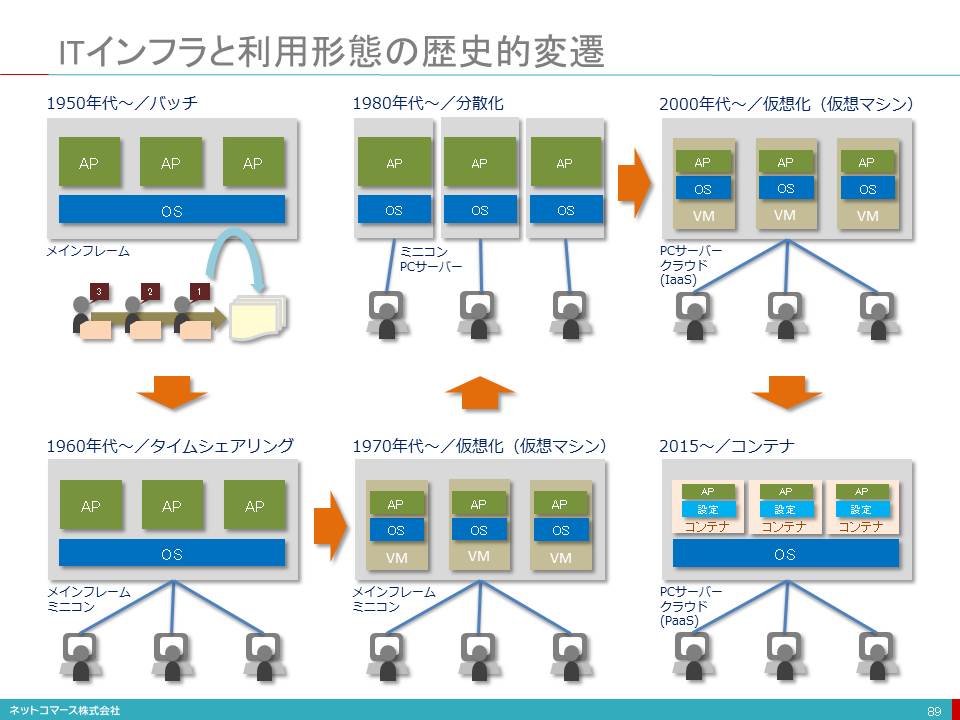
デジタル化の歴史
1950年代
1950年代、コンピュータがビジネスで使われるようになりました。1964年、いまで言うメインフレームの前身であるIBM システム/360が登場し、ビジネス・コンピューターの需要が一気に拡大します。そして、大規模な計算業務のデジタル化が始まりました。
1970年代
1970年代、コンピュータの用途はさらに広がります。伝票の発行や経理処理、生産現場での繰り返し作業など、定型化された繰り返し業務(ルーチンワーク)がコンピュータによって処理される時代になったのです。
1980年代
1980年代、小型コンピュータやPCの登場により、コンピュータは多くの企業に広く行き渡ります。また、企業内にネットワークが引かれ、個人や部門を越えた伝票業務の流れ(ワークフロー)がコンピュータに取り込まれデジタル化されるようになりました。
1990年代
1990年代に入り、PCは一人一台の時代を迎えます。そして、電子メールが使われるようになり、文書や帳票の作成をPCでこなし、それらを共有する需要も生まれました。そんな時代を背景にグループウェアが登場し、共同作業(コラボレーション)のデジタル化がすすんでゆきました。インターネットも登場し、コラボレーションはさらに広がりを見せ始めます。
2000年代
2000年代に入り、FacebookやTwitterといったソーシャルメディアが登場します。また、2007年のiPhoneの登場により、誰もが常時ネットにつながる時代を迎え、ヒトとヒトのつながり(エンゲージメント)が、デジタル化される時代を迎えます。
そして、いま
そして、いまIoTの時代を迎えようとしています。モノが直接ネットにつながり、モノやヒトの状態や活動がデータとして集められ、ネットに送り出される仕組みが出来上がりつつあります。私たちの日常生活や社会活動に伴う全てのアクティビティがデジタル化されようとしているのです。
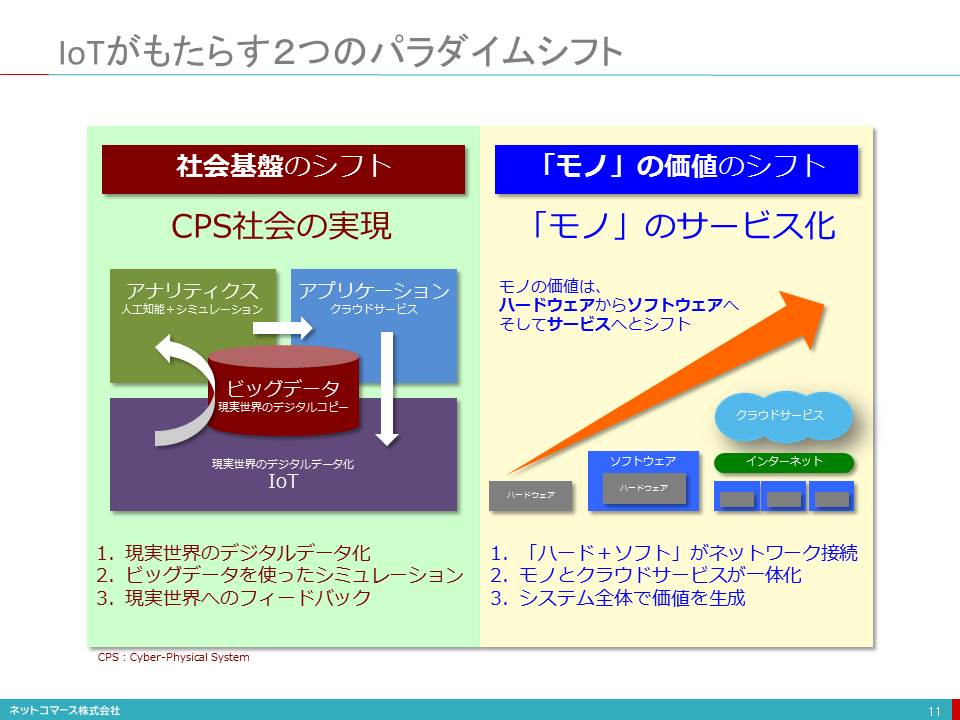
IoTがもたらす2つのパラダイムシフト
【図解】コレ1枚でわかるIoTがもたらす2つのパラダイムシフト
IoT(Internet of Things)は、既存の常識をどのように変えようとしているのでしょうか。
社会基盤のシフト
IoTがもたらす常識の転換(パラダイムシフト)のひとつは、現実世界(Physical World)と電脳世界(Cyber World)を一体化させた新たな社会基盤の実現です。
スマートフォンやウェアラブル端末、車や建物、公共交通機関や道路・公共施設などに組み込まれたセンサーによって、私たちの生活や社会の出来事は、デジタルデータとして収集され、インターネットに送り出されます。
このようなネットワークにつながるデバイスの数は、2015年の180億個から2020年には500億個に達すると言われており、これによって現実社会が、より緻密に、そしてリアルタイムにデータ化され、電脳世界に、そのデジタルコピーを作り上げる仕組みが構築されようとしています。
このデジタルコピーを使って、様々なシミュレーションや人工知能を使った解析を行い、現実社会の出来事を深く理解し、様々な洞察や最適解を導き出すことができるようになります。この結果は、様々な業務サービスや情報提供サービスを介して、現実世界に再びフィードバックされ、新たな活動や変化をもたらします。そして、その動きは、センサーに収集され、また電脳世界に送られます。
このような一連の仕組みをCyber-Physical System(CPS)と言います。
CPSは、日常生活や社会活動の様々な領域に組み込まれ、これまでにできなかったような新たな価値を生みだしてゆくことになるでしょう。
「モノ」の価値のシフト
もうひとつのパラダイムシフトは、「モノ」の価値の本質をハードウェアからサービスへとシフトさせることです。
かつて、モノの性能や機能、品質や操作性は、ハードウェアの「メカニズム」や「作り込み」といった物理的実態によって実現されました。しかし、いま多くのモノには、コンピューターが組み込まれ、ソフトウェアによって、これらが実現されています。もちろん、ハードウェアの価値が失われることはありませんが、もはやハードウェアだけでは、モノ全体の価値を実現できない時代を迎えています。
IoTの登場は、この「ハードウェア+ソフトウェア」としてのモノをインターネットにつなぎ、クラウドと一体化することで、これまでにはできなかったサービスを実現しようとしています。
例えば、自動車や設備機器に組み込まれたセンサーが、クラウドサービスに送られ解析され、予防保守の必要性やタイミングを個別に判断し、故障で動かなくなる前に点検や修理を行うことを可能にします。これにより、ユーザーの満足度は高まり、さらに保守・点検のタイミングや、そこに関わる機材や部品、エンジニアの稼働が個別最適化され、サービス・コストの削減が可能になるでしょう。
また、稼働状況がリアルタイムで確実に計測できることから、「モノ」を売らずに、タクシー料金のように使用量に応じて課金するといった「サービスとしてモノ」を提供するビジネスも可能になります。
自動車の場合、運転者が安全な運転をしているのか、乱暴な運転をしているのかを把握し、保険料率を変動させるといったサービスも考えられます。さらに、ネットワークを介して、モノに組み込まれたソフトウェアを更新し、機能や性能、操作性を向上させることも可能になります。
このように、モノそのものではなく、モノを含むサービス全体が新たな価値を生みだすことになろうとしているのです。
この2つのパラダイムシフトが、私たちの生活や社会活動、そしてビジネスを大きく変えてゆくことになるでしょう。
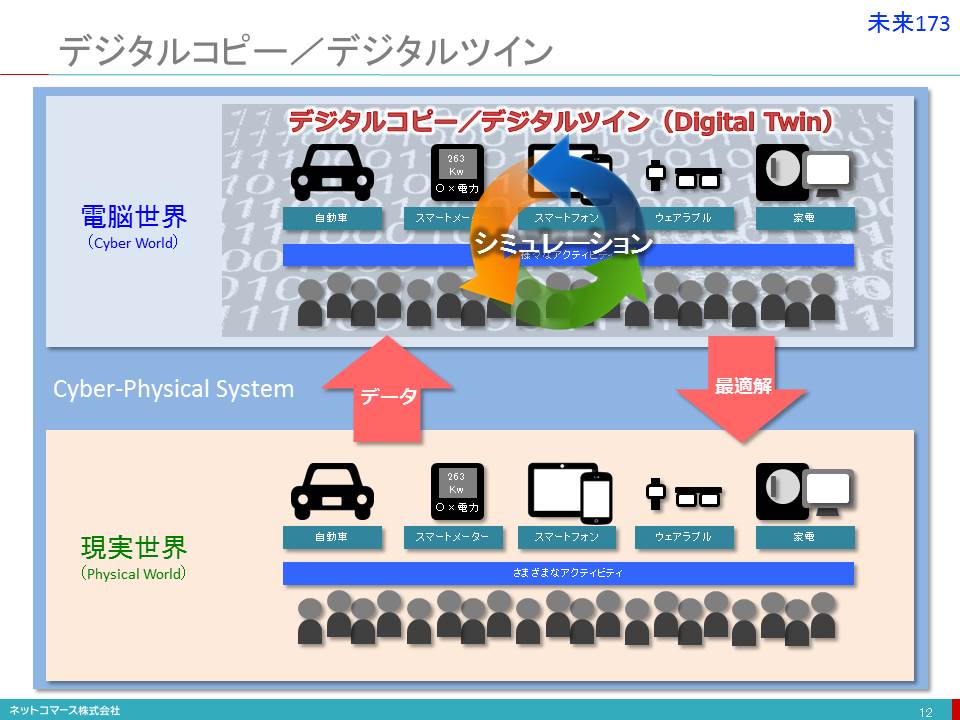
デジタルコピー/デジタルツイン
【図解】コレ1枚でわかるCPSの仕組み
IoT(Internet of Things:モノのインターネット)は、私たちの住む現実世界の出来事をデジタル・データに変換し、ネットの世界(Cyber World:電脳世界)に送り出す仕掛けです。そんなIoTが普及すれば、私たちの日常生活や社会活動は、きめ細かくリアルタイムにデジタル・データ化されることになります。
IoTを支えるインターネットにつながるモノの数は、2020年には500億個、そのわずか5年後の2025年には2兆個にもなると言われ、そのときには一人当たり250個ものインターネットにつながるモノに私たちは取り囲まれる計算になるのです。つまり、私たちの住む現実世界(Physical World)の緻密でリアルタイムなデジタル・コピーが電脳世界に出来上がる、そんな時代を迎えようとしているのです。
このような現実世界のデジタル・コピーを持つことの価値は、それを使った様々な実験(シミュレーション)を電脳世界で行えることにあります。例えば、自動車や鉄道の交通網やそれを利用する人々の動きのデジタル・コピーを使い、そこに大地震や大津波が襲ってきたことを想定して、様々な実験を行うことができます。例えば、大津波で沿岸部の道路が寸断され、都心部ではビル火災が起きて道路が通行できなくなります。また、鉄道は停まりターミナル駅に人があふれてしまいます。そんな世界をいろいろと条件を変えて再現し、そのときにどのように対処すれば一番被害を減らすことができるのかをいろいろな確度から検証することが可能になり、防災・減災に役立てることができるのです。このような実験を現実社会で行うことは決してできません。
また、ウェアラブル・デバイスを持つ数千万人あるいは数億人の身体状況や行動のデータを様々な角度から分析し、病気を起こす可能性の高い生活習慣を見つけ出し、生活習慣の改善や予防措置を促すことができれば、大きな国家財政負担になっている医療費を削減することにつながります。
このような現実世界と電脳世界が、デジタル・データでつながり、一体となって機能する仕組みがサイバーフィジカル・システム(Cyber Physical System/CPS)です。
ところで、電脳世界に構築されるこのデジタル・コピーですが、現実世界に存在するモノやヒトと根本的に異なる特徴があります。それは、物理的・地理的な障壁が存在しないことです。
例えば、私たちの住む現実世界では、自分の肉体を瞬時に数千キロ離れた別の場所に移動させることはできません。また、モノに直接触れなければ、それを使うことはできません。また、時間を巻き戻してやり直すことも未来の世界でいろいろと試してみることもできないのです。しかし、物理的実態のない電脳世界ではその制約はありません。物理的、時間的、地理的な制約故に実現できない仕事の流れも電脳世界では実現できるのです。
このようにデジタル・データによって構築される電脳世界においては、現実世界では実現できなかった仕事の流れを作り出すことができます。例えば、多くの自動車の利用状況がリアルタイムに電脳世界に開示されていれば、必要な時に誰もが自動車の空き時間を把握でき自動車を協同で利用することも可能になるでしょう。また、仲介者を介することなく世界中と様々な取引をすることもできます。このような仕組みは、ヒトやモノが物理的、地理的に固定されている現実世界だけではなしえないことなのです。
「既存の仕事の仕組みをデジタルで組み替え、新たな価値を生みだす」
効率化だけではない新たな価値を生みだすこのような取り組みは、「デジタル・トランスフォーメーション」と呼ばれています。CPSによってますますこのデジタル・トランスフォーメーションが拡がってゆくことになるのです。
モノのサービス化(1)
IoTは「モノ」の価値をハードウェアからサービスへとシフトさせようとしています。
かつてモノの性能や機能、品質や操作性は、ハードウェアの「細工」や「材料」によって物理的に実現していました。しかし、いま多くのモノには、コンピューターが組み込まれ、ソフトウェアによってこれらが実現しています。もちろん、ハードウェアの価値が失われることはありませんが、ハードウェアだけでは機能や性能を生みだせない時代を迎えています。
例えば、以前のカメラは、露出、ピント、絞り、シャッター・スピード、感度、発色などは、ハードウェアであるギアやカムなどの機械部品の細工やフイルムに塗布する感光剤の性能などによって実現していました。しかし、最近のデジタルカメラは、そこに組み込まれたソフトウェアによってこれらを実現しています。
いまでもハードウェアは、モノの価値を決める要素であることに変わりはありませんが、それは全体の一部に過ぎません。むしろソフトウェアの機能や性能が、モノの価値を実現する上で大きな役割を占めるようになりました。
この「ハードウェア+ソフトウェア」で構成された「モノ」がネットワークにつながれば、モノの価値の本質はサービスへとシフトします。例えば、
デジタルカメラをインターネットにつないで、ソフトウェアを更新すれば、連写機能を向上させたり、アートフィルターの種類を増やしたりと、買ったときよりも高機能なものに変えてくれます。
米国の電気自動車テスラのモデルS/Dシリーズには、ハードウェアに自動運転機能が組み込まれています。いまは法律上の規制もあって完全な自動運転はできませんが、法律が整えばソフトウェアの更新によって完全な自律走行ができるようになるということです。
AppleのiPodは、楽曲ダウンロード・サービスのiTunes Music Storeや定額聴き放題サービスのApple Musicというクラウド・サービスと一体となって提供されるからこそ、人気を博しているのです。
このように、モノがネットワークにつながることで、モノは購入した後も継続的に機能を向上させ進化し続けます。「モノ」は、それを作り、出荷することで完結するのではなく、作られたモノとその後のサービスが一体となって、モノの価値を生みだし続けるのです。
また、IoTは稼働状況をリアルタイムで確実に計測できるしくみでもあります。これにより、「モノ」を売らずに、タクシー料金のように使用量に応じて課金するといった「サービスとしてモノ」を提供するビジネスができるようになります。例えば、先に紹介した航空機用のジェット・エンジンを製造・販売する英ロールスロイスは、エンジンという「モノ」を販売するのではなく、実際に使用した時間と出力の積に応じて、エンジンの利用者である航空会社に利用量を請求する「Power by the Hour」というサービスを提供しています。エンジンに組み込まれたセンサーが、エンジンの使用状況や各部品の消耗具合、不具合などを検知し、ネットを経由してそのデータを送ります。そのデータは解析され、修理・点検の必要性やタイミングを個別に判断し、故障で動かなくなる前に対応できるようになります。これにより、より安全な運行が実現し、機材の稼働率が上がることでユーザーの満足度は高まります。さらに保守・点検のタイミングや必要な部品の在庫、エンジニアの稼働が最適化されることから、サービス・コストの削減が可能になります。他にも
自動車で運転者が安全な運転をしているのか乱暴な運転をしているのかをセンサーで捉え保険料率を変動させる自動車損害保険
エレベーターやエスカレーターに組み込まれたセンサーから集められたデータから故障の予兆を見つけ出し故障する前に修理点検を行う保守サービス
農業用ハウスに組み込まれたセンサーで土壌の成分やハウス内の温度や湿度、二酸化炭素の濃度を把握し、生育状況に応じてそれらを自動で調整してくれる植物工場
なども実現しています。
このように、モノそのものではなく、モノを含むサービス全体が新たな価値を生みだす時代を向かえようとしています。
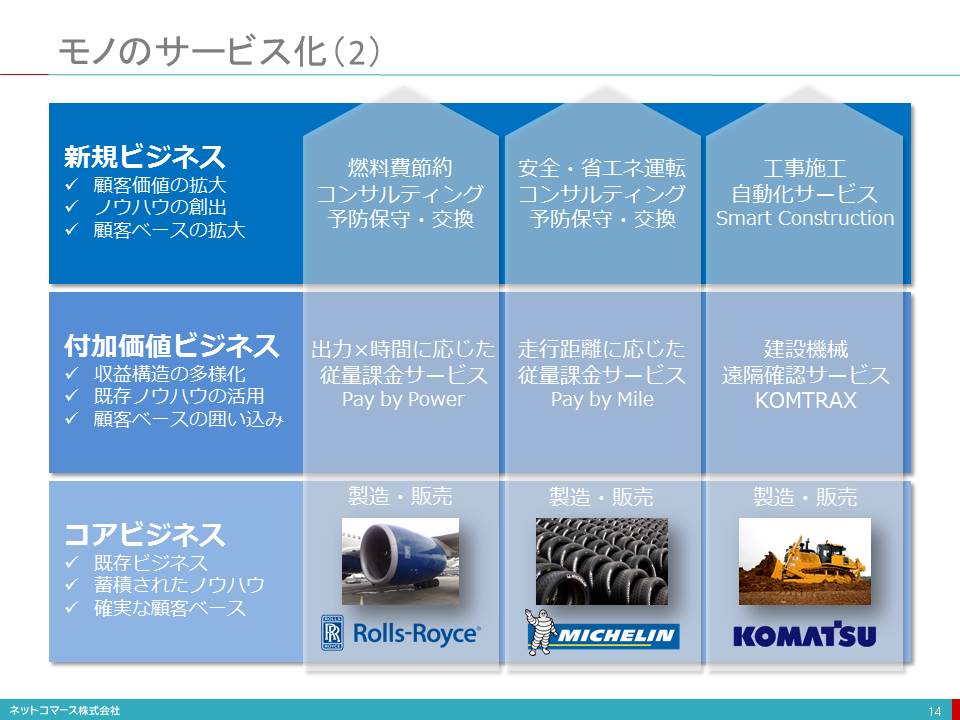
モノのサービス化(2)
タイヤを売らないタイヤメーカー、建設機械を売らない建築機械メーカー、ジェット・エンジンを売らないジェット・エンジン・メーカー。これまでの常識では考えられないビジネスが登場しています。
仏タイヤメーカーのミシュランは、運送会社向けに走行距離に応じてタイヤの利用料金を請求するビジネスをはじめています。さらに、燃料を節約できる走行方法のアドバイスを、インターネットを介して運転手に提供したり、省エネ運転の研修を行ったりと、これまでのタイヤメーカーではあり得なかったビジネスに踏み出しています。このサービスによって運送会社は投資を抑えることができるばかりでなく運行コストも削減でき、経営体質強化に貢献することができます。
建設機械大手のコマツは、無人ヘリコプターのドローンで建設現場を測量し、そのデータと設計データ使って建設機械を自動運転し工事をするサービスを提供しています。これまで熟練者に頼っていた精密な測量や難しい工事を経験の浅い作業員でもこなすことができ、人手不足に悩む業界にとっては大きな助けとなっています。
世界三大ジェット・エンジン・メーカーの一社である英ロールスロイスは、ジェット・エンジンを販売するのではなく、ガス料金や水道料金のように、使用した出力と時間に応じて課金するビジネス「Power by the Hour」をはじめています。このサービスによって、顧客である航空会社はジェット・エンジンを購入する必要はなくなり、旅客が料金を支払ってくれるときだけ使用料を支払えばいいので大助かりです。このようなことが可能になったのは、ジェット・エンジンの稼働データをセンサーと衛星回線を使って確実に把握できるようになったからです。このデータは料金支払いのためだけではなく、エンジンの状態を把握することにも役立ち、故障や事故が起こる前に不具合の予兆を発見し、事前に点検や保守作業をおこなうことができます。そのおかげで欠航を減らすことができれば、お客様である航空会社に安定した収益をもたらし、顧客の信頼を確かなものにしてくれます。また、データを分析することで燃費を向上させる操縦方法や航路のアドバイスもできるようになり、コンサルティング・ビジネスという新規事業にも参入しています。サービスを提供するロールスロイスも点検の回数を減らすことができ、余計な部品在庫を抱える必要もなくなり、コスト削減に大いに貢献しています。両者にとって、Win-Win(双方にとって好都合なこと)の関係を築くことができます。
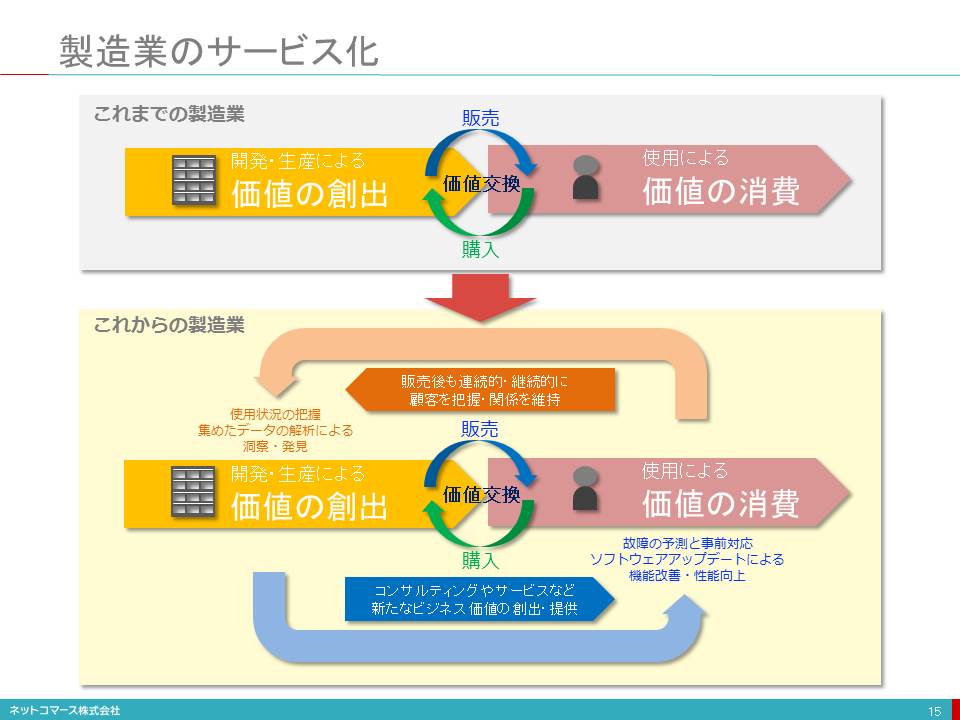
製造業のサービス化
これらを可能にしているのは、タイヤや建設機械、ジェット・エンジンに組み込まれたセンサーやGPSがそれぞれの稼働状況や位置をリアルタイムで捉えることができるようになったからです。そのデータは、携帯電話回線や衛星通信を使ってサービス提供企業の情報システムに送られ分析されます。そして、適切な判断やアドバイス、機器の制御が自動的におこなわれる仕組みができているのです。
ここに紹介した製品だけを見れば、どれも昔から使われているものです。そのため、長い競争の末に機能や性能ではどれも完成度が高くなり、「どれを買っても同じ」と言えるくらい差別化の難しい製品となってしまいました。そのような中で、各社は利用者の利便性や求める価値を改めて問い直し、「モノをサービスとして提供する」という方法で、新しい魅力を生みだし、競合他社との差別化を図ろうとしています。
「モノを売るのではなく、成果を売る」
そう言い換えてもいいかもしれません。もはや製造業はよいモノを作るだけでは勝ち残れない時代となり、これまでの「故障すれば駆けつけて修理する」といった顧客との関係だけでは差別化は難しくなりました。そこで、付帯業務も含めた業務の代行やデータ解析による故障予知などを長期かつ包括的な契約で提供することで、
顧客のダウンタイムを最小化する
顧客の経費を削減する
顧客の人手不足を解消する
など「顧客の成果に直接貢献する」サービスへとビジネスのあり方を変えようとしているのです。
「モノのサービス化」と言われるこの動きは、モノに組み込まれたセンサーによってモノの状態をデータ化し、インターネットに送り出す仕組みであるIoT(モノのインターネット:Internet of Things)とよばれる技術が土台となっており、今後も大きな広がりが期待されています。
「作って売ってしまえば終わり」のこれまでの常識から、「売ってからも継続的に関係を持ち続ける」という新しいしこれからの常識へと製造業は大きく変わろうとしています。
ガソリン自動車と電気自動車
自動車業界が、GoogleやApple、Microsoftそして新興の電気自動車メーカーTeslaといった企業に戦々恐々としています。その背景には、電気自動車の普及と自動車のソフトウエア化があります。
まず電気自動車(EV)ですが、エンジン自動車に比べ圧倒的に部品点数か少なくなります。また、部品の種類も複雑な機構を組み合わせた機械部品から比較的構造が単純な電気・電子部品が中心となり、機械加工や組み立てノウハウの蓄積がない企業でも参入が容易になります。米Teslaや日本のGMLなどのEVベンチャー企業が参入できるのもこのような背景があるからです。
また、車の機能や性能の多くがソフトウエアに依存するようになります。これは、エンジン自動車でも言えることですが、電気自動車になれば、その割合はさらに高まり、ソフトウエアの開発力が製品の競争力になると考えられます。
GoogleやApple、Microsoftは、このソフトウエアを様々な車で利用できるプラットフォーム=車載OSとして提供しようと動き始めています。例えば、GoogleのAndroid AutoやAppleのCar Play、MicrosoftのMicrosoft Autoは、いまでこそカーナビやテレマティクスの機能に限定されていますが、やがて自動運転機能を提供し、自動車の走行をも制御する車載OSへと進化してゆくでしょう。
もし車載OSで覇権を握られれば、Windowsがコンピューターで、Androidがスマートフォンでそうであったようにハードウェアはコモディティ化・汎用化し、既存の自動車メーカーが長年蓄積してきた独自の製品開発力、機械加工や組み立てなどの競争力の源泉を失ってしまうことになります。
半導体メーカーの米NVIDIAはこのような動きを背景に、自動運転をも視野に入れた車載SoC(System On A Chip、1チップでコンピューターの機能をすべて統合しているチップのこと)を提供しはじめており、他の半導体メーカーや電子機器メーカーも同様に汎用部品提供の動きを展開しつつあります。
このようなソフトウエア企業の動きに対し、自動車メーカーや車載機器・半導体メーカーが主導する形でオープンな車載OSとしてAGL(Automotive Grade Linux:オートモーティブ・グレード・リナックス)を開発しようという取り組みも始まっています。これは、Linuxをベースとした車載OSで、高度安全支援や自動運転を視野に入れて開発が進められています。
また、自動車はコネクテッド・カーとしてインターネットにつながり、車載OSとクラウド・サービスとの連携を実現し、車両単独ではできない機能やサービスを提供できるようになり、自動車のあり方や価値を大きく変えてゆくと考えられます。
米カリフォルニア州は、ZEV(Zero Emission Vehicle)規制を定め、州内で一定台数以上自動車を販売するメーカーは、その販売台数の一定比率を、排出ガスを一切出さない電気自動車や燃料電池車にしなければならないと定めています。ただし、電気自動車や燃料電池車のみで規制をクリアすることは難しいため、プラグインハイブリッドカー(ハイブリッドカーは除外)、天然ガス車、電気自動車などのクリーンな車両などを組み入れることも許容されています。このような動きは世界にも拡がりつつあり、電気自動車は今後大きな普及が期待されています。
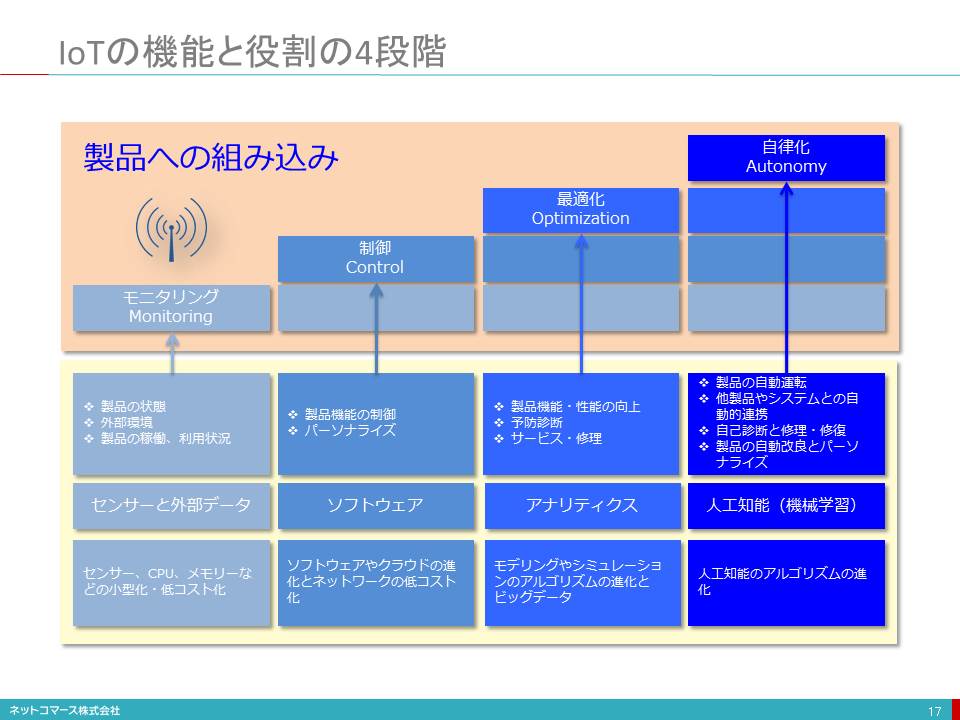
IoTの機能と役割の4段階
【図解】コレ1枚で分かるIoTの機能と役割の4段階
IoT(Internet of Things)の機能や役割には、その特性に応じた4つの段階があります。
監視
センサーを使って、モノそのものや周囲について、状況や変化を監視することができます。ここで得られるデータは遠隔地からの機器の監視、マーケティングや製品設計のためのデータの収集などに役立てることができます。例えば医療機器の状況を常に監視し続けたり、建設機械の稼働状況などを常に把握したりすることができ、故障や不具合が生じたら直ちにサービス員を急行させるなどの迅速な対処ができるようになります。
制御
通信を介して外部から制御できます。ソフトウェアによってモノの状況や周囲の環境が変化すれば、それに応じて指示を出し、自動で動作させることも可能です。例えば、人が玄関に近づくとセンサーがその動きを感知し監視カメラを起動、その映像をスマートフォンに送ることができます。それを見て玄関の鍵を開いたり、不在であれば遠隔地から音声で応対したりといったことができるようになります。また、家に帰る前にスマートフォンからエアコンのスイッチを入れておくこともできます。
最適化
監視機能と制御機能を組み合わせることで、モノの状態や動きを最適名状態に保つことができます。そのためには、モノに組み込まれたセンサーにより取得・蓄積されたデータをソフトウェアで解析し最適な状態を導き、その状態になるようにモノを制御します。例えば、風力発電では、風力や風向きに応じて、最も発電効果が高くなるようにて風車のブレードの確度を調節することができます。
自律化
モノ自身や周囲の状況や変化を継続的に監視し、その時々の最適な状態をリアルタイムで判断し、モノを自動で制御することができます。また、お互いを通信機能で連係させることで、それぞれの状況を共有し全体として最適な動作をさせるように協調制御することもできます。例えば、部屋の形状や家具の配置、床の汚れ具合を探りながら部屋を清掃するロボット、周囲の道路状況や走行車両、人の動きや標識などの変化をリアルタイムで捉え自動運転する自動車などがあります。さらにその自動運転自動車が他の自動車や信号機と状況を共有することで、スピードを協調して制御することで渋滞を解消し、信号待ちを無くすことができます。
「2015年4月号 特集:IoTの衝撃」を参考に作成
http://www.dhbr.net/ud/backnumber/54f69910abee7b70cf000001
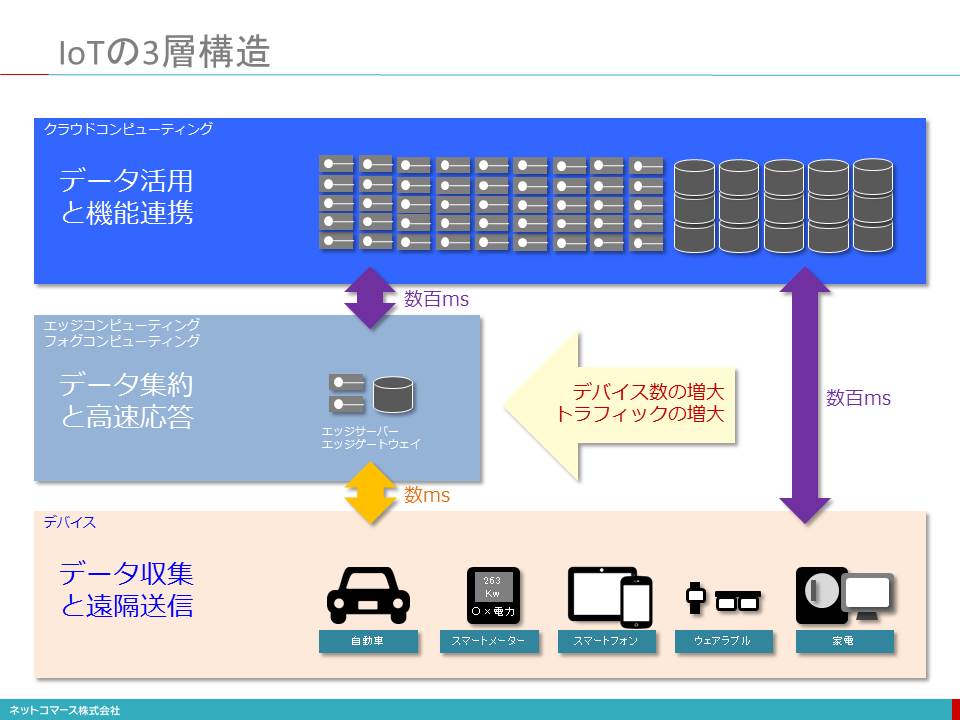
IoTの3層構造
【図解】コレ1枚でわかるIoTの三層構造
IoTは、データを収拾してネットワークに送り出す「スマート・デバイス層」、そのデータを収拾・集約しクラウドにデータを送ったり、すぐに結果を返さなければならない処理を行ったりする「エッジ・コンピューティング層」、集められた膨大データを解析し、アプリケーションを実行、再びモノへとフィードバックする「クラウド・コンピューティング層」に大別することができます。
「スマート・デバイス層」
「スマート・デバイス層」は、センサーや外部機器をつなぐためのインターフェイス、ネットワークにデータを送り出す通信機能、それらを制御するための処理機能が組み込まれたモノのことです。ここで、モノ自身から生みだされるデータや周辺のデータ、さらには接続された外部機器からのデータを受け取り、それをネットワークに送り出します。
「エッジ・コンピューティング層」
それらデータが直接クラウドに送り出される場合もありますが、モノの周辺でデータを一旦受け取り、すぐに処理してフィードバックする、あるいは集約して必要なデータのみをインターネットを介してクラウドに送り込む「エッジ・コンピューティング層」が介在する場合があります。
このような仕組みが必要になるのは、モノの数が莫大なものになると次のような問題が起こるからです。
個々のモノに対する回線を確保するために相当のコストがかかる
送り出されるデータが膨大になりネットワークの負荷が高まってしまう
モノの監視や制御に負荷がかかり、クラウド集中では処理しきれない
以上の問題に加え、時にはモノやその周辺の変化に即応してモノを制御したり、管理者や利用者にすぐに情報を提供したりといった対応も必要になりますが、インターネットを介してクラウドにデータを送り、そのフィードバックを受け取ろうとすると、距離が離れていることもあってどうしても大きな遅延が生じてタイミングを逸する可能性もあります。そこで、モノの置かれている周辺で分散処理をさせ、これらの問題を解決しようというわけです。
クラウド(雲)よりも地面に近いモノの周辺に置かれることから「フォグ(霧)コンピューティング」と呼ばれることもあります。
「クラウド・コンピューティング層」
「クラウド・コンピューティング層」は、これらスマート・デバイス層やエッジ・コンピューティング層から送られてきたデータを分析し、アプリケーションで利用します。その結果は、再び「モノ」の制御や使用者・管理者への情報提供というカタチでフィードバックされます。
IoTの様々なアプリケーションは、このような三層構造によって構築されてゆくと考えられています。
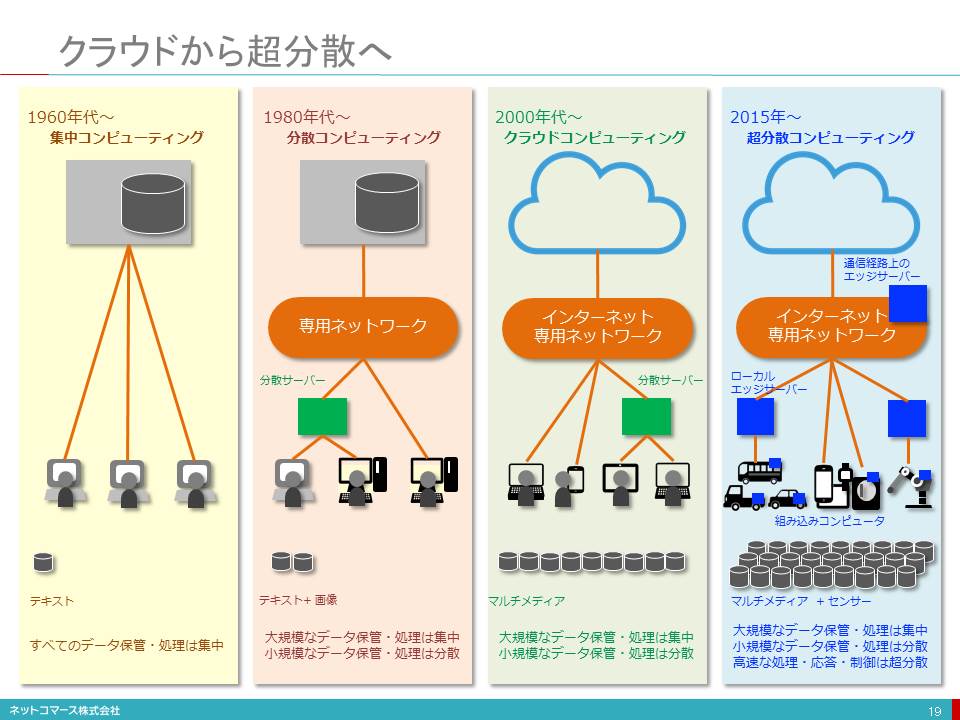
クラウドから超分散へ
【図解】コレ1枚で分かる超分散「エッジ・コンピューティング」の時代
1950年代
1950年代、ビジネス分野でのコンピューター利用が始まった当初は、計算業務を担当部門に依頼し、順次処理して結果を依頼者に返すといったパッチ処理による利用が一般的でした。
1960年代
1960年代に入り、コンピューターをタイプライター端末やCRTディスプレイ端末から直接利用するタイムシェアリング方式へと発展してゆきます。これら端末は、いまのパソコンのようなデータの処理や保管の機能はありません。データの入力と出力のみを受け持ち、データの処理や保管は全てひとつのコンピューターで集中処理されていました。また、端末とコンピューターをつなぐ専用のケープルや通信回線は低速で、やり取りできるデータもテキストに限られていたのです。
1980年代
1980年代、ミニ・コンピューター(オフコン)やオフィス・コンピューター(ミニコン)、そしてパーソナル・コンピューター(パソコン)といった小型で安価なコンピューターが登場します。これにより、大型コンピューターを共同利用するだけではなく、部門や個人でもコンピューターを購入できるようになりました。これに伴い、大規模なデータの処理や保管は大型のコンピューターを使い、部門固有の業務や個人で完結する業務は小型のコンピューターを使うといった分散処理が拡がりを見せ始めます。ただ、通信回線の速度はまだ遅く、やり取りできるデータはテキストが主流でした。そこで、テキスト主体の業務処理は共同利用を想定したコンピューター(サーバー)を使い、その結果の表示や加工、編集、画像の利用はパソコン(クライアント)を使う「クライアント・サーバ方式」といわれる連携利用の方法が登場し、普及してゆきます。
1990年代
1990年代インターネットが登場します。そして、2000年に入る頃から「インターネットの向こうにあるコンピューターを利用する」クラウド・コンピューティングの萌芽が見え始めます。その後インターネットは、高速・広帯域な回線を利用できるようになり、扱えるデータも音声や動画へと拡大してゆきます。この技術進化と相まってクラウド・コンピューティングは急速に普及してゆきます。また利用できる端末類もPCばかりでなくスマートフォンやタブレット、ウェアラブル端末などが加わり、適用業務の範囲も利用者も拡大してゆきます。
昨今
昨今は、インターネットにつながるデバイスは、自動車や家電製品、ビルの設備や日用品にまで拡がり、そこに組み込まれたセンサーが大量のデータを送り出すようになりました。そのため大量のデータが通信回線、主にはモバイル通信回線に送り出されるようになり回線の帯域を圧迫してしまう可能性が出てきました。そこで、デバイスの周辺にサーバーを配置し中間処理して必要なデータのみを回線に送り出す「エッジ・サーバー」が普及の兆しを見せ始めています。エッジ・サーバーはデータの集約だけではなく、デバイスを利用する現場での即時処理・即時応答が必要な業務やきめ細かなセンサーデータを大量に集めるための仕組みとしても使われています。このようなエッジ・サーバーは、空に浮かぶ雲に見立てた「クラウド・コンピューティング」に対して、地面に漂うように拡がる霧に見立て、「フォグ・コンピューティング」と呼ばれる場合もあります。
エッジ・サーバーは、デバイスが置かれるローカルばかりでなく、より広い地域をカバーするために通信回線の経路上に置かれるケースも想定されています。
IoTの普及と共に、クラウドだけではできない大量データの処理や高速応答を受け持つ役割としてエッジ・サーバーによる超分散コンピューティングは、ますます拡がりを見せ始めています。
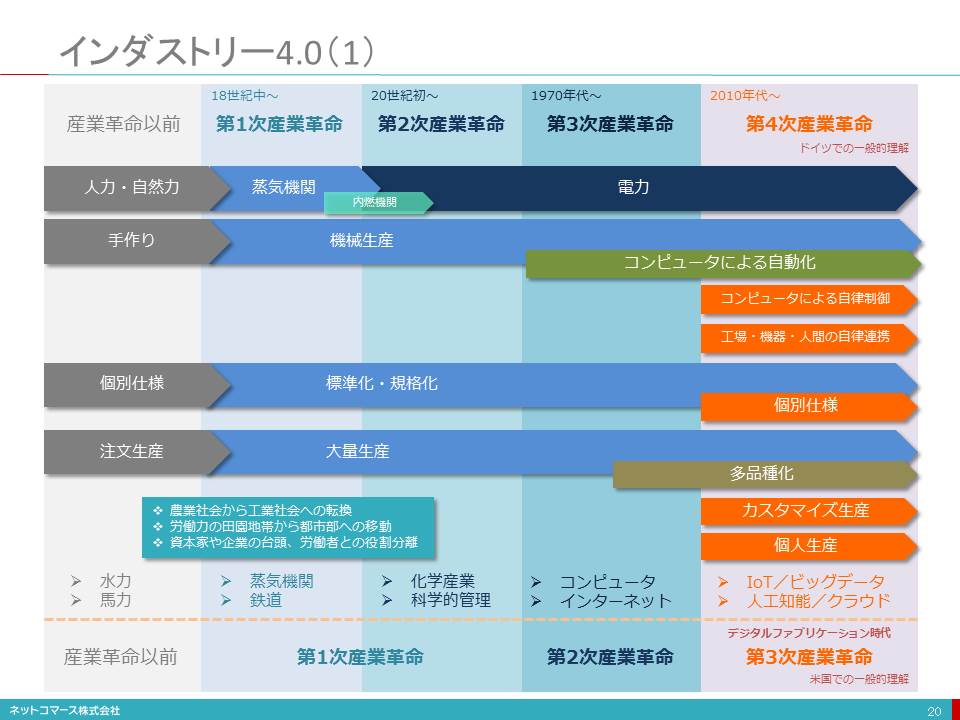
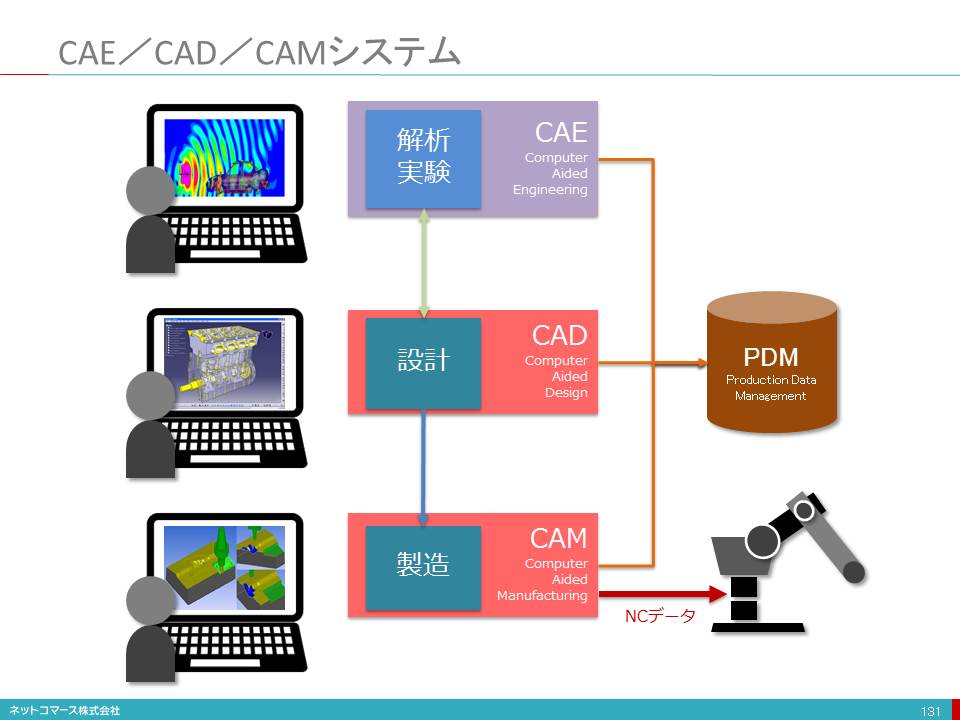
インダストリー4.0(1)
【図解】コレ1枚で分かる産業革命の区分
ドイツの産業政策である「インダストリー4.0(第4次産業革命)」に対して、アメリカでは「第3次産業革命」が提唱されている。両者にどのような区分の違いがあるのだろうか。
「インダストリー4.0(第4次産業革命)」
まず、インダストリー4.0(第4次産業革命)について見てゆくことにしよう。
産業革命以前
産業革命以前、もの作りは手作業が主体で、水車や馬力などの自然力が一部で使われていた。生産者は、それぞれに仕様を決め、注文生産でもの作りを行っていた。
1764年
1764年、イギリスでジェニー紡績機が発明され紡績の生産性が飛躍的向上する。同時期、ジェームズワットによって蒸気機関に改良が加えられ、高効率な動力源としての普及が始まる。このイギリスに端を発する大量生産の時代を第1次産業革命と呼ぶ。
大量生産は、その効率を追求する過程で標準化や規格化を推し進めた。これによって工業化が進み、農業を中心とする社会から工業を中心とする社会へと変貌を遂げてゆく。この需要を満たすために、労働力は田園地帯から都市部へと移動し、企業化による生産資本の集中、資本家と労働者という役割区分の明確化がすすんでゆく。
19世紀後半より
その後、19世紀後半より、石油の普及もあり、内燃機関(エンジン)も動力源として使われるようになった。さらに、電力が普及し大量生産を支える動力源として広く使われるようになってゆく。また、標準化や規格化と共に、統計的手法を用いた科学的な管理手法も定着し、生産性や品質の向上に貢献するようになった。T型フォードに代表される効率化を追求した量産システムの登場や化学産業の台頭など、軽工業から重工業へ大量生産への取り組みが広がりはじめた時代でもある。これを第2次産業革命と呼んでいる。
1950年代から1960年代
1950年代から1960年代にかけて、商用コンピューターの普及が始まる。当初は、事務作業を機械化することが主な用途だったが、1970年代に入り、もの作りの現場にコンピューターが使われるようになった。産業用ロボットの普及と相まって生産の自動化がすすめられてゆく。この時代を第3次産業革命と呼ぶ。その後、コンピューターの利用技術の発展と共に他品種少量生産に対応したフレキシブル・マニファクチャリング・システム(FMS)へと適用が拡がってゆく。
さらに
さらに、インターネットの普及によりネットワーク接続が、低コストで容易になった。その結果、地域や企業を越える情報の共有と調整と生産に関わるモノの流れの全体最適をめざす、SCM(Supply Chain Management)の適用が拡大する。
その後
その後、自動化や自律化技術の進展を背景に、顧客ごとに異なる個別仕様の注文を量産品と同様のコストと短納期で提供できるもの作りを実現し、競争力を高めようという取り組みが始まった。これが、第4次産業革命、すなわちインダリストリー4.0だ。
「第3次産業革命」
これに対し、米国で提唱される第3次産業革命は、上記の第2次と第3次をひとまとめにして、第2次産業革命と区分しているようだ。第3次産業革命は、時間軸で見れば、ドイツの第4次産業革命と重なっている。インダストリー4.0と同様に標準化・大量生産から個別仕様・個別生産に対応する取り組みである。これに加えて、消費者自らが、もの作りに関わる「もの作りの民主化」をすすめようという「デジタル・ファブリケーション」を含め第3次産業革命と位置付けているようだ。個人やコミュニティが、消費の現場で設計し、3Dプリンターを使って「もの作りの個人化・個別化」を実現する。
区分の仕方や定義の違いはあるが、デジタル技術を活かし、低コスト、短納期で、もの作りの個人化や個別化に対応し、もの作りの変革を進めようという取り組みであることに変わりはない。これは、第1次産業革命以前の個別仕様・個別生産という個人に最適化されたもの作りへの回帰とも言えるだろう。
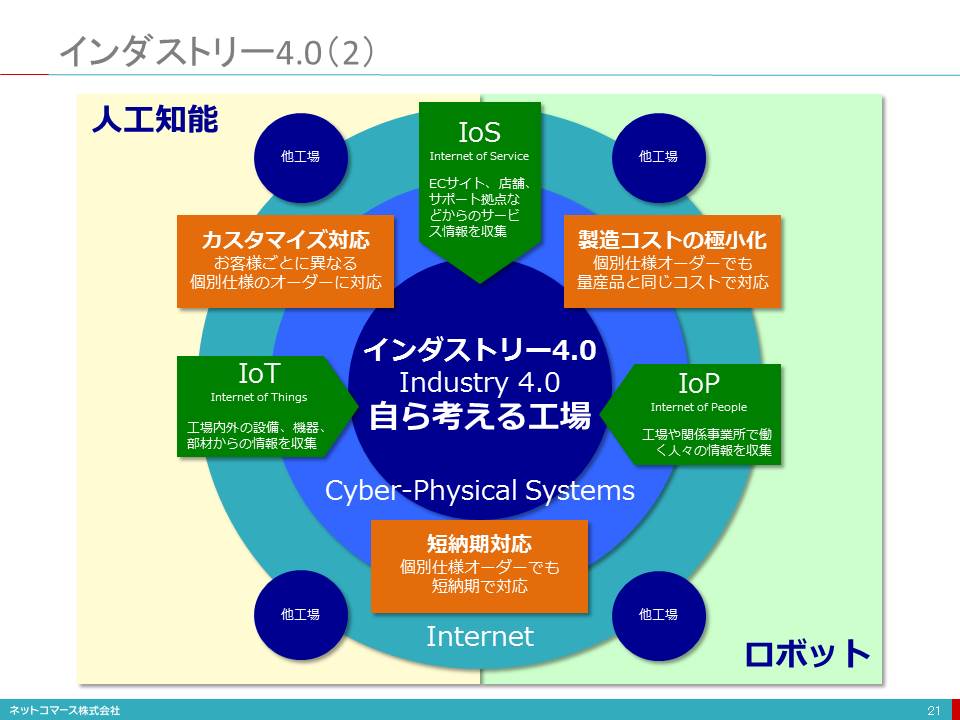
インダストリー4.0(2)
【図解】コレ1枚で分かるインダストリー4.0
「第4次産業革命(すなわちインダストリー4.0)」。仰々しい名前だが、もの作りの常識を大きく変えようというドイツの産業政策だ。
18世紀後半から19世紀にかけて、それまでは手作業で行われていた紡績を、水力や蒸気機関を使った機械による大量生産に置き換える動きが始まった。その後、その他の産業にも広がり工業化の時代へと向かってゆく。これが、第1次産業革命だ。20世紀初頭、もの作りに電力が使われるようになる。加えて、統計的手法を使った操業管理やベルトコンベアーによる大量生産などが普及し、近代的なもの作りへと飛躍した時期を第2次産業革命と呼んでいる。1970年代に入り、コンピューターの普及と共に生産の自動化が推し進められた。これが、第3次産業革命だ。我が国は、この波に乗り、「メイド・イン・ジャパン」の時代を築いてきた。いまは、この第3次産業革命の延長線上にある。このパラダイムを大きく変えようという取り組みが、第4次産業革命、すなわちインダストリー4.0だ。我が国は、この新たなパラダイムシフトの中で、存在感を示せていない。この流れに呑み込まれるのか、それとも新たな輝きを取り戻せるのか、そんな岐路に立たせているように思う。
では、インダストリー4.0とは何か。これを1枚のチャートにまとめてみた。
顧客ごとに異なる個別仕様の注文、これを量産品と同じように低コストと短納期で提供できるもの作りの仕組みを作ろうという取り組みだ。
これを支えるのが、3つの「インターネット」だ。
ひとつは、IoT(Internet of Things)。製造機械や工場設備にセンサーが組み込まれ、操業に関わるデータをリアルタイムで収集する。また、素材や材料には、ICタグ(RFID)が付けられ、その流れがリアルタイムで把握される。また、工場で働く人もネットに繋がり、その行動がリアルタイムで把握され、その人の作業状況に従い、最適な作業工程に配置される。さらに、その人のスキルや作業経験、習熟度合い応じ適切なガイドや指示が出される。これが、IoP(Internet of People)だ。また、お客様からの注文やサポートなどの情報もリアルタイムで集められる。これが、IoS(Internet of Service)だ。
IoT(Internet of Things)
製造機械や工場設備にセンサーが組み込まれ、操業に関わるデータをリアルタイムで収集する。また、素材や材料には、ICタグ(RFID)が付けられ、その流れがリアルタイムで把握される。
IoP(Internet of People)
また、工場で働く人もネットに繋がり、その行動がリアルタイムで把握され、その人の作業状況に従い、最適な作業工程に配置される。さらに、その人のスキルや作業経験、習熟度合い応じ適切なガイドや指示が出される。
IoS(Internet of Service)
また、お客様からの注文やサポートなどの情報もリアルタイムで集められる。
このように、もの作りに関わるあらゆるデータが、リアルタイムで収集されデータとして集められる。つまり、もの作りの現場である現実の世界(Physical World)が、コンピューター世界(Cyber World)にデジタルなコピーとして再現される。このデジタルなコピーで、様々な作業工程や段取りを再現し、最適な方法や手順を見つけてゆく。コンピューター上のシミュレーションなら、何度やっても実作業に影響を及ぼすことはない。そして、最適解を見つけて、もの作り現場に指示を出すと共に、機器の制御や手配を行う。そして、再び、そのデータは、コンピューター世界にフィードバックされる。言うなれば、現実世界とコンピューター世界の間で、「カイゼン活動」を行っているようなものだ。「自ら考える工場」とは、そういう意味である。
現実世界とコンピューター世界が密接に連携して実現するこのような仕組みをCyber-Physical Systems(CPS)と言う。このような仕組みを関連する工場がそれぞれに実装し、連携しながらもの作りを行おうというのが、インダストリー4.0だ。これを人工知能やロボットのテクノロジーが支える。
ドイツでは、産学官をあげてインダストリー4.0に取り組んでいる。その背景には、ドイツの労働単価の高さがある。高い労働単価であっても、世界で通用するコストと品質、そして、サービスを提供することで、競争力を維持し続けたいという想いがあるからだ。
このような仕組みが実現されれば、労働者はいらなくなり、むしろ就労需要を減らすのではないかという批判もあるようだ。しかし、今のドイツは、近隣諸国からの多くの出稼ぎ労働者によって産業を維持している。また、このような仕組みを実現することで、新たなビジネス機会を創出し、世界におけるもの作りのイニシアティブもとれるはずだとの思惑もある。
少子高齢化が進む我が国も、このような取り組みをすすめてゆく必要があるだろう。未だドイツのような大がかりな組織的取り組みには至っていないが、大いに期待したいところだ。
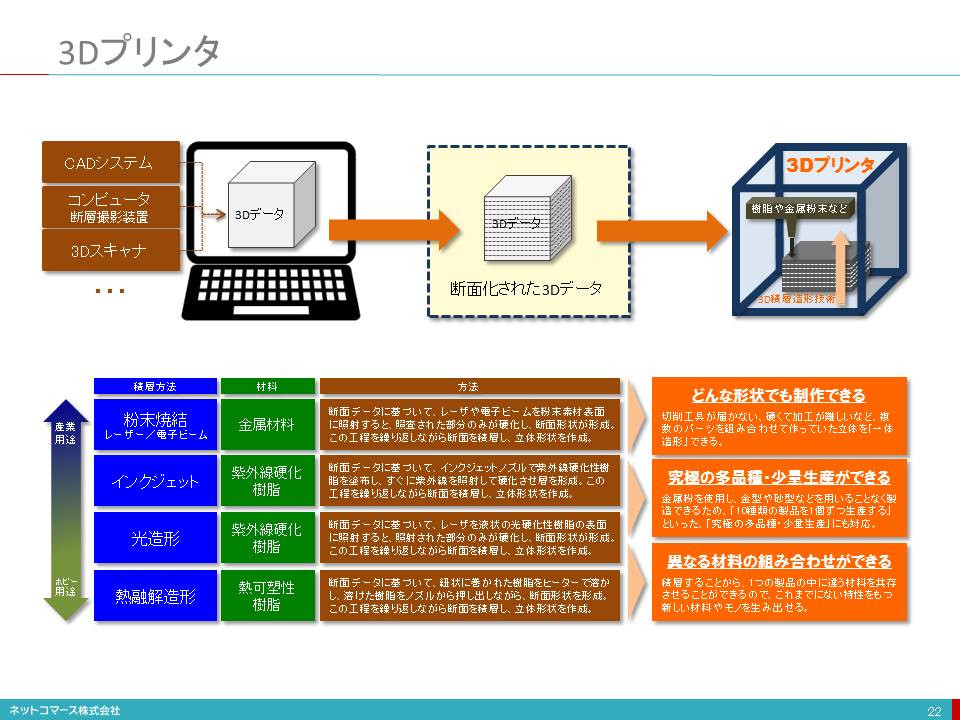
3Dプリンタ
「デジタル・データから立体の造形物を直接作り出す装置」が、3Dプリンタです。
3Dプリンタは、コンピュータに取り込まれた3Dデータをミクロン単位の薄い断層データに分解し、これに沿って樹脂や金属粉末などを少しずつ積層しながら立体形状に仕上げてゆく「3D積層造形技術」が、一般的に使われています。最近では、食品素材を材料に食べ物を作れる3Dプリンタも登場しています。
用途には次のようなものがあります。
製造業:CAD(コンピュータを使った設計)データを元に、試作品やモックアップ、鋳物のための中子や砂型、少量生産の特注品など
医療:コンピュータ断層撮影装置などの人体内部の立体形状データを元にした手術前検討用臓器模型、患者個別の移植用人工骨格など
建築業:提案、説明のための建築模型
1980年代に登場した3Dプリンタですが、当時は周辺技術が揃わず、価格も数千万円と高価で普及しませんでした。それが昨今、数十万円、数万円に価格低下したことで、注目されるようになったのです。また、従来、素早く試作する(ラピッド・プロトタイピング)が主な用途でしたが、最近は精度も上がり材料の選択肢も増えたことで、素早く生産する(ラピッド・マニュファクチャリング)へと用途を広げつつあります。
3Dデータはネットを介して自由にやり取りできます。例えば、地上で作られた設計データを使い国際宇宙ステーション(ISS)に設置された3Dプリンタで、工具や補修部品が作られるようになりました。また、「もの作りの民主化」が進み、産業のあり方を根底から変えてしまうという意見も聞かれるようになりました。
ロボット同様、3Dプリンタは、コンピュータと人をつなぐ新しいUI(ユーザー・インターフェイス)として、今後も注目されてゆくことになるでしょう。
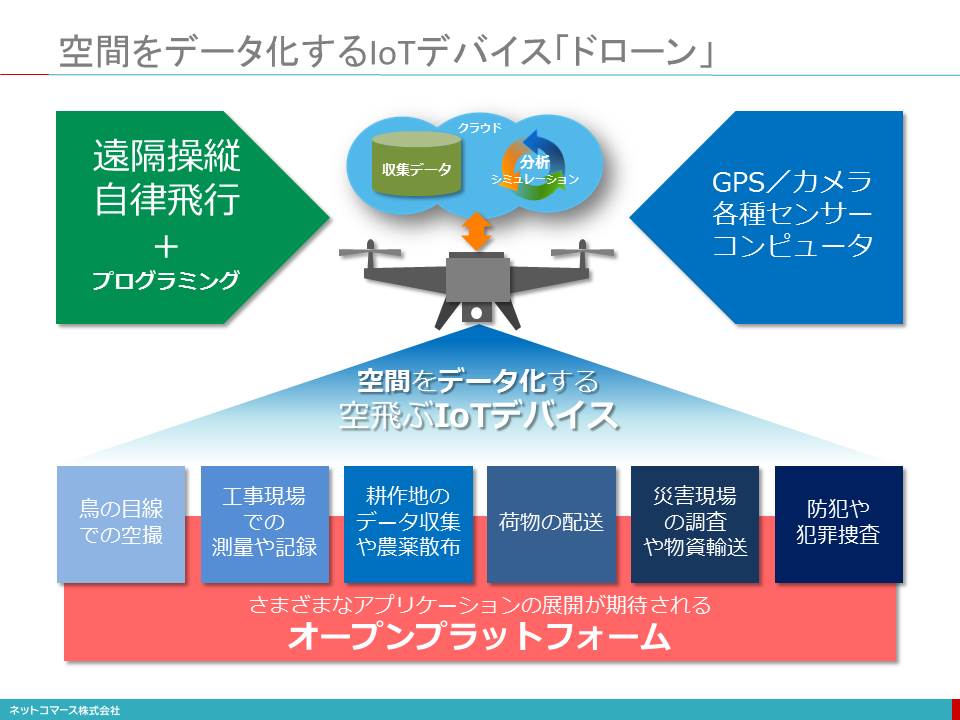
空間をデータ化するIoTデバイス「ドローン」
ドローン(drone)とは、遠隔操作が可能な無人飛行機の総称で、ブーンと羽音を立てて飛ぶ「雄の蜂」を意味する英単語から転じて使われるようになりました。
元々は戦場における偵察や攻撃などの軍事用に開発されましたが、農薬散布や空撮などの業務用、あるいは飛ばして楽しむホビー用として用途が広がっています。大きさは全長数センチ程度の小型のものから10メートル超の大型のものまであり、形状は複数のプロペラを持つヘリコプター(マルチコプター)が一般的で、固定翼の機体なども登場しています。
また、静止画や動画を撮影するカメラに加え、位置情報を捉えるGPS、速度や動きを検知する加速度センサー、傾きや角度などを検知するジャイロセンサーなどを搭載しています。それらを使って自ら機体を安定させ、指定した経路を自動で飛行し元の位置に戻ってくるなどの自律飛行ができる機体もあります。このあたりが従来のラジコン機と異なるところです。
これらドローンに使われている電子部品は、スマートフォンで使われるカメラやセンサー、プロセッサーや電池などと共通するものもすくなくありません。そのためスマートフォンの大量生産による部品の低価格化によって、ドローンの市販価格も下がり、業務用途ばかりでなく個人での利用も拡大しています。
「オープン化」への取り組みも注目されています。ドローンは、カメラやセンサーで様々なデータを捉え、無線を介してインターネットとつなげて、クラウドにデータを送ることができます。「空飛ぶIoTデバイス」とも言えるこのような特徴を活かし、様々な用途での利用が模索されていますが、そのアプリケーションを誰もが容易に開発できるようにし、用途を広げてゆこうというのです。そのために、ドローンに最適化したオペレーティングシステムやプログラミング環境を共同で開発し広く公開する取り組みや、ドローンに必要な機能を標準で搭載したプロセッサーや電子部品のモジュールが市販されるようになりました。特に、IntelやQUALCOMMなど、パソコンやスマートフォンで標準プラットフォームを提供している企業は、次のプラットフォームの覇権を握るべく、積極的に製品開発を行っています。
ドローンが注目されるのは、これまでには無かった「空間をデータ化できる」有効な手段だからです。IoTが「現実世界をデータ化し、ネットに送り出す仕組み」として注目されていますが、「空間のデータ化」も当然に求められています。その手段として航空機や人工衛星など高高度からのセンシング技術は既にありますが、低高度でしかも移動しながらきめ細かくセンシングする有効な手段はこれまでありませんでした。そこに登場したのがドローンです。まさに未知の領域への可能性が生まれたのです。そのため用途については、まだまだ模索の段階ですが、大きな可能性が広がっていると言えるでしょう。このような理由から注目されているのです。
そんな模索段階ではありますが、既に様々な用途で使われはじめています。
鳥の目線での空撮
「鳥の目線」で飛びながら撮影できるのはドローンの魅力のひとつです。
ヘリコプターや航空機はどんなに低空でも数百メートルの高さからの撮影となります。人間が高台に登っても固定した位置からしか撮影できません。ドローであれば数メートルから100メートルほどの高さで鳥のように飛びながら撮影することができます。しかも機体の振動や風による揺れを補正してなめらかな動画を高画質で撮影できるカメラが搭載された機体も数万円から手に入るようになり、業務ばかりでなく趣味で空撮を楽しむ個人も増えてきています。
土木工事現場での測量や記録
土木工事の現場で、土地の形状や掘り出す土量を計測し、工事の経過を画像で残すことに使われています。
工事現場を複数の角度から撮影して3次元画像を作成、それを工事図面と重ね合わせることで工事箇所や掘り出す土量を計測できます。人間が行うことに比べ、短時間で高精度に計測できるようになりました。また、広い工事現場での作業状況を上空から撮影し、工事の進め方や進捗を記録し、安全管理や進捗管理に役立てようという取り組みも始まっています。
耕作地のデータ収集や農薬散布
これまで勘や経験、人手に頼りがちだった耕作地の様子をデータとして捉えるためにも使われています。
例えば、ドローンに搭載した複数の異なる波長の光で撮影する「マルチスペクトル・カメラ」を使い、
水分の不足しているところを見つける。
肥料の足りないところを見つける。
生育具合を確認する。
といったことがおこなわれています。
これまで、広い耕作地でこのようなデータを集める手段はありませんでした。もちろん航空機やヘリコプターを使えばそれも可能ですが、膨大なコストがかかり現時的ではありません。ドローンならあまりコストをかけず、1日に何度でも耕作地の上空を飛び回り、撮影することができます。そして、そのデータを活かして効率の良い耕作地の管理や作業が可能になるのです。
また、田畑への農薬散布にも使われています。人力で撒くには、背中に農薬を背負って歩きながら行わなければなりません。広い田畑なら何日も何週間もかかってしまいます。かといって、車両では田畑の内部までは入り込めませんから散布は困難でした。そのため以前は有人ヘリコプターによる上空からの農薬散布も行われていたのですが、高高度からの散布は農薬が広範囲に飛散することから人体への影響が心配され、次第に行われなくなっています。そこでドローンが使われるようになりました。有人ヘリコプターに比べ低高度で散布ができるので、周囲への飛散量が抑えられるからです。
荷物の配送
宅急便や郵便などの荷物をドローンで届けようという取り組みが始まっています。
ドローンであれば、道路の渋滞を気にする必要がなく、地上で配送するよりも短い時間、低コストで届けられると期待されています。また、住宅や集落が広い地域にまばらに点在している地域は世界を見渡せば少なくありません。そういうところで荷物ひとつのためにトラックや配送員を使うのではコストがかかりすぎます。このような課題を解決しようと、ドローンによる配送が試みられています。
災害現場の調査や緊急物資の輸送
災害現場の調査にも活躍しています。
例えば、河川の決壊や土砂崩れなどの災害では被災現場へ入れないことも多く、空からの調査は有効な手段です。しかも、低空でカメラからの画像を見ながら移動し、高画質の動画撮影できるので被害状況を詳細に把握できます。
また、道路が寸断され孤立した集落に物資を届けるようなときにも役に立つと期待されています。
防犯や犯罪捜査
警察でもドローンが使われています。
例えば、米国では危険な犯罪現場の偵察、メキシコ国境の密入国者の監視に使われています。また日本でも交通事故や犯罪現場の捜査にドローンの導入がすすめられています。
我が国では、2015年12月の航空法改正により、ドローンの飛行ルールが明確になりました。これをきっかけとして、ドローンの活用が一層拡がるものと期待されています。
VR(仮想現実)とAR(拡張現実)
【図解】コレ1枚で分かるVRとAR
コンピューターと人間が視覚を介してつながる技術が登場しています。
VR(Virtual Reality :仮想現実)
ゴーグルを被るとコンピューター・グラフィックスで描かれた世界が目の前に拡がります。顔の動きや身体の動きに合わせて映像も動き、ヘッドフォンを被れば音響効果もそれに加わり、まるで自分がそこにいるかのような感覚を体験できます。これがVRです。コンピューターで作られた人工的な世界に自分自身が飛び込み、まるでそれが現実であるかのように体験できる技術です。
代表的な製品としては、Oculus Rift、HTC Vive、PlayStation VRなどがあります。次のような用途に使われています。
没入感を体感できるゲーム
航空機の操縦シミュレーション
3D映像で作られた住宅の中にシステムキッチンなどの住宅設備を設置してみせるデモンストレーションなど
AR(Augmented Reality:拡張現実)
ゴーグルやスマートフォン越しに見ている現実の建物や設備に、それが何かを説明する「別の情報」が重なるように表示されます。自分が見ている室内の光景や風景に、実際にはそこにないモノや建物が表示され、まるでそこに実物があるかのようです。身体を動かしても位置が変わりません。これがAR技術です。現実に見ている視覚空間に情報を重ね合わせて表示させ、現実世界を拡張する技術です。
代表的なゴーグル型の製品としてMicrosoft HoloLensがあります。他にもスマートフォンやタブレットを風景にかざし、背面カメラで映し出された映像に情報を付加するソフトウェア製品も数多く登場しています。次のような用途に使われています。
・設備点検の時に見ている箇所についての情報を表示させる
・機械の操作パネルの映像上にスイッチやレバーの説明や操作方法を表示させる
・現実の空間にモノを表示して製品の検討や教育などに使う
スマートフォン越しに映し出された建物や風景に説明情報を重ねるように表示して観光案内をする など
世界最大級の投資銀行であるゴールドマン・サックスは、世界のVR/AR市場は2025年までにおよそ800億ドル(約9兆円)に達すると予測しています。これは、現在のデスクトップPC市場にほぼ匹敵する規模です。その市場は、現在盛り上がりつつあるゲームやエンターテイメント分野だけではなく、医療分野や産業分野、小売市場など様々な業界で使われるようになるだろうと予測しています。
https://www.youtube.com/watch?v=imZ_4cO0P7Y
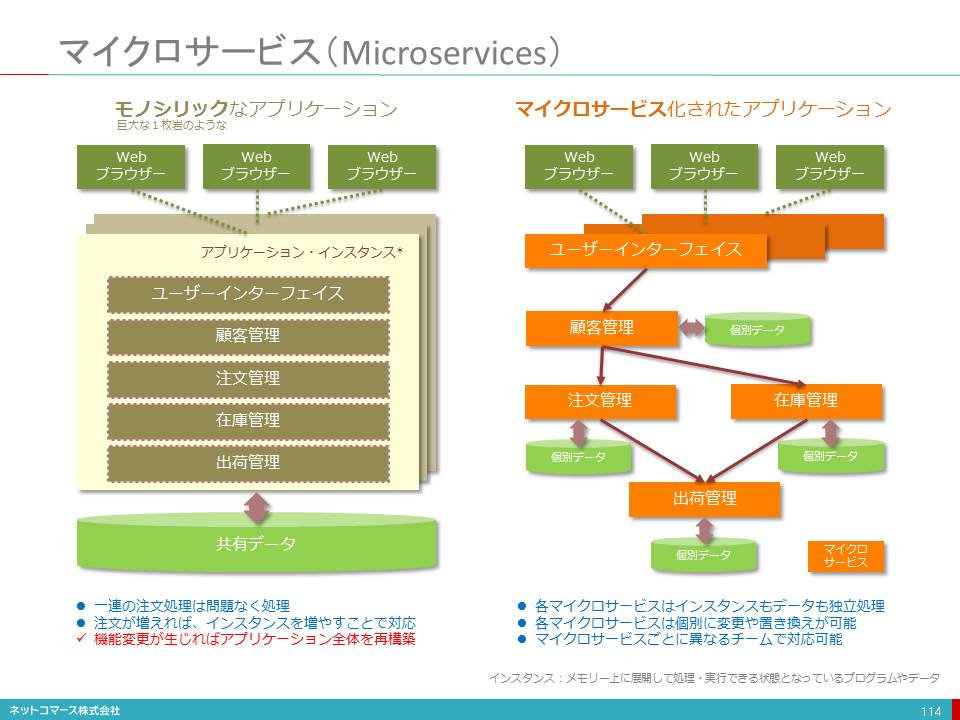
第2章 人工知能とロボット
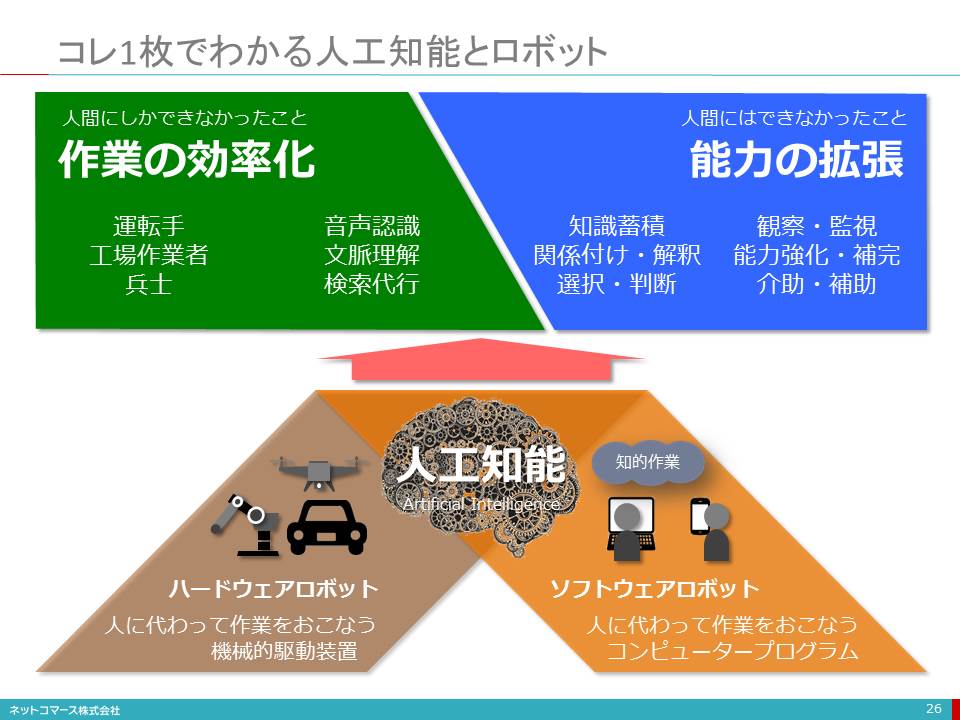
コレ1枚でわかる人工知能とロボット
人工知能研究の歴史
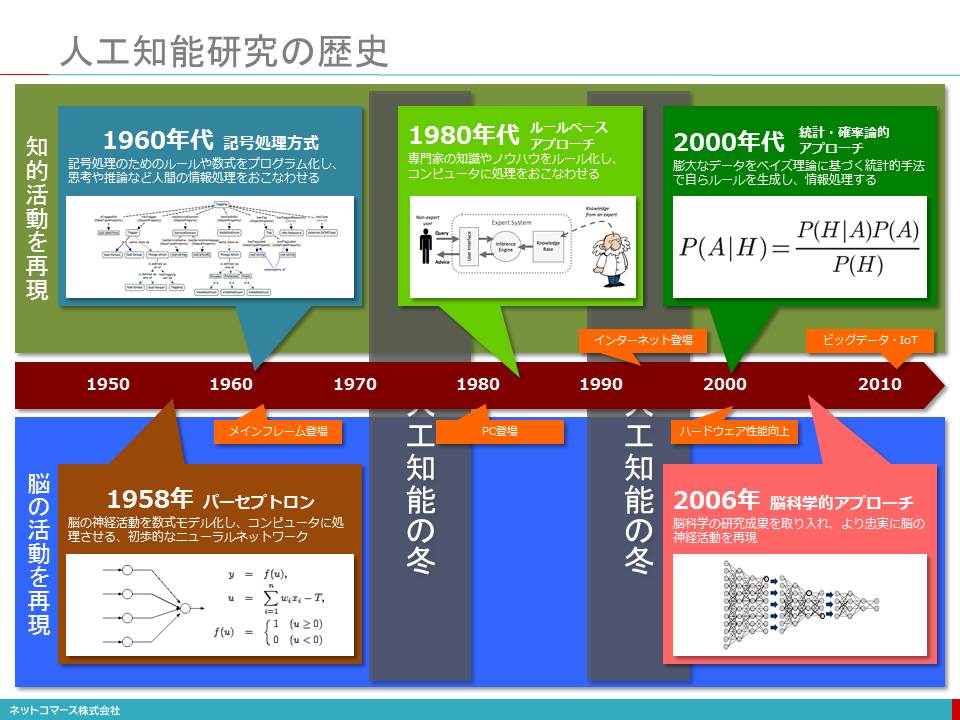
【図解】コレ1枚でわかる人工知能の歴史
1940年代
「電子頭脳を実現する。」1940年代、プログラム可能な電子計算機の登場に触発され、思考する機械が作れるのではないかという議論が始まったと言われています。
当時最新の神経学の成果として、「脳の神経細胞は、電気的ネットワークで構成され、ONとOFFのパルスの組合せによって思考する」ということがわかってきました。「思考機械」の研究は、この仕組みを機械で再現しようというところから始まったのです。当時は、まだコンピューターが普及する前だったこともあり、アナログ回路を作っての研究が中心でした。
1950年代
1950年代に入り、コンピューターが使えるようになると、「数を操作できる機械は記号も操作できるはず」との考えから、コンピューターを使った思考機械の研究が始まります。1956年、米ダートマスに研究者たちが集まり、「やがて人間の知能は機械でシミュレーションできるようになる」と考えを提唱、これを"Artificial Intelligence(人工知能)" と名付けたのです。これを切っ掛けとして、企業や政府から多額の研究資金を集めました。
1958年、脳の神経活動を数式モデル化しコンピューターに処理させる初歩的なニューラル・ネットワーク「パーセプトロン」が登場します。また、1960年代に入り、記号処理のためのルールや数式をプログラム化し思考や推論など人間が行う情報処理を行わせようという研究も広がりを見せました。
しかし、コンピューター能力の限界、また、記号処理のルールを全て人間が記述しなければならず、限界が見え始めました。その結果、実用に使える成果をあげることができないまま1970年代に入り、資金も縮小され、人工知能研究は、冬の時代を迎えることになります。
1980年代
1980年代に入り、「エキスパートシステム」が登場します。これは、特定分野に絞り、その専門家の知識やノウハウをルール化し、コンピューターに処理させようというものでした。例えば、計測結果から化合物の種類を特定する、複雑なコンピューターのハードウェアやソフトウェアの構成を過不足なく組み合わせるなど、特定の領域に限れば、実用で成果をあげられるようになったのです。
また、このルール処理を効率的に行う「推論コンピューター」の研究も始まります。1981年、日本の通産省は、「第五世代コンピュータプロジェクト」としてこの取り組みを支援しました。これに対抗するように、イギリスや米国でも同様のプロジェクトが始まります。また、ニューラル・ネットワークの研究においても、「Backpropagation(誤差逆伝播法)」という、今の機械学習の基礎となる手法が登場し、新たな研究成果を上げるようになりました。
1984年、エキスパートシステムの延長線上で、人間の知識を全て記述しようという「Cycプロジェクト」が米国でスタートします。例えば、「日本の首都は、東京だ」、「インド建国の父は、ガンジーだ」、「鯨は、ほ乳類だ」といった、知識をルールとして記述し、人間と同等の推論ができるシステムを構築することを目指したのです。しかし、知識は常に増えてゆきます。また、そもそも人間の知っていることが多すぎることやそれをどう表現するか、また、解釈や意味の多様性に対応することは容易なことではありません。そして、「知識やルールを入れれば賢くなるが、知識すべてを書ききれない」という限界に行き当たり、この取り組みも下火となっていったのです。
また、「推論コンピューター」も、ムーアの法則に沿って急速に価格性能比を高めて行った汎用で安価なコンピューターの登場により、存在意義を失ってゆきます。
2000年代
2000年代に入り、様々な、そして膨大なデータがインターネット上に集まるようになりました。また、コンピューターの性能もかつてとは比べられないほどに性能を向上させて行きました。この膨大なデータを高速のコンピューターを使って並列処理させ、統計的な処理によってコンピューター自身にルール生成をさせようという「機械学習」が登場します。また、最新の脳科学の研究成果を取り入れ、より忠実に脳の神経活動を再現しようという「ディープ・ラーニング」が登場しました。
このような新たな取り組みは、これまでの人工知能の研究成果の限界をことごとく打ち破ってしまいました。そして、実用においても多くの成果をあげつつあるのです。
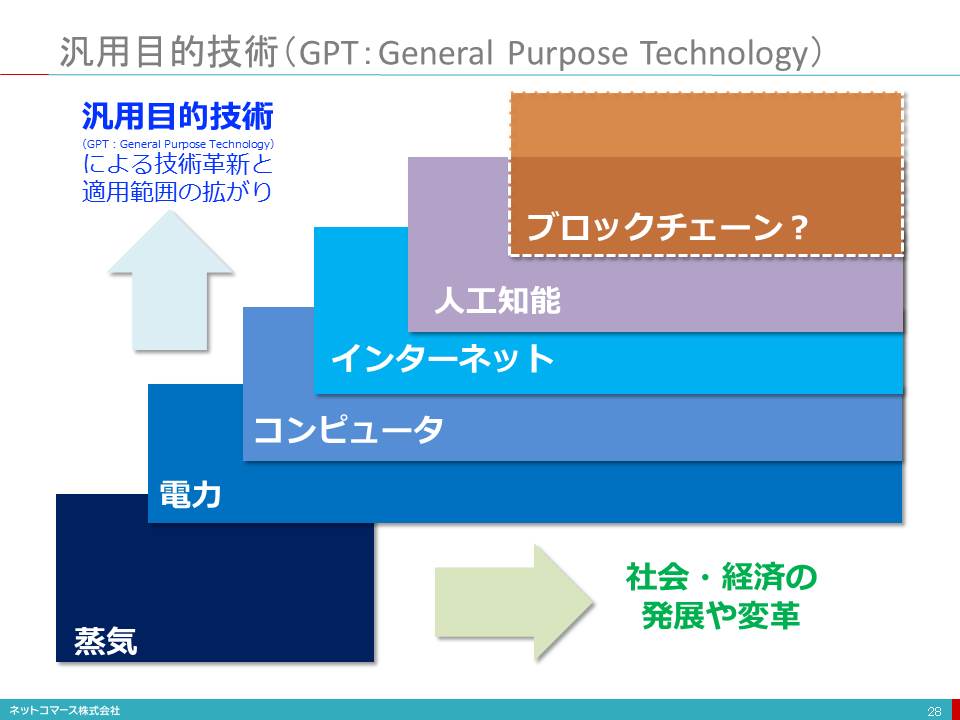
汎用目的技術(GPT:General Purpose Technology)
【図解】コレ1枚で分かる汎用目的技術(GPT)
歴史を振り返れば、経済発展の原動力となり社会構造の変化に新しい技術の登場は大きな役割を果たしてきました。しかし、全ての技術が等しく同様の役割を果たしたわけではありません。
様々な分野で広く適用可能な技術が、その役割を果たしてきました。このような技術は「汎用目的技術(GPT:General Purpose Technology)」と呼ばれています。
蒸気
例えば、18世紀後半~19世紀中期の第1次産業革命を支えた蒸気機関は、ものづくりばかりでなく鉄道や船舶にも用途が拡がり、経済や社会の仕組みを大きく変えてゆきました。
エンジン、電力
また19世紀後半~20世紀初頭における第2次産業革命を支えた内燃機関(エンジン)や電力もまた社会の隅々に行き渡り、いまでも私たちの社会や生活を支える主要な技術として広く使われています。このような技術がGPTです。
コンピュータ、インターネット
これら以外にも、1940年代に登場するコンピューター、1990年代に普及が始まるインターネットなども私たちの生活や社会に浸透し、その活動に様々な影響や変化を与えてきたGPTと考えることができます。
人工知能
次に来るGPTは「人工知能(AI:Artificial Intelligence)」かもしれません。
AIは既に特別な存在ではなく、様々なところに使われはじめています。例えば、機械翻訳や音声による検索、ショッピング・サイトでの商品の紹介やコールセンターでのお問い合わせに最適な回答を推奨する機能など、私たちは既に日常の中で知らず知らずに使っています。また、医療現場での診断支援や自動運転自動車の登場は、AIのさらなる可能性を実感させてくれます。
このようにAIは私たちの日常の様々な分野へ広く適用可能な技術として普及が進みつつあり、GPTとしての要件を満たしているものと考えることができます。
また同時にAIの進化と普及は雇用のあり方を大きく変え、人間の役割も変えてゆくでしょう。そうなれば社会や経済の仕組みにも大きな変化が生じることになります。AIはそれほど大きな社会的影響力を持つGPTであるとも言えるのです。
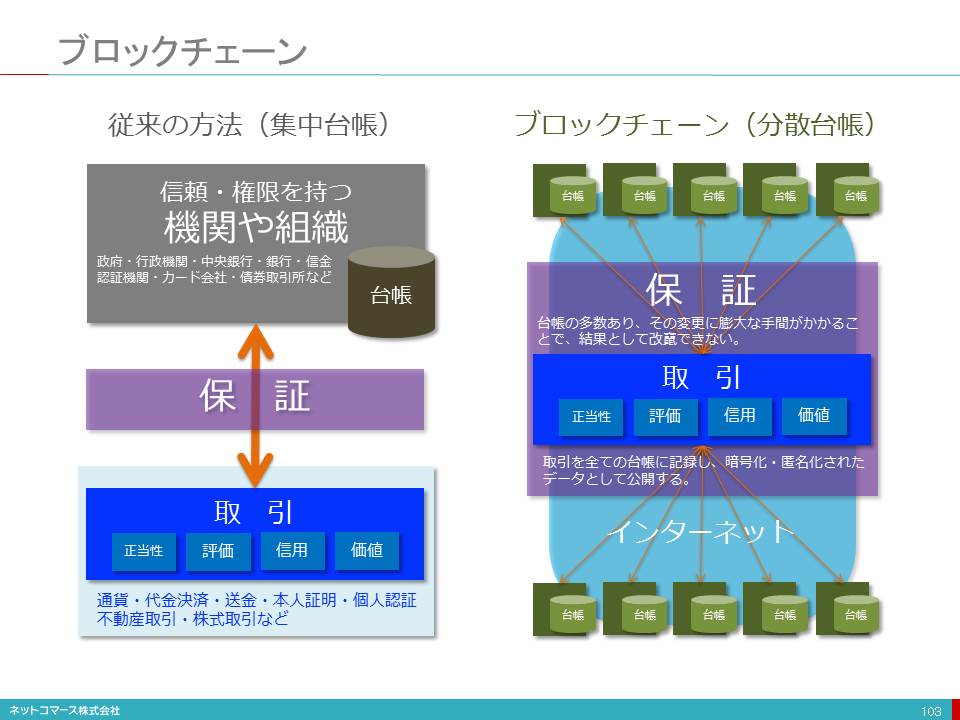
ブロック・チェーン
ITの分野で次のGPTと期待されているのが「ブロック・チェーン」です。
デジタル通貨「ビットコイン」の信頼性を保証する仕組みとして登場したこの技術は、通貨や金融取引以外にも契約や取引、認証などに必要とされる「信頼性を保証する安価で汎用的な基礎的技術」として広く使われてゆく可能性があります。
これまで通貨や取引は、国家機関や中央銀行、そのお墨付きを与えられた銀行や証券会社のような「権威」が保証することで、信頼を担保してきました。そのために多くの人材や巨大な組織を抱え、情報システムにも膨大な投資を行い、信頼を保証する仕組みを築いてきたのです。その歴史もまた信頼を保証する重要な要素となっています。
しかし、「ブロック・チェーン」はそのような権威や歴史に支えた信頼ではなく、暗号と分散処理の技術を駆使し信頼性を保証できる仕組みを安価に築こうというのです。もしこの技術が確立され普及するようになれば、国家や銀行などの役割も大きく変わり、社会や経済のしくみも変わってしまうかもしれません。そんなインパクトのあるGPTとして期待されているのです。
残念ながら、この技術はまだまだ黎明期にあり、可能性は期待されつつも実用には時期尚早といえる段階です。しかし、1990年代の半ば、インターネットは「掲示板や電子メール、ホームページという電子ポスター」程度にしか使えないと思われていた訳ですから、この技術が社会を大きく変えてしまう可能性も否定できません。
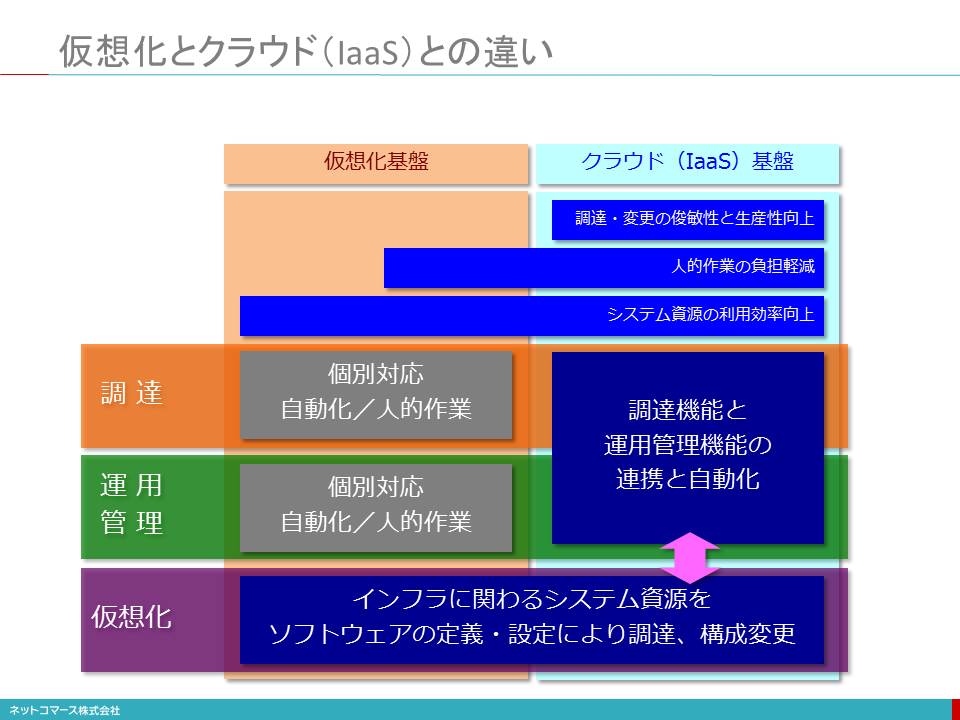
クラウド・コンピューティングやIoT
ところで、クラウド・コンピューティングやIoTはGPTと言えるのでしょうか。これにはいろいろな考え方があるようですが、個人的な意見としては「GPT」ではないと考えています。
両者は共にGPTのような汎用技術やそれを改良した応用技術を組み合わせた仕組みです。IoTを例にとれば、データを収拾するセンサー技術、コンピューターや電子機器を小型化する半導体技術、集めたデータをインターネットに送り出す通信技術、そのデータを解析し規則性やルールを見つけ出す人工知能技術などの組合せであり、それらを駆使して様々な価値を生みだそうという取り組みです。
クラウド・コンピューティングやIoTはの実用性は高く、市場の成長性も大いに期待されている分野であることは間違えありません。しかし、それをひとつの技術領域としてGPTに括ってしまうのは少し乱暴なような気がしています。
いずれにしろ、世の中の変化をGPTとその応用技術として捉え、その変化を捉えてゆくと、この先にどのような未来が拡がっているかを予測することができるかもしれません。
そして、そんなGPTにビジネスの軸足をのせておけば、様々なビジネス分野への応用が利くこともまた事実です。そんな視点からこれからの事業領域を考えて見るのもひとつの方法かもしれません。
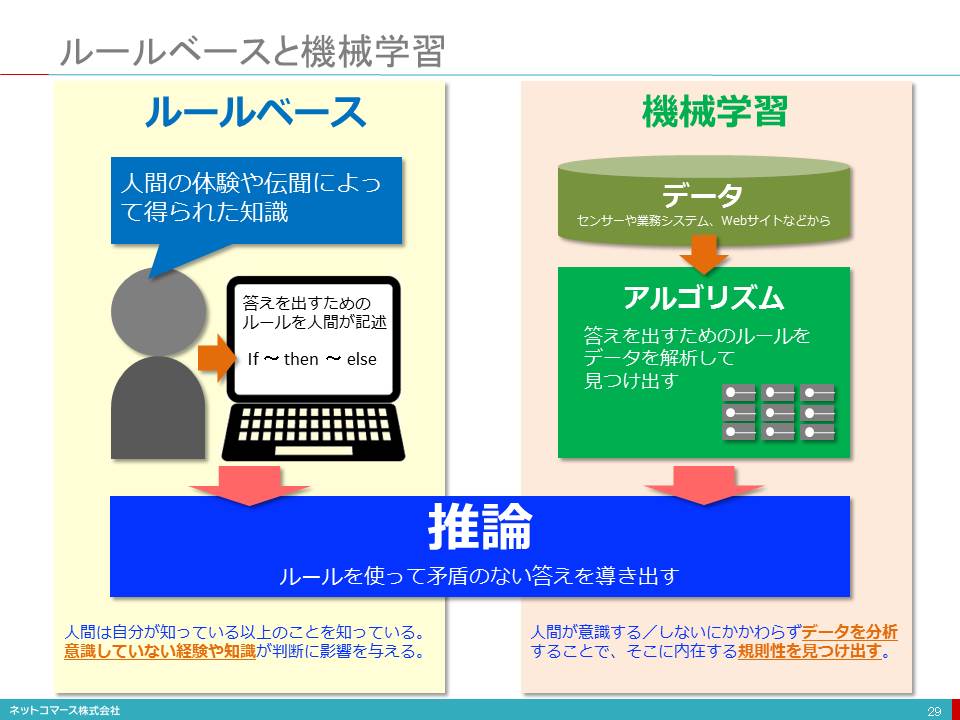
ルールベースと機械学習
【図解】コレ1枚で分かるルールベースと機械学習
人工知能研究の歴史をたどれば、「ルールベース」と「機械学習」という大きな2つのアプローチがあったことが分かります。
ルールベース
オンライン・ショップで「こちらの商品もいかがですか?」と表示されることがあります。これは、「レコメンデーション(推奨)」機能と呼ばれています。
この機能は、オンライン・ショップの担当者が「Aと言う商品とBという商品は関連があるから、Aを買った人は、Bも買う確率が高い」と考え、「Aを検索した人にBを薦める」というルールを予め登録しておくことで実現できます。このようなルールをたくさん用意しておけば、いろいろな商品に対してレコメンデーションできるようになります。このようなアプローチが「ルールベース」です。
レコメンデーションに限らず、問題解決に必要な知識を「どのような条件が成り立つとき何をすべきか」という観点で整理しておくと、様々な問題解決に対応させることができます。
if 条件 then アクションまたは状態 else 別のアクションまたは状態 ・・・
モノやコトを解釈し、説明するためのこのようなルールを用意しておくことで、問題解決や推論といった知的な処理を機械に行わせようというのです。
ただ、知識は常に増え続けますし解釈の仕方も多様です。これを全て人間がルールに起こして記述することは容易なことではありません。結局は、このアプローチは、ある機械についての故障診断、ある保険の契約ルールの確認といった説明すべきルールが限られている場合では実用化されましたが、「知的な処理」を実現するための汎用的な方法としては実用化されることはありませんでした。
機械学習
「ルールベース」では、ルールを人が登録します。しかし、Aを買う人はBも買う確率が高いというのは、担当者の思い込みかもしれません。実はCを買う人の割合のほうが、もっと高いかも知れません。そこで、このルールを、データを解析することで見つけ出そうというのが「機械学習」の考え方です。
例えば、オンライン・ショップの過去の取引データを解析して、AとBを一緒に買った人の割合とAとCを一緒に買った人の割合を比較し、割合の高い方を推奨すれば、レコメンデーションの効果も上がります。このような関係や規則性を、データを分析し、そこに潜むルールやパターンを見つけ出そうというのです。
このやり方は、レコメンデーション以外にも使われています。例えば、機械翻訳の場合、日英仏の同じ文書を機械に読み込ませ、「私は貴方を愛しています。」、「I love you.」、「Je t'aime.」が同時に出てくる確率が統計的に高いことを割り出し、これらは同じ意味と考えてもいいだろうと解釈する手法です。
本当に意味を解釈しているとは言えませんが、実用性は高く、論文試験の評価、医療における診断、訴訟文書の分析など様々な分野で実用化されています。
人工知能とは/弱いAIと強いAI
【【図解】コレ1枚でわかる「弱いAI」と「強いAI」
機械は人が操作するか、手順を教えてその通り動かすものでした。しかし、「人工知能(AI: Artificial Intelligence)」は、自ら学習し、状況を把握し、推論して判断できる能力を機械に与えます。
人工知能には、「人間のような知的処理の実現」と「人間と同等の知能の実現」の2つのアプローチがあります。
前者は「弱いAI」とも呼ばれ、人間の脳で行う処理のしくみにかかわらず、結果として人間が行う知的処理ができるようになることを目指します。例えば、馬のように走りたいからといって、馬をつくるのではなく、自動車を作ろうという考え方です。
これに対して、後者は、知能そのものをもつ機械を作る取り組みで、「強いAI」とも呼ばれ、脳科学や神経科学の研究成果を取り入れながら、人間の脳機能と同等の汎用的な知的処理ができるようになることを目指します。
「弱いAI」
「弱いAI」は、あらかじめ「ルール」をたくさん用意しておく「ルールベース」が始まりでした。外国語翻訳者や医者、弁護士といった専門家のノウハウをルール化して組み入れた「エキスパート・システム」が実用化されています。ただ、ルールを人が作り登録しなければなりません。そのため多大な手間がかかり、また様々な知的活動を全て人間がルール化するには限界があり、結果として普及しませんでした。
この状況を変えたのが、「機械学習」です。ビッグデータを統計的に解析して、「日本の首都」と「東京」の関係を見つけ出し、「日本の首都が東京である確率は99%」といった確率に基づき、「日本の首都は東京である」という推論を自動的におこないます。一方で、「変なヤツ」という表現が、嫌悪の意味なのか親しさの表明なのかといった文脈に即した意味は解釈できず限界もあります。
「強いAI」
「強いAI」は、人の脳の仕組みを模倣して、機械に人のように学習させ考えさせようというものです。神経細胞(ニューロン)のつながりをモデルにするため、「ニューラル・ネットワーク」と呼ばれています。これを使えば、人がルールを教える必要はありません。例えば、ネコと人間が映っている画像を大量に見せることで、両者の特徴を自分で学習し、両者の違いを区別できるようにしようといったことが実現できます。
現状では、前者の実用化が先んじていますが、後者の研究も急速に進んでおり、両者ともに、実用レベルでの適用範囲が拡大するものと期待されています。
人工知能・機械学習・ディープラーニングの関係
【図解】コレ1枚で分かる人工知能・機械学習・ディープラーニングの関係
「人間の知能は機械で人工的に再現できる」
そんな研究者の理想から 「人工知能」という言葉が生まれたのは1956年のことです。その後、半世紀以上にわたり研究が続けられてきました。この間、迷路やパズル、チェスや将棋といったゲームをうまく解くところから始まり、人間が持つ知識を辞書やルールとしてコンピューターに登録し、専門家のような回答を導こうとする研究が行われてきました。
しかし、人間が辞書やルールを作るわけですから、世の中の全ての事象を登録することなどできません。そのため狭い限られた分野では成果を上げることはできましたが、様々な分野で広く応用が利く「人間の知能」にはほど遠いもので、大きな成果をあげることはありませんでした。
その後、特定の業務や分野でのデータを解析し、その結果から分類や区別、判断や予測を行うための規則性やルールを見つけ出す手法「機械学習」が登場します。「機械学習」の考え方は以前からありました。しかし、コンピューター性能が不十分であり、その能力を発揮するには至らなかったのですが、コンピューター性能の向上と手法の進化と共に、その能力を高めてゆきます。
機械学習
「機械学習」は、どのような点に着目して分類や区別、判断や予測をおこなえばいいのか、その基準となる「特徴の選定と組合せ(特徴量)」を使ってデータを分析し、そのデータに潜む規則性やルールを見つけ出してゆきます。しかし、特徴量は人間が設計し登録しなければならず、その巧緻が結果を大きく左右しました。
ディープラーニング
しかし、ここ最近になって人間の脳の働きついての研究が進み、その成果を応用した機械学習の一手法である「ディープラーニング」が登場します。
この技術は、特徴量の選定や組合せを、データを解析することで自ら作り出すことができます。そのため、人間の能力に依存せずデータ量を増やすほどに、その性能を向上させることができます。いまでは、画像や音声の認識などで人間の能力を凌駕する性能を発揮しています。
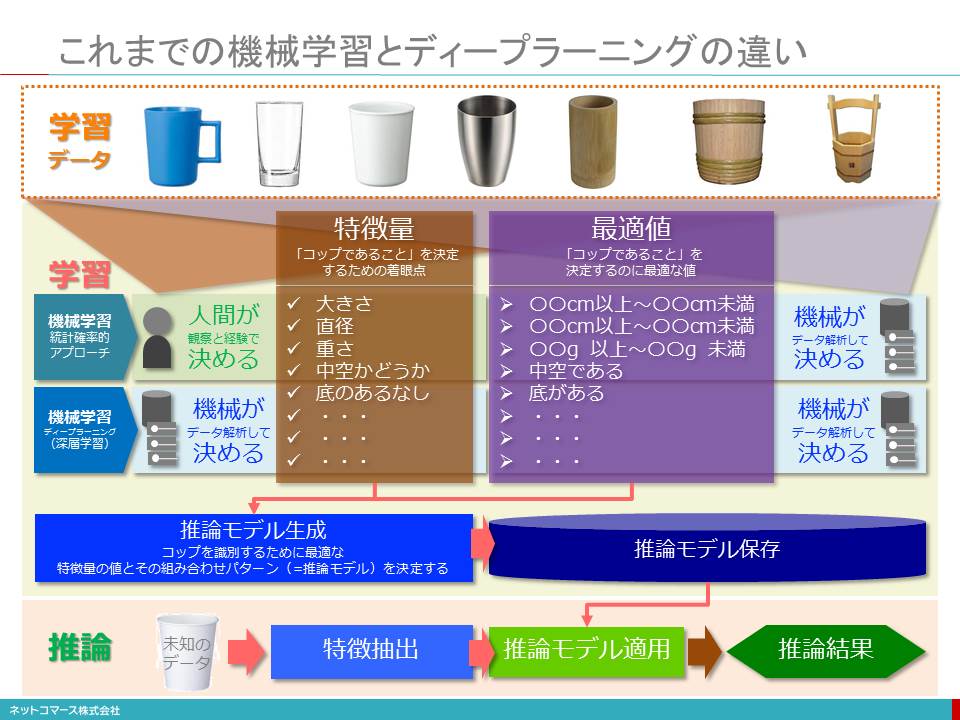
これまでの機械学習とディープラーニングの違い
【図解】コレ1枚でわかる統計確率的機械学習とディープラーニング
人工知能を支える中核的な技術に「機械学習」があります。機械学習とは、大量の学習データを機械に読み込ませ、分類や判断と言った推論のためのルールを機械に作らせようという仕組みです。そのプロセスは、大きく「学習」と「推論」の2つに分けることができます。
学習
大量のデータから特徴を抽出し、推論を行うための「ひな形」となる「推論モデル」を生成するプロセスです。
学習を行うには、入力された学習データにどのような特徴があるのかを見つけ出す必要があります。例えば、コップであれば、大きさ、重さ、直径、形状といった特徴の組合せを決めなくてはなりません。この特徴の組合せを「特徴量」と呼んでいます。この特徴量に対し、コップを識別するのに最適な値を決定してゆきます。
統計確率的機械学習では、特徴量の決定は人間が行い、その最適値を大量のデータを分析することで決定します。
これに対し、機械学習のひとつの手法であるディープラーニングでは特徴量と最適値の両方を大量のデータを分析することで決定します。
人間の経験や思い込みにとらわれることなく純粋にデータだけから特徴量や最適値を決定できることで、機械学習の性能は飛躍的に向上しました。
このようにして、「コップであること」を決定する特徴量の値とその組合せパターン、すなわち「推論モデル」が作られるのです。
推論
与えられたデータを推論モデルに当てはめて、推論結果を導き出すプロセスです。
例えば、コップの写真から、その特徴を抽出し、予め用意されている「推論モデル」とその特徴を照合します。それがコップの特徴を著す推論モデルと近いとなれば、「これはコップです」という推論結果が導かれます。
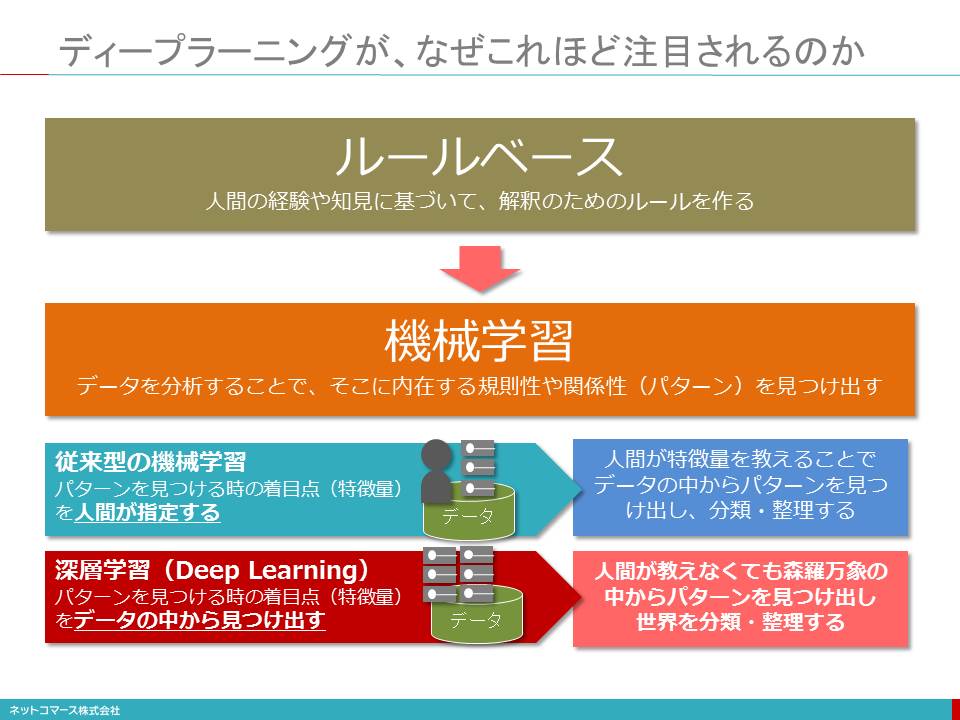
ディープラーニングが、なぜこれほど注目されるのか
人間が教えなくても森羅万象の中からパターンを見つけ、世界を分類整理する
ディープラーニングが注目されるのは、まさにこの点にあります。
データを分析し、その中に潜む規則性、すなわち「パターン」を見つけ出すことが機械学習のやろうとしていることです。それを使って、ものごとを分類整理し、推論や判断をおこなうための基準やルールを見つけ出そうというわけです。
これまでの機械学習は、このパターンを見つけるために、どのような特徴に基づいてパターンを見つけ出せばいいのかといった着目点、すなわち「特徴量」を予め人間が決めていました。しかし、ディープラーニングには、その必要がありません。データを分析することで特徴量を自ら見つけ出すことができるのです。
例えば、ベテランの職人がものづくりをする現場を想像してください。私たちは、道具の使い方、力加減、タイミングといった目に見える道具の使い方に着目し、その匠の技に感動するでしょう。しかし、本当にそれだけでしょうか。たぶん見た目には分からない他の「何か」がもっとあるかもしれません。その職人に、その説明を求めても、たぶんうまく説明することはできないでしょう。
そんな説明できない知識のことを「暗黙知」と呼んでいます。
ディープラーニングはそんな「暗黙知」をパターンとしてデータの中から見つけ出し再現してくれるかもしれません。それをロボットに搭載すれば、匠の技を持つロボットが実現するかもしれません。他にも、
・品質検査は、素人には気付か些細な不良を確実に見つけ出す
・保守技術者は、機械の運転データから異常に気付き故障を未然に防ぐ
・警察官は、犯罪の発生場所やタイミングを長年の経験や勘で予想する
など、世の中にはうまく説明できない「暗黙知」が少なくありません。ディープラーニングは、そんな見た目には分からない、あるいは気付くことの難しいパターンを、人間が特徴量を教えなくてもデータを分析することで自ら見つけ出し、そのパターンを教えてくれるところが、画期的なところなのです。
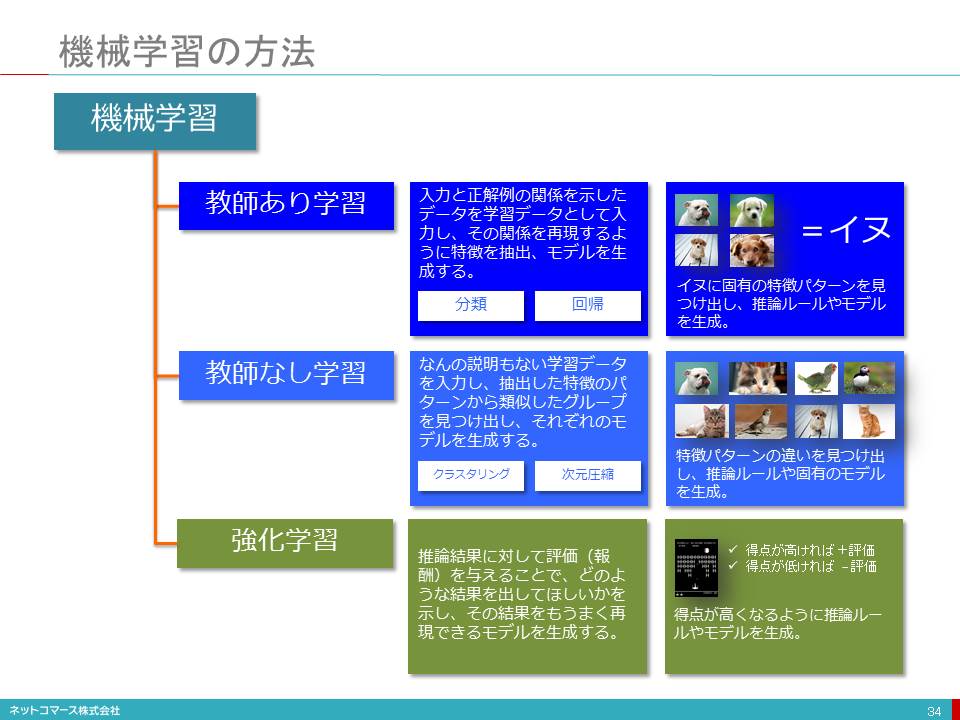
機械学習の方法
【図解】コレ1枚でわかる機械学習モデル
機械学習の方法には、大別して「教師あり学習」、「教師なし学習」そして、「強化学習」があります。
教師あり学習
入力と正解例の関係を示したデータを学習データとして入力し、その関係を再現するように特徴を抽出、モデルを生成するやり方です。
例えば、「イヌ」という正解を付した写真、「ネコ」という正解を付した写真を機械に学習させ「イヌ」や「ネコ」それぞれに固有の特徴やパターンを見つけ出し、両者の違いをうまく表現できる推論ルールやモデルを創り出します。
教師なし学習
なんの説明もない学習データを入力し、抽出した特徴のパターンから類似したグループを見つけ出し、それぞれのモデルを生成するやり方です。
例えば、「イヌ」、「ネコ」、「トリ」を区別することなく学習データとして入力すると、それぞれの特徴パターンの違いを見つけ出し、推論ルールや固有のモデルを生成します。それぞれを特徴付ける「概念」といえるものを創り出していると言えるかもしれません。
強化学習
推論結果に対して評価(報酬)を与えることで、どのような結果を出して欲しいかを示し、その結果をもうまく再現できるモデルを生成するやり方です。
例えば、ゲームの得点が高ければプラスに評価し、低ければマイナスに評価することを繰り返してゆくことで、得点が高くなる、つまり、プラス評価という報酬が与えられるようなゲームのやり方を再現できるルールやモデルを生成します。
それぞれの学習モデルについて、その性能を高めるための研究が進んでいます。ただ、それぞれに特徴があり、用途の向き不向きもあります。これらをうまく使い分け、あるいは組み合わせることで、機械学習の実用性を高めることが、すすめられています。
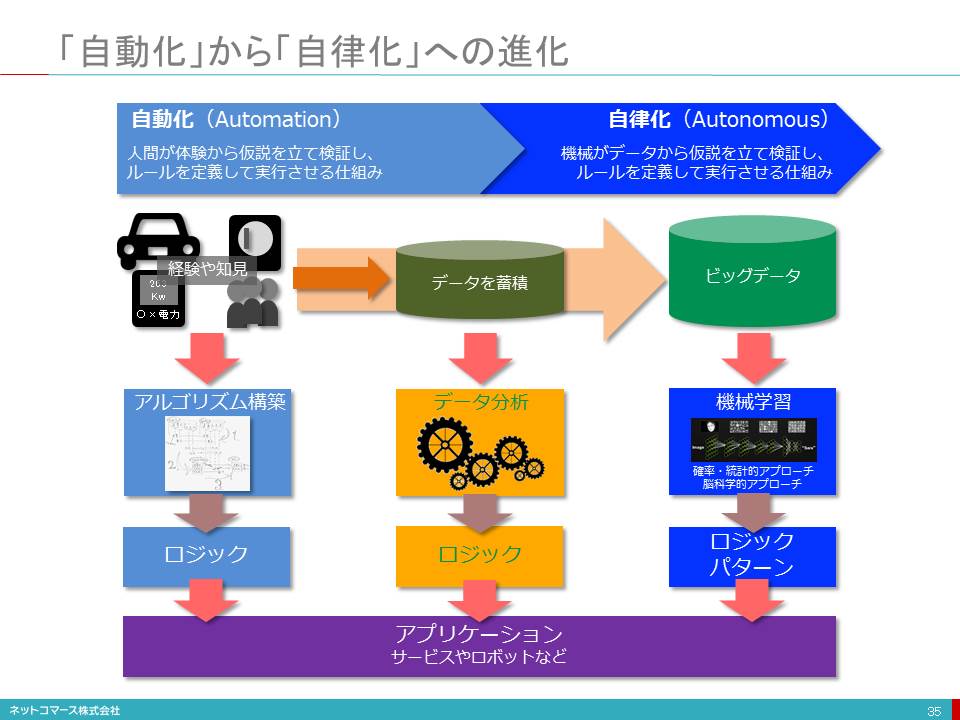
「自動化」から「自律化」への進化
【図解】コレ1枚で分かる自動化から自律化への進化
自動化
ITは、これまで、プログラムされたやり方をそのとおり確実にこなしてくれる自動化(automatic)への取り組みをすすめてきました。しかし、人工知能の機能や性能が向上するなか、自分で学習し、独自にルールを作り仮説検証し、状況を把握して最適な方法を選択・判断して自ら実行する自律化(autonomous)を実現する取り組みもすすんでいます。
例えば、目的地を指定すれば、ドライバーが運転する必要のない自動車や配達先を指定すれば荷物を届けてくれる無人航空機、基本的な作業手順を教えれば、自ら試行錯誤を繰り返し、作業スキルを高めてく産業用ロボットなど、自律化の機能を備えた機械「スマートマシン」が続々登場しています。
自動化とは、人間が体験から仮説を立て検証し、ルールーを定義して実行させる仕組みです。その手順は、人間が経験から得た知見に基づきアルゴリズム(問題を解決するための手順や計算の方式)を考案し、これに基づいてロジックを組み立てて、人間がプログラムを作成します。そして、そのプログラムを実行させることで自動化が実現します。
もっと作業の効率を高めたい、品質を良くしたいとなると、どうすればそれができるかを人間が試行錯誤を重ね仮説を立て、プログラムを改善することで対応します。
このような自動化の仕組みを使うことで、様々なデータが蓄積されてゆきます。そのデータを分析することで、人間の経験や勘にだけ頼るのではなく、データの裏付けがある規則性やロジックを見つけ出せるようになります。そのロジックを人間がプログラムにして実行させることで、処理手順を洗練させたプログラムを作ることができます。
自律化
さらにデータを分析し、そこ潜む規則性や最適なロジックを自動で見つけ出す「機械学習」の技術を使うことで、機械は自ら処理の手順を改善し、能力を高めてゆくことができるようになります。これが自律化です。人間が仮説を立て、手順を作りプログラムを作って、その通り実行させるのではなく、状況に応じて自ら判断して適応してくれるのです。
ITはいま、自動化から自律化へとステージを移そうとしています。その一方で、かつて自動化によって単純労働者の雇用が奪われたように、自律化はより高度な知的労働者の雇用をも奪うのではないかとの懸念の声も聞かれます。
しかし、ITが、「自動化」から「自律化」を目指す流れに抗うことはできません。ならばこの流れとうまく付き合ってゆく方法を考え、新たなビジネスの可能性を見出してゆく必要があるでしょう。
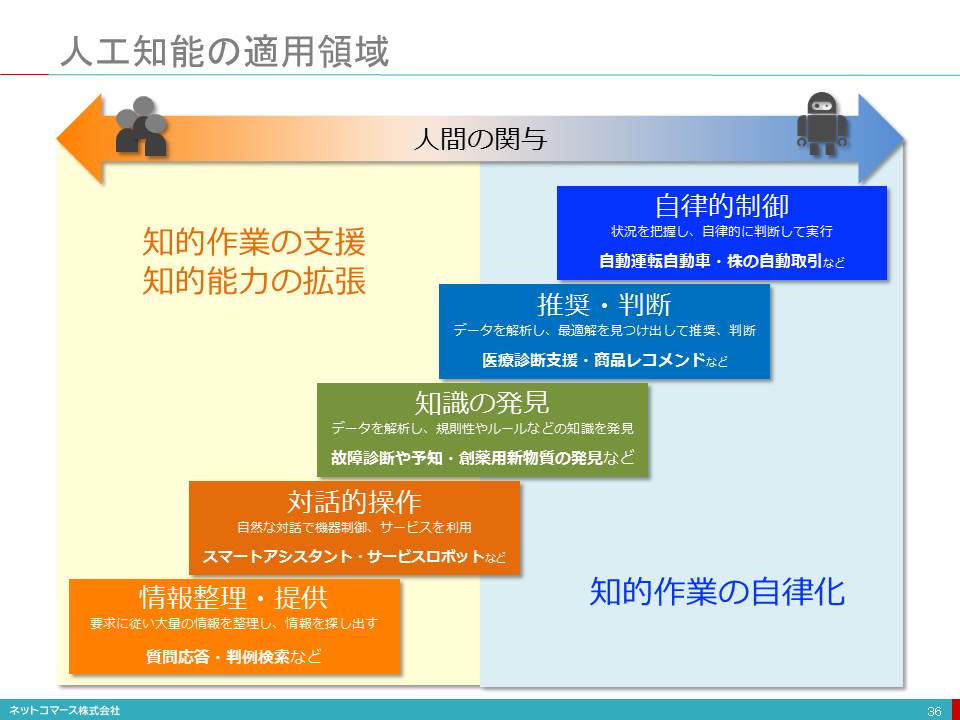
人工知能の適用領域
【図解】コレ1枚で分かる人工知能の適用領域
人工知能は、人間の関与を前提とした「人間の知的作業を支援」、あるいは「人間の知的能力を拡張」といった適用領域と、人間の関与を前提としない「知的作業の自律化」の2つの方向に拡がっています。
情報整理・提供
例えば、人間の関与が前提となる適用領域としては、要求に従って大量の情報を整理し、そこから必要な情報を探し出す「情報整理・提供」があります。
対話的操作
質問応答や判例検索などで利用が始まっています。また、日常使う言葉で機器を制御、操作したり、サービスを利用したりといったことを実現する「対話的操作」もこの領域に位置付けられるでしょう。
AppleのSiriやMicrosoftのCortana、AmazonのEchoなどのスマートアシスタントや人とのコミュニケーションを実現するサービスロボットなどがあります。
知識の発見
人間と人工知能が協力し合い成果をあげようという領域として、「知識の発見」があります。データを解析し、そこに潜在する規則性やルールを発見しようというものです。
故障の診断や予知、創薬用の新物質を発見するなどに使われます。
推奨・判断
人間が関与を前提とせず機械の自律性を活かしていこうという領域では、データを解析し最適な答えを機械自身に見つけ出させようという「推奨・判断」があります。
IBMのWatsonが行っている癌の診断支援のように膨大な論文を読み込み、さらに患者の診断所見や検査データを分析することで、癌を診断し治療法を提案してくれるサービスや、自分の好みやライフスタイルを教えることで自分にふさわしい商品を紹介してくれるサービスなどに応用が拡がっています。
自律的制御
さらに、自ら状況を把握、学習し、自律的に判断して実行する「自律制御」があります。
自動運転の自動車や株の自動取引、工場の自動操業や建設現場での自動工事などに適用分野は拡がり始めています。
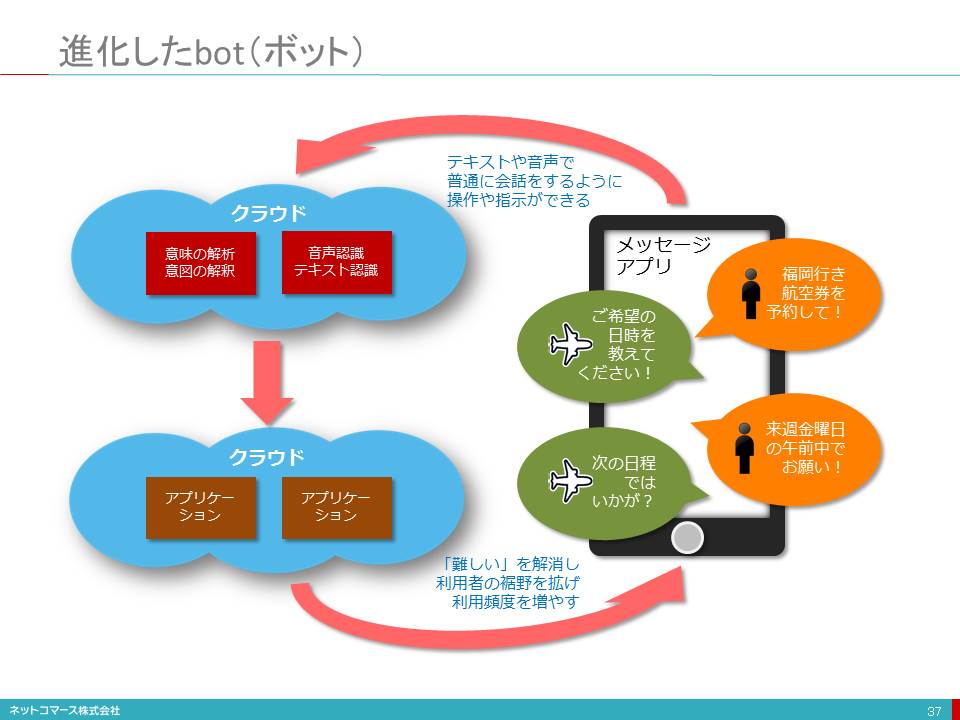
進化したbot(ボット)
【図解】コレ1枚で分かる「bot(ボット)」
「来週の金曜日のお昼頃に福岡に到着できる羽田からの航空券を予約して。」
「来週の金曜日というと、〇月〇日のことですね。ご希望の航空会社はありますか?」
「できればいつも使っているところで予約してみてくれないか。もし空いていなければ、他でも構わないよ。」
「以下のフライトでは如何でしょうか?」
【予約可能なフライト一覧を示す】
「それじゃあ、XXX123便を予約して。」
「承知しました。座席はどちらがいいでしょう。いつもご希望される窓側はいっぱいですから、通路側でもいいですか?」
「じゃあ、それでお願いします。できれば、前の方でね。」
「承知しました。支払いはいつものクレジットカードでいいですね。」
「いいよ。」
「予約しました。確認メールを送りましたので、ご確認下さい。」
あなたの秘書とやり取りをしている訳ではありません。FacebookやLineといったスマートフォンのメッセージ・アプリでのやり取りです。
様々なオンラインサービスを、普段使い馴れている「テキスト(文字)・メッセージ」アプリを使い、日常の対話のように利用できる仕組みが登場しています。「bot(ボット)」と呼ばれるこの仕組みは、ITと人との係わり方を大きく変えてしまうかもしれません。
このbotを使ったオンラインサービスには航空券の予約以外にもいろいろと考えられています。
商品検索とオンライン・ショッピング
銀行の取引残高の確認や振込手続き
ライブ・コンサートの検索とチケットの予約
スケジュールの確認とアポイント・メールの送信
タクシーの呼び出し
天気予報の確認
スポーツの対戦結果の照会 など
これまで、秘書や受付担当者といった人間が仲介者となって、対話から相手の意図を確認し、処理していた作業をbotが代わりにやってくれます。
botとは、「ロボット(ROBOT)」から生まれた言葉で、人に代わって作業を行うコンピューター・プログラムのことです。botが登場した当初は、次のような単純作業を行うのが一般的でした。
Webを巡回して情報を収集する
特定のタイトルや発信者のメールをTwitterやLineなどのメッセージ・アプリに転送する
決められた時間にパターン化されたテキスト・メッセージを発信する など
また、botをマルウェア(不正なことを行うソフトウェア)として、パソコンに侵入させ機密情報を搾取したり、他人のパソコンを乗っ取って第三者にサイバー攻撃をしかけたりといった用途にも使われています。
最近では、冒頭で紹介したように、
人間が日常使っている言葉や表現を理解する
曖昧な表現から意図をくみ取る
日常の会話で使われる自然な表現で応答する
といったことを、人工知能の技術を使って実現したbotが登場しています。また、テキストではなく音声を認識させる技術を組合せ、音声による会話で様々な処理をしてくれるものもあります。
このような「進化したbot」が使われる以前からグラフィカルな操作画面(GUI:Graphical User Interface)を使って、操作を簡単に、直感的に行えるような取り組みは行われてきました。
しかし、操作の1つひとつにルールが定められているうえに、アプリごとに操作の違いがあって、必ずしもうまくいっているとは言えません。
一方、テキストや音声での対話であれば、普通に会話をするように操作や指示ができるようになります。そうなれば、ITは「難しいから使えない」や「怖いから使いたくない」と考えている人たちの壁を引き下げ、利用者の裾野は広がり、利用の頻度も高まります。
この技術はオンラインサービスばかりではありません。家電製品や自動車などのモノの操作にも使われはじめています。例えば、
カーナビ:目的地の検索や設定
エアコン:温度調整
テレビやビデオ:番組検索や録画予約 など
「進化したbot」はそんな「難しいIT」と「自然な人間」を仲介してくれる仕組みとして、ますます普及してゆくでしょう。
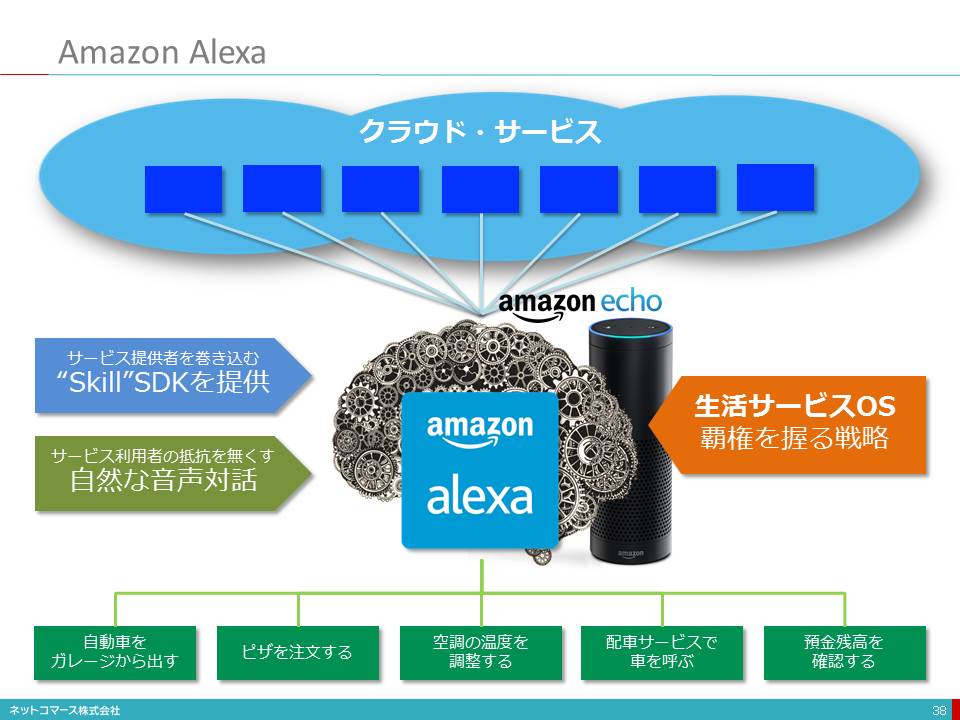
Amazon Alexa
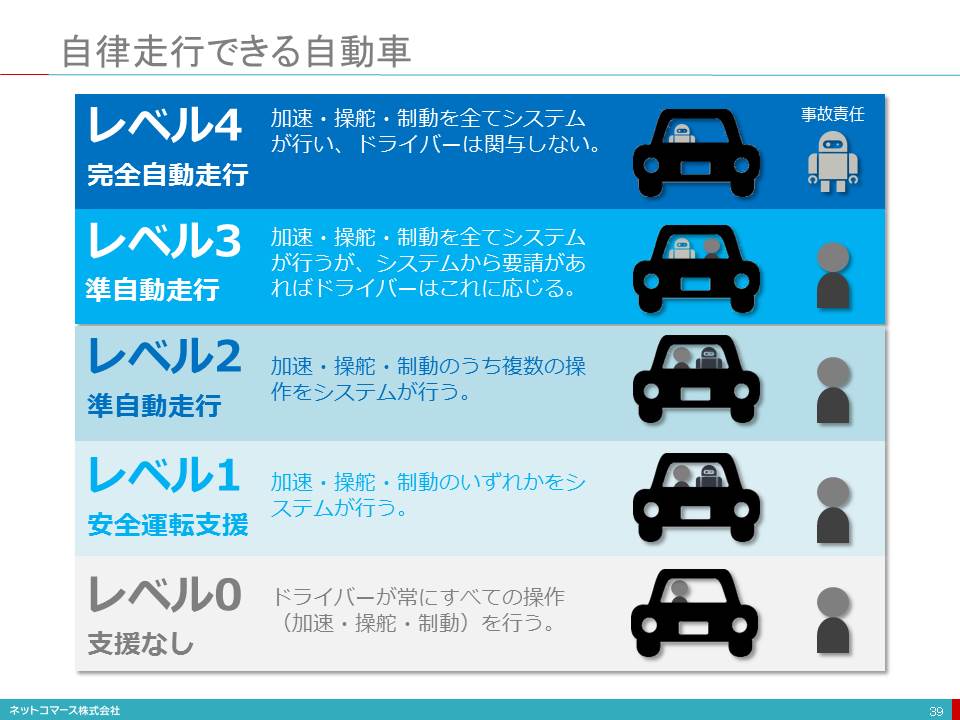
自律走行できる自動車
自動運転車の自動化のレベルについては、以下のように定義されています。
【レベル0】ドライバーが常にすべての操作(加速・操舵・制動)を行う。
【レベル1】加速・操舵・制動のいずれかをシステムが行う。
【レベル2】加速・操舵・制動のうち複数の操作をシステムが行う。ドライバーは常時、運転状況を監視し、必要に応じて操作する必要がある。
【レベル3】加速・操舵・制動をシステムが行うのでドライバーは運転から解放されるが、システムから要請があればドライバーはこれに応じる必要がある。
【レベル4】完全自動運転。加速・操舵・制動を全てシステムが行い、安全に関わる運転操作と周辺監視にドライバーは全く関与しない。
事故責任はレベル3までは運転者、レベル4は自動車になると考えられています。
このような自動車の登場により、次のような効果が期待されています。
交通事故の多くは運転者のミスや無謀な行為に起因する場合がほとんどで、運転操作を機械に任せることで交通事故を減らすことができる。
相互に速度を確認しながら走行するので渋滞が解消される。
労働人口の減少により運送従事者も減りつつある。この労働力を置き換えることで輸送力を維持・確保し、経済規模を維持できる。
過疎地域で、公共交通機関に代わる輸送手段を低コストで提供できる。
一方で、ドライバーを対象とした自動車保険は必要なくなり、長距離輸送時の休憩場所や宿泊施設は、その需要を減少させてしまう可能性があります。
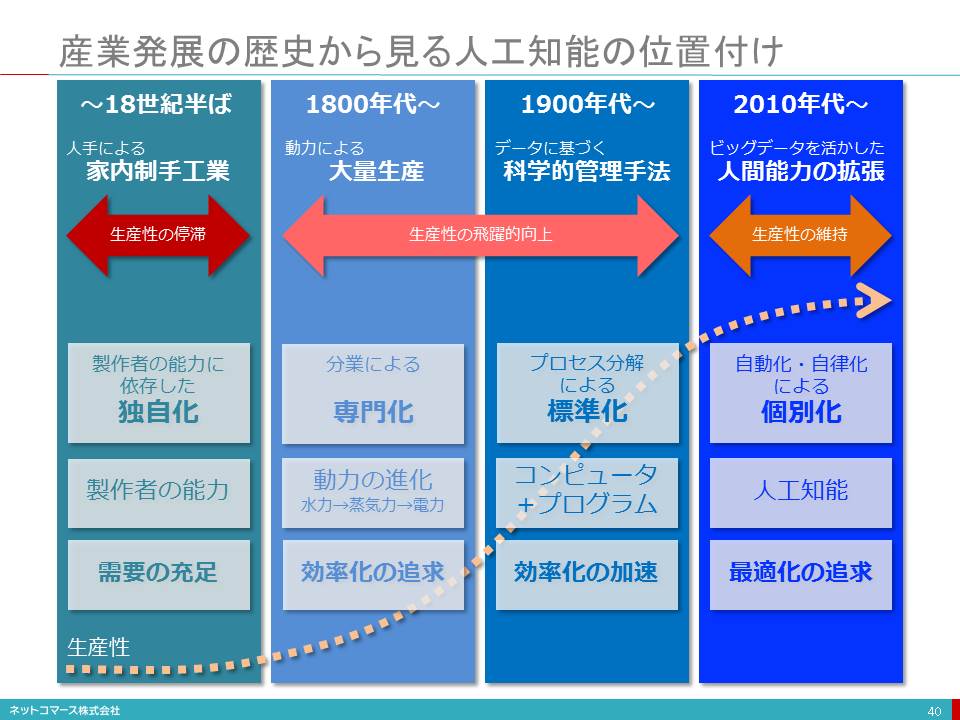
産業発展の歴史から見る人工知能の位置付け
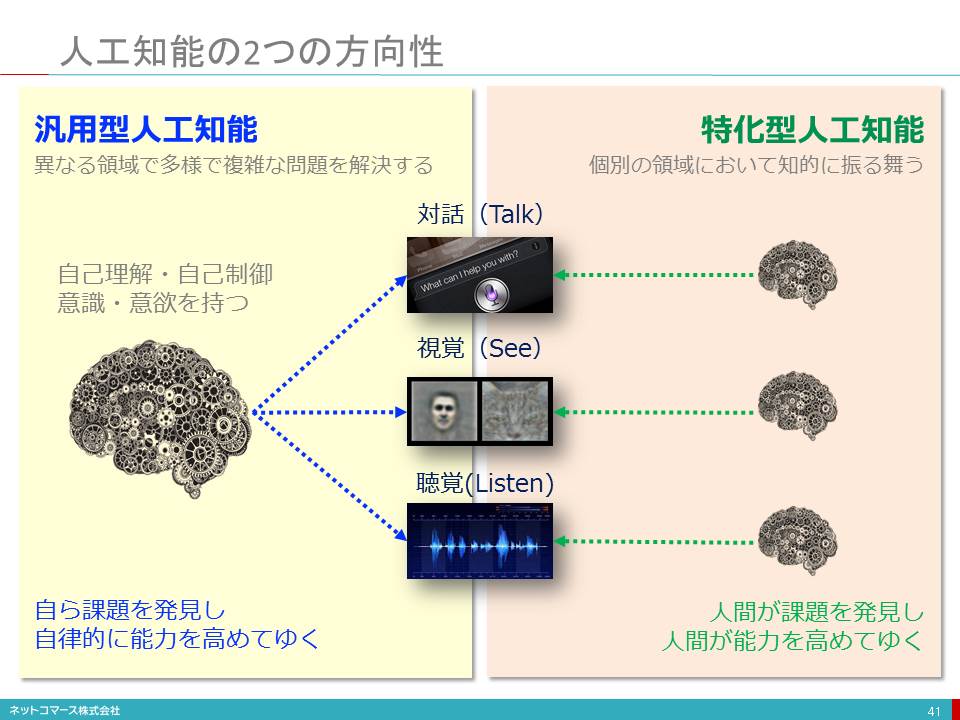
人工知能の2つの方向性
【図解】コレ1枚でわかる特化型人工知能と汎用型人工知能
人工知能の進化には、ここ数年目を見張るものがあります。例えば、画像認識では、画像の中に何が写っているかを識別する能力は、既に人間の能力を超える成果が示されています。その技術を使って、CTやレントゲンの映像から病巣を見つけ出す、あるいは防犯カメラに写った来店客の挙動から窃盗の可能性を察知するなどの実用例も登場しています。また、音声認識では、異なる言語同士の対話をリアルタイムで翻訳するサービスが登場しました。さらに、対話応答の分野では、AmazonのEchoやAppleのSiriのように自然な言葉で語りかけるだけでエアコンを操作する、オンラインで買い物をする、好きな音楽を再生するなどのことができるようになっています。
このように、人工知能は特定の知的作業領域において、既に人間の能力を凌駕するほどの実力を示しています。
しかし、その成果は、ここに示したような特定の知的作業を専門にこなす「特化型人工知能」です。
人間のようにひとつの脳で画像認識や音声認識、対話応答ができ、それらを組み合わせた高度な知的作業をこなせる能力はありません。また、人間の脳には自分が何ものかという「自己理解」、自分が何をしているのかが分かる「意識」、興味を持ち自らの行動を選択する「意欲」などがあるわけですが、そのような能力は未だ人工知能で実現できていません。
例えば、Googleの人工知能Alpha Goが囲碁の世界チャンピオンに勝ちましたが、Alpha Go自身が、その勝利を励みとして自らの能力を他の分野でも活かしていこうと意欲を持ち、自らに課題を課して能力を拡げ、磨いてゆこうという「意志」は持ちません。
Alpha Goは、囲碁という分野では人間を凌駕する能力を発揮した「特化型人工知能」ですが、だからといって人間の脳の機能を全て代替できるわけではないのです。
ただ、人間の脳全体の仕組みを解明し、同様の機能を持つ「汎用型人工知能」を実現しようという取り組みもすすんでいます。将来的には、意志を持ち自ら課題を発見し、自律的に能力を高めてゆく人工知能が登場するかもしれません。ただ、いまの段階では、まだまだハードルが高いのも現実と言えるでしょう。
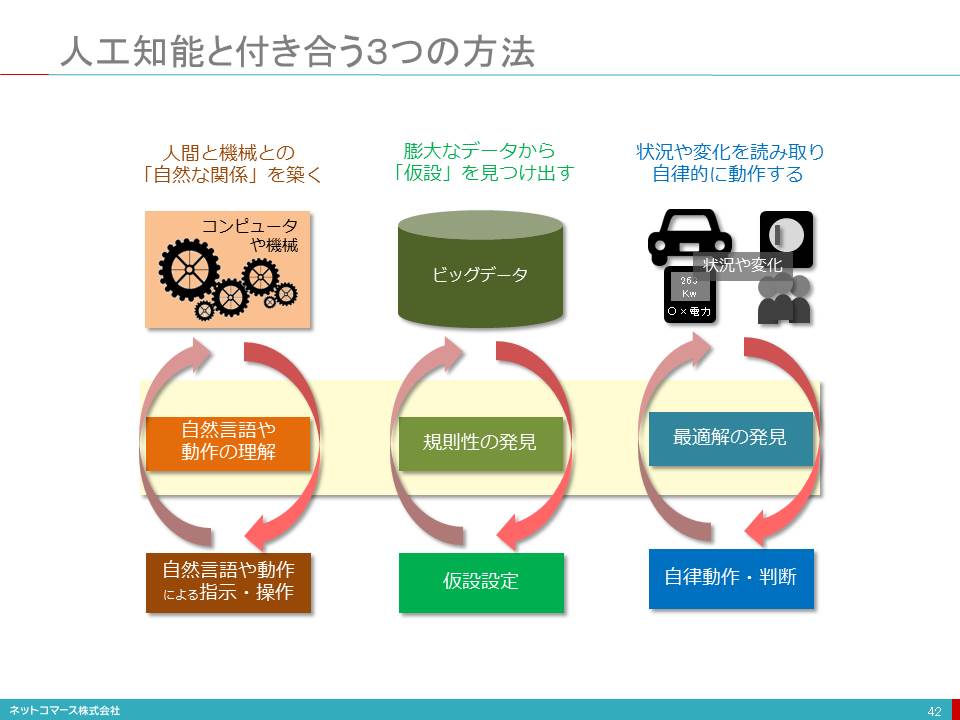
人工知能と付き合う3つの方法
では、そんな人工知能とどう付き合えばいいのでしょうか。
■■■■人間と機械との「自然な関係」を築く
Amazonが「Echo」というネット接続機能付きスピーカー端末を米国で発売しています。このEchoには、「Alexa」という人工知能が搭載され、話しかけると音声を認識し、指示されたとおり処理してくれます。例えば、Amazonのショッピング・サイトとつなぎ、「この商品をお気に入りに追加して」、「(商品名)を注文して」、「(作家名)の最新作をKindleに入れておいて」といえば、それで済んでしまいます。また、AlexaはAmazonの「Fire TV」にも組み込まれて、「スターウォーズの最新作を見せて」と指示することもできるようになるそうです。さらに照明や空調の制御までできるようになっています。
外部サービスとの連携も期待されており、配車サービス「Uber」とつながれば、「車をよこしてくれ」というだけで自動車の手配をしてくれるようになるでしょう。また音楽配信サービス「Spotify」とつながれば、「(アーティスト名)の音楽を流して」などと指示すればその音楽を探して流してくれます。
さらに「キット、ガレージから出ておいで」とEchoに話しかけると、ガレージの扉が開いて電気自動車の「TESLA」が出てくるシーンもビデオで紹介されています。ちなみに「キット」とは1980年代に米国でTV放映されたドラマ「ナイトライダー」に登場する人工知能(?)搭載の自動車の名前です。
このような自然な対話で指示ができるようになれば、難しい操作や面倒なキーボード入力は不要になり、IT利用の裾野は大きく広がるでしょう。そんな楽に使えるならそのサービスを使おう、その製品を買おうと言うことにもなります。
このような人間と機械との「自然な関係」を築こうというのが人工知能の役割の1つです。
■■■■膨大なデータから「仮設」を見つけ出す
ソーシャル・メディアやIoTによって集められた膨大なデータから価値ある情報や洞察を見つけようというのも人工知能の得意とするところです。
データは膨大であればあるほど、精緻で網羅的に現実を写し取っています。しかし、それは同時にそれを解釈し整理することを難しくします。この矛盾を解決してくれるのが人工知能です。膨大なデータに潜む規則性や構造を見つけ出してくれます。
かつてコンピューターは人間が立てた仮説に基づき処理フローを描き、それに従ってプログラムを作っていました。例えば、「こういう手順で仕事を進めれば、仕事の効率は良くなるはず」と経験者の知見や体験を踏まえて仮説を立てて、それを前提にプログラムを書き処理させることで効率を上げてきたのです。しかし、そのやり方が最適なのかどうかは、かならずしもわかりません。
一方、人工知能は、その仮説を膨大なデータから見つけ出してくれます。これまでのやり方とは正反対のアプローチです。
データに裏付けられた仮説は時にして人間の経験や勘と一致しないこともあります。しかし、思いも寄らなかった「人工知能が膨大なデータを解析して導いた最適解」を実際に試してみたら「人間の経験や勘から導いた最適解」よりも優れていた結果が出てしまったといった事例が数多く報告されています。
Alpha Goの場合も同様で、人間の最高の英知を打ち負かしたとすれば、それは紛れもなく「最適解」だったのです。しかし、人間の経験や勘がうまく説明できないように、人工知能もなぜそのようになったかを教えてくれません。そこで、プロ棋士たちは、Alpha Goがなぜそんな手を打ったのかを考え、これまでの常識を上書きしようとしているそうです。人工知能の進化が人間の進化を促しているとも言えるでしょう。そんな共進化の役割を人工知能は果たしてくれるのかもしれません。
■■■■状況や変化を読み取り自律的に動作する
モノそのものや周囲の状況、あるいはその変化を学習し、最適解を見つけ出し、自身で判断・動作する自律化の能力を実現してくれるのも人工知能です。
例えば、自動運転自動者や自ら職人技を身につける産業用ロボット、自動で土木工事をしてくれる建設機械などは、そんな自律化の適用例です。
これまでは人間がやらなければならなかった判断を人工知能が行い、その機能が組み込まれたロボットが自律的に行動するといったことが、身近なものになってゆくでしょう。
■■■■限界を理解して、その価値を最大限に利用する
AmazonのEchoやGoogleのAlpha Goなど、人間の能力に匹敵するかそれ以上の能力を人工知能は発揮します。しかし、現実を冷静に見れば、音声認識、画像認識、対話応答、自動翻訳などの「特定の知的作業」の中のことであり、それらを組み合わせた「総合的な知的作業」となると、まだまだ課題は残されています。
例えば、「こういうことをしたいが、どのような技術を組み合わせれば、実現できるだろうか」を考え、その組合せを実現する能力は人工知能にはありません。
将来、そのような人工知能が実現するかどうかは分かりませんが、当面はそのようなことを不安に思うより、既に実現している現実的な能力や役割に注目し、自社のサービスや商品に取り込んでゆくことを考えてゆくべきなのです。
人工知能に置き換えられる職業と置き換えられない職業
技能や経験の蓄積に依存し、パターン化しやすく定型的で、特定の領域を越えない能力
感性、協調性、創造性、好奇心、問題発見力など非定型的で、機械を何にどう使うかを決められる能力
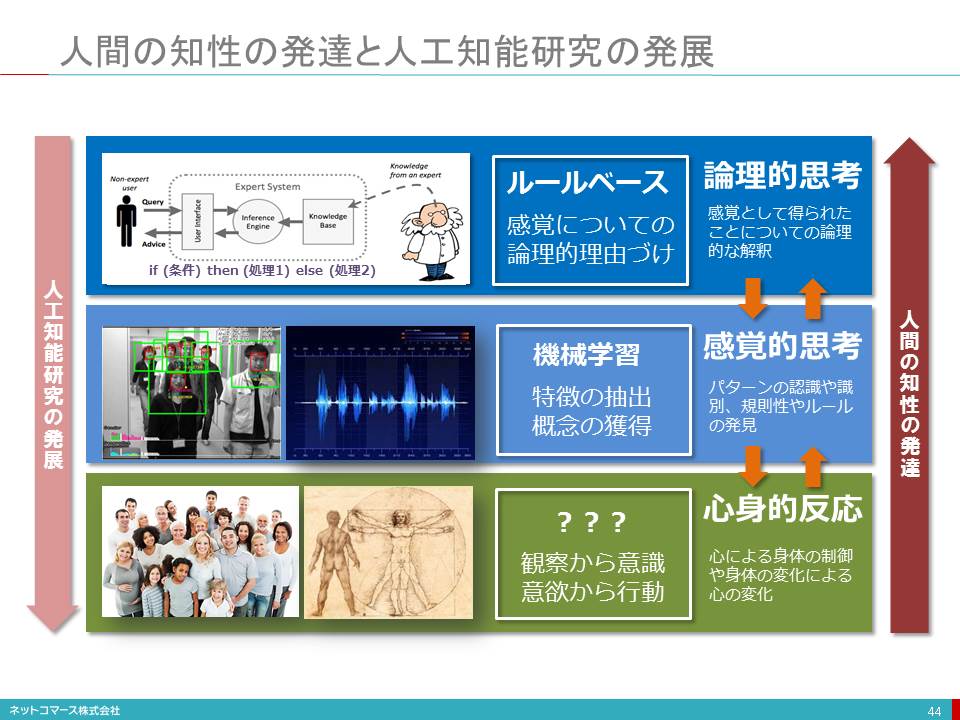
人間の知性の発達と人工知能研究の発展
【図解】コレ1枚で分かる知性の発達と人工知能の発展
人間の知性の発達
人間は生を受けると様々な刺激を外界から受けることになります。その刺激を観察し、感じることを繰り返し、自分がいま何をやっているか、いまはどんな状況なのかが自分でわかる心の働き「意識」を育ててゆきます。そんな意識は好奇心を生みだし、触ったり、見たり、しゃぶったりといった行動を促し、観察の方法や範囲を拡げてゆきます。そういうことを積み重ねて、人間は心と身体の関係を無意識のうちに築いてゆくのでしょう。
そういう心と身体の働きを繰り返し使ってゆくうちに、自分の周りにある様々な事象を感覚的に捉えるようになります。ものごとには特徴や規則性があることが分かるようになり、それを認識、識別できるようになるということです。例えば、お母さんの顔、自分か好きなオモチャ、ミルクを飲むということに特徴や規則性を見出し、理屈ではなく感覚的に捉えるようになります。つまり、概念を獲得してゆくのです。
このように感覚的に得られた概念に、次第に解釈や理由付けを与えられるようになります。論理的思考能力の発達です。この能力の発達は言語能力の発達を促し、それはさらに論理的思考能力をも高めてゆきます。
このように人間の知性は、心身的反応から感覚的思考へ、そして論理的思考へと発達してゆくのです。
人工知能の発展
一方、人工知能の研究はこれとは逆の発展を遂げてきたようです。1950年代に入りコンピューターが使えるようになると、「数を操作できる機械は記号も操作できるはず」との考えから、コンピューターを使った思考機械の研究が始まります。
1960年代に入り、記号処理のためのルールや数式をプログラム化し思考や推論など人間が行う論理的な「知的活動」と同様のことを行わせようという研究が広がりを見せました。しかし、当時のコンピューター能力の低さ、また、記号処理のルールを全て人間が記述しなければならず、限界が見え始め、実用に使える成果をあげることができないまま1970年代に入り、人工知能研究は冬の時代を迎えます。
1980年代に入り、「エキスパートシステム」が登場します。これは、特定分野に絞り、その専門家の知識やノウハウをルール化し、コンピューターに処理させようというものでした。例えば、計測結果から化合物の種類を特定する、複雑なコンピューターのハードウェアやソフトウェアの構成を過不足なく組み合わせるなど、特定の領域に限れば、実用で成果をあげられるようになったのです。しかし、これもまた辞書やルールを人間が全て与えなくてはならず、限界に行き当たることになります。ものごとを論理的に記述し、知的処理を機械に行わせようという取り組みは再び頓挫することになったのです。
2000年代に入り、様々な、そして膨大なデータがインターネット上に集まるようになりました。また、コンピューターの性能もかつてとは比べられないほどに性能を向上させてゆきました。そこで、特定の業務や分野でのデータを解析し、その結果から分類や区別、判断や予測を行うための規則性やルールを見つけ出す手法「機械学習」が登場します。
「機械学習」以前は、先にも説明の通り人間がルールを記述し「論理的に思考」させようというアプローチが主流でした。しかし、「機械学習」はデータの相互の関係から規則性あるいはパターンを見つけ出そうというもので、「感覚的に思考」させようというアプローチと言えるでしょう。
現在、最新の脳科学の研究成果を取り入れ、この感覚的思考の精度を高めようという機械学習のアプローチ「ディープラーニング(深層学習)」に注目が集まっています。この新たな取り組みは、これまでの人工知能の研究成果の限界をことごとく打ち破っています。そして、実用においても、これまでにない多くの成果をあげつつあります。
このように人工知能の研究は、論理的思考から感覚的思考へと発展してきたと言えるでしょう。しかし、心と身体の状態と、その間の関係、つまり非物質的である心というものが、どうして物質的な肉体に影響を与えることができるのか、そしてまたその逆もいかに可能なのかは、解明されていません。また、意識や意欲なども同様に、それ自体が解明できておらず、コンピューター上で実装しようがないのです。
このように見てゆくと、人工知能研究の次のテーマは、「心身問題の解決」ということになるのでしょうか。事実、この問題に取り組む研究者たちもいますが、いまだ決定的な解決策は見出ていません。さて、これからどんな成果が出てくるのか、興味は尽きません。
第3章 クラウドコンピューティング
コレ1枚でわかるクラウドコンピューティング
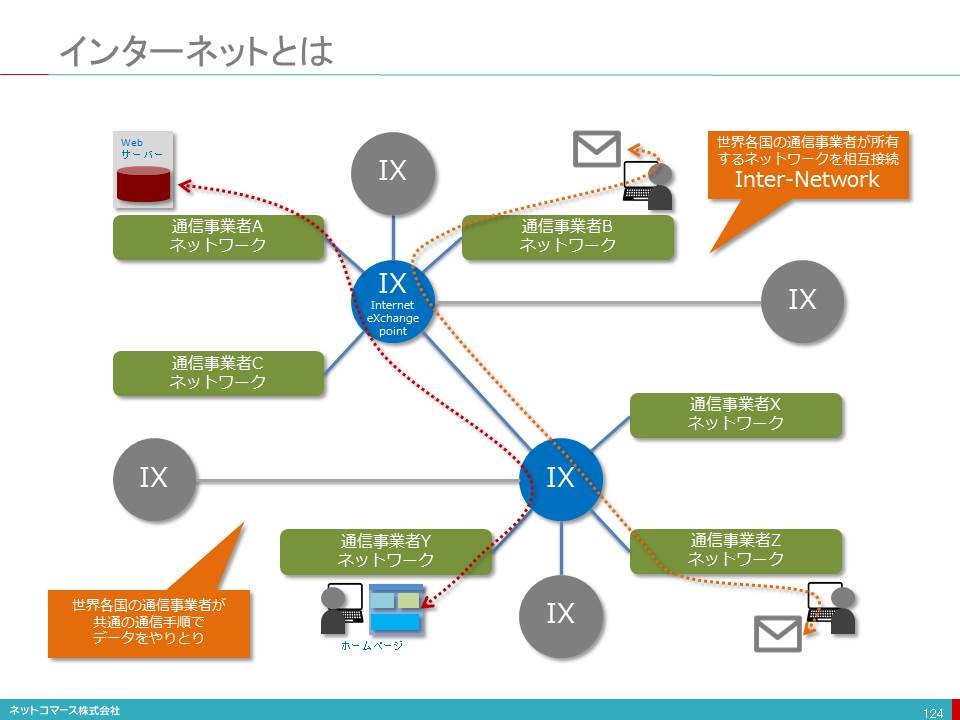
「クラウド・コンピューティング」という言葉を知らない人は、もはやいないほどに、広く定着しました。この言葉が使われるようになったのは、2006年、当時GoogleのCEOを努めていたエリック・シュミットの次のスピーチがきっかけだと言われています。
「データもプログラムも、サーバー群の上に置いておこう。そういったものは、どこか 雲(クラウド)の中にあればいい。必要なのはブラウザーとインターネットへのアクセス。パソコン、マック、携帯電話、ブラックベリー(スマートフォン)、とにかく手元にあるどんな端末からでも使える。データもデータ処理も、その他あれやこれやもみんなサーバーに、だ。」
彼の言う雲(クラウド)とは、インターネットを意味しています。当時、ネットワークの模式図として雲の絵がよく使かわれていたことから、このような表現になりました。
改めて整理してみると、次のようになるのでしょう。
インターネットの向こうに設置したシステム群を使い、
インターネットとブラウザーが使える様々なデバイスから、
情報システムの様々な機能を使える仕組み。
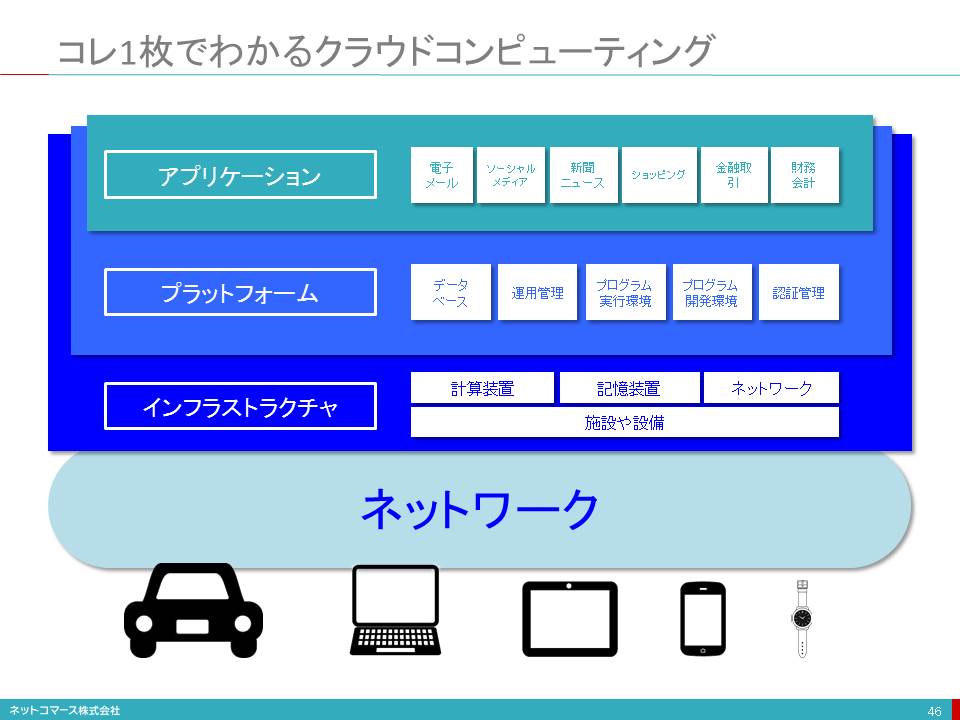
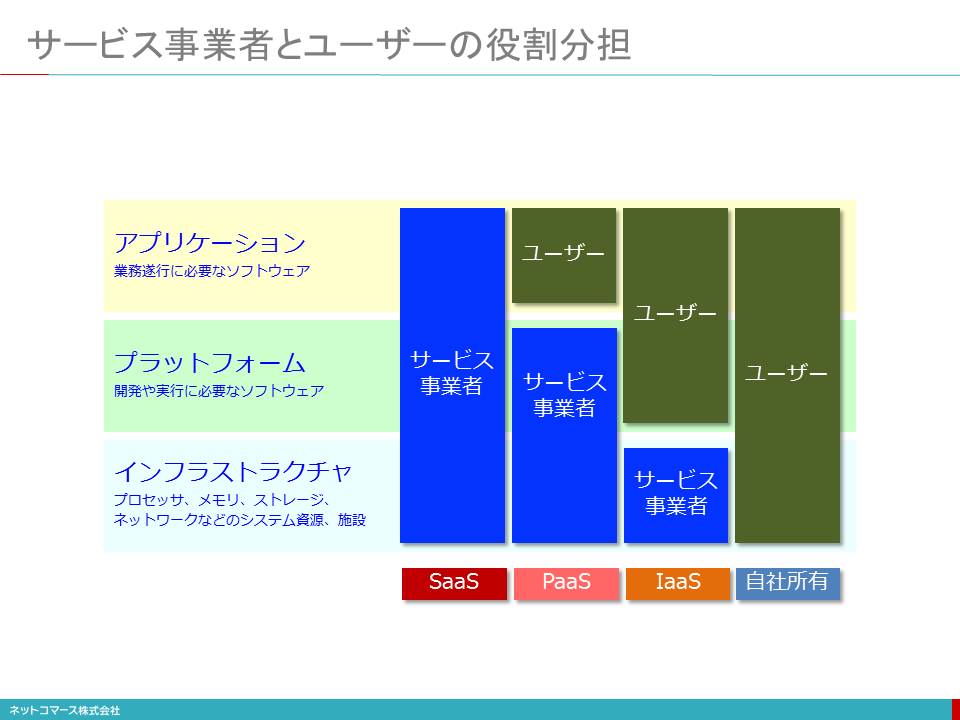
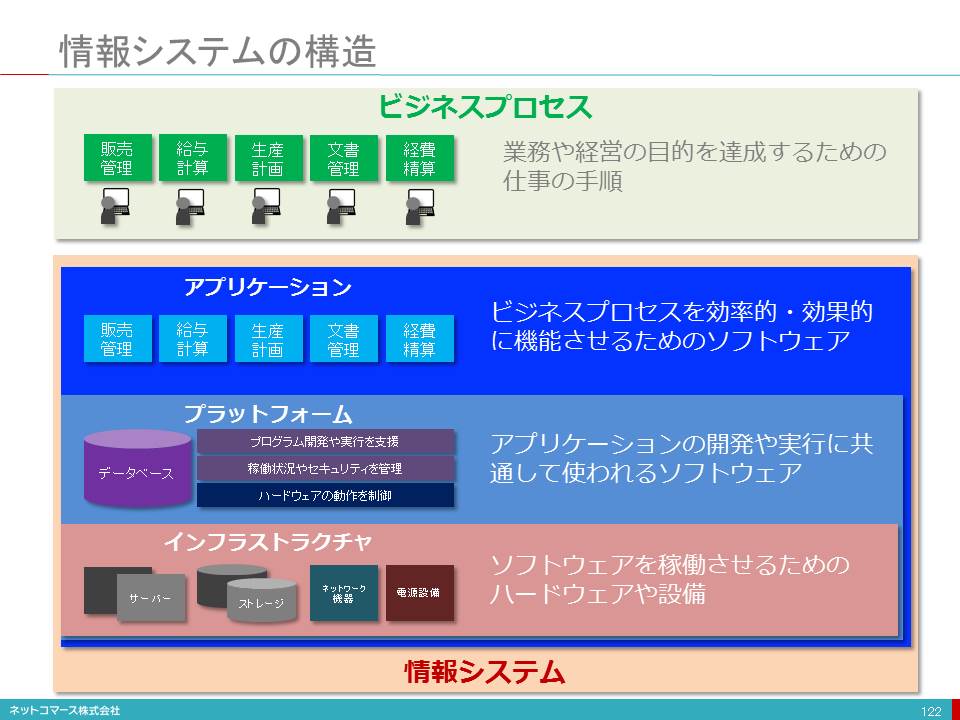
「インフラストラクチャー」とは、業務を処理するための計算装置、データを保管するための記憶装置、通信のためのネットワーク、それらを設置し、運用するための施設や設備のことです。「プラットフォーム」とは、様々な業務で共用して利用されるデータベースや運用管理などのソフトウェアのことです「アプリケーション」とは、私たちが最も身近に接する業務サービスのことです。
それでは、これらから「クラウド・コンピューティング」について詳しく見てゆくことにしましょう。
「自家発電モデル」から「発電所モデル」へ
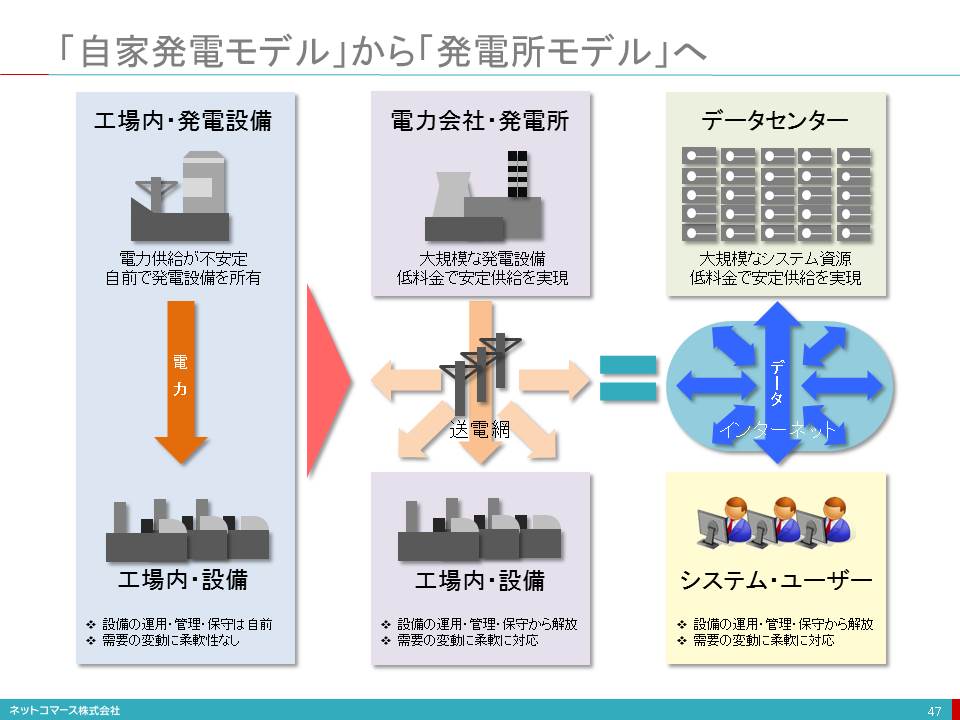
かつて電力が工業生産に用いられるようになった頃、電力を安定的に確保するために自家発電設備を持つことは常識とされていました。しかし、発電機は高価なうえ、保守・運用も自分たちでまかなわなくてはならず、効率の悪いものでした。また、所有している発電機の能力には限界があり、急な増産や需要の変動に臨機応変に対応できないことも課題となっていました。
この課題を解決したのが、発電所を構える電力会社でした。技術の進歩とともに、電力会社は送電網によって電力を安定供給できるようになり、効率も上がって料金も下がってきました。また、共用によって、ひとつの工場に大きな電力需要の変動があっても、全体としては相殺され、必要な電力を需要の変動に応じて安定して確保できるようになりました。そうして、もはや自前で発電設備を持つ必要がなくなったのです。
これを情報システムに置き換えてみければ、何が起こっているかかが、想像がつくのではないでしょうか。
発電所は、コンピュータ資源を設置したデータセンターです。送電網は、インターネットです。需要の変動に対しても、能力の上限が決まっている自社システムと異なり、柔軟に対応することができます。
また、電力と同様に、利用した分だけ支払う従量課金ができるので、大きな初期投資を必要としません。これもまた、発電機を購入しなくてよくなったことと同じです。
コンセントにプラグを差し込むように、インターネットに接続すればシステム資源を必要な時に必要なだけ手に入れられる時代を迎えたのです。情報システムを「所有」する時代から「使用」する時代への転換です。
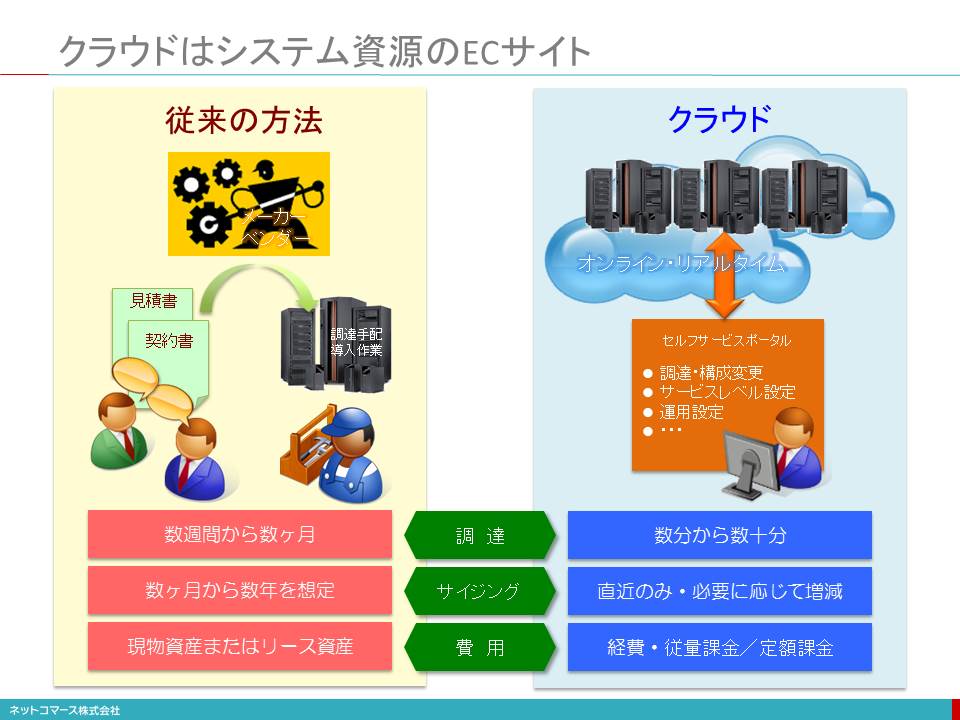
クラウドはシステム資源のECサイト
情報システムを自社資産として「所有」することから外部サービスとして「使用」するようになると、システム資源の調達や変更が、簡単に行えるようになります。例えば、クラウド以前の「所有」の時代は、次のような多くの手順を踏まなくてはなりませんでした。
リース期間に合わせ将来の需要を予測してサイジングする。
ITベンダーにシステム構成の提案を求め見積を依頼し価格交渉を行う。
稟議書を作成して承認・決済の手続きを行う。
決定したITベンダーに発注する。
ITベンダーはメーカーに調達を依頼する。
調達した機器をキッティングする。
ユーザー企業のオンサイトに据え付け、ソフトウェアの導入や設定を行う。
・・・
そのため、調達には数週間から数ヶ月かかりました。一方、クラウドであれば、実に簡単です。
当面必要なリソースを考えてサイジングをおこなう。
クラウド・サービスのWebに表示されるメニュー画面(セルフ・サービス・ポータル)からシステム構成を選択する。
その画面からセキュリティのレベルやバックアップのタイミングなど運用に関わる項目を設定する。
調達ボタンを押す。
この間、数分から数十分といったところでしょう。あっという間です。使用量が増える、運用の要件が変わるなど、変更があれば、その都度メニュー画面で設定し直すことができるので、予測できない未来まで考えて、サイジングする必要はありません。また、電気代のように使用量に応じて支払う料金制度ですから、必要なくなれば、いつでも辞められますので、初期投資リスクを抑えることができます。つまり、クラウドは、「システム資源を調達するためのECサイト」なのです。
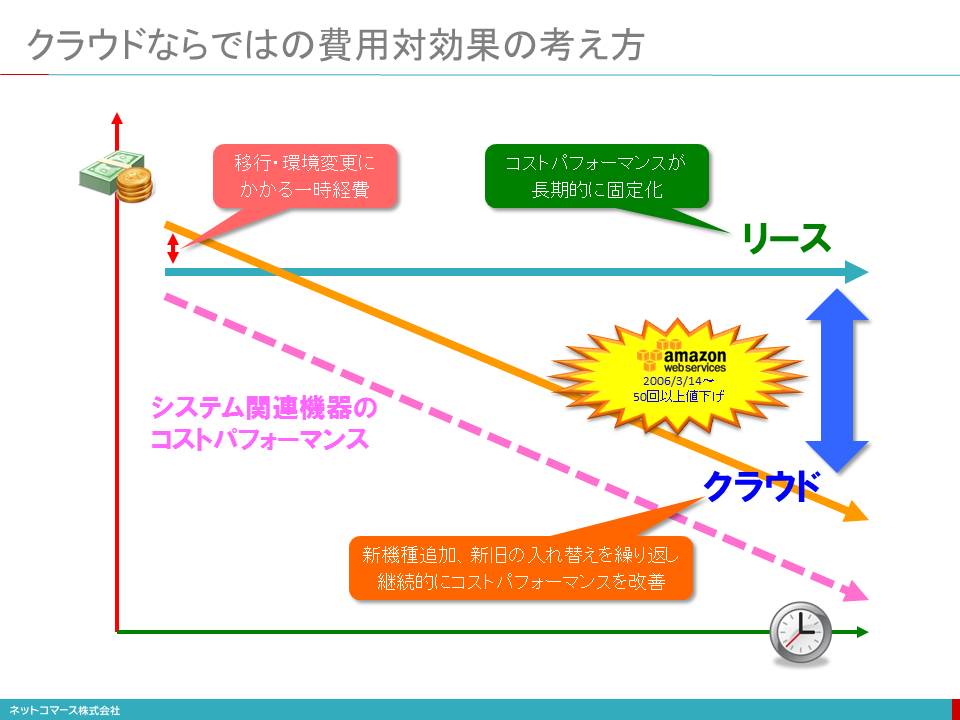
クラウドならではの費用対効果の考え方
クラウドの魅力として、費用対効果の高さがあります。従来の「所有」を前提としたシステム資源は、調達すれば資産となり一定期間で償却しなければならず、その間、新しいものに置き換えることはできません。しかし、システム機器の性能は、「18か月ごとに2倍になる」というムーアの法則に当てはめれば、5年間で10倍になります。つまり資産化するとコストパフォーマンスは購入時点から劣化し始め、償却期間中は改善の恩恵を享受できないのです。
これは、ハードウエアに限らず、ソフトウェアもライセンス資産として保有してしまえば、より機能の優れたものが出現しても、簡単には置き換えることができません。また、バージョンアップの制約や新たな脅威に対するセキュリティ対策、サポートにも問題をきたす場合があります。
一方クラウドは、共用が前提です。クラウド事業者は、自社のサービスに合わせ無駄な機能や部材を極力そぎ落とした特注の標準仕様の機器を大量に発注し、低価格で購入しています。さらに、徹底した自動化により人件費を減らしています。また、継続的に最新機器を追加導入し、順次古いものと入れ替え、コストパフォーマンスの継続的改善を行っています。たとえば、世界最大のクラウド事業者であるAmazonは、2006年のサービス開始以来、40回を超える値下げを繰り返してきました。見方を変えれば、クラウドを利用すれば、使える費用が同じであれば、数年後には何倍もの資源を最新の環境で利用できるのです。
もちろん、すでに所有しているシステムをクラウドに置き換えるにはコストがかかりますが、一旦移行すれば、費用対効果の改善を長期的かつ継続的に享受できるわけです。
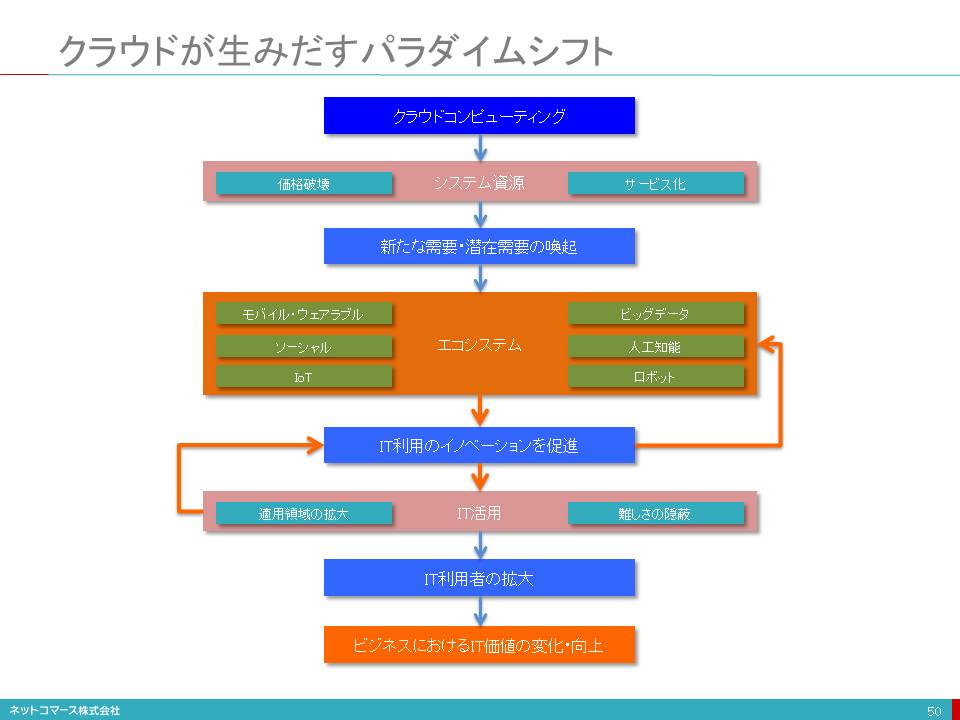
クラウドが生みだすパラダイムシフト
【図解】コレ1枚でわかるクラウドがもたらすITの新たな価値
クラウド・コンピューティングの登場により、私たちの日常やビジネスにおけるITの価値が大きく変化しつつあります。
クラウドは、システム資源の価格破壊をもたらしました。例えば、世界最大のクラウド・サービス事業者であるAWS(Amazon Web Services)は、2006年のサービス開始以来、約50回、一貫して値下げを繰り返しています。これに追従するように、MicrosoftやGoogleも値下げを繰り返し、熾烈な価格競争を展開しています。コンピューター機器の販売ビジネスでは、到底まねのできない価格競争と言えるでしょう。また、システム資源の調達や運用を従量課金型のサービスとして提供することで、ユーザー企業は、必要最小限のシステム資源を、僅かな運用管理負担で利用できるようになったのです。
かつて、情報システムを構築し使用するためには、システム資源を購入し、運用管理の専門家を雇わなくてはなりませんでした。それなりの初期投資リスクを覚悟して、取り組まなければならなかったのです。しかし、クラウドの登場によりこの常識は覆されました。そのため、これまでITの利用に二の足を踏んでいた業務領域や新規事業への適用が拡大しつつあります。
また、スタートアップ企業にとっては、「失敗のコスト」が大きく低減し、容易にチャレンジできる環境が与えられるようになりました。
新規事業の成功確率は、1千回に数回といわれるほどハードルの高いものです。そのため、初期投資リスクが大きな時代には、新規事業へのチャレンジは、慎重にならざるを得ず、また、膨大なスタートアップ資金を調達しなければなりませんでした。しかし、クラウドの普及により、少ない初期投資コストで、様々なアイデアを試してみることができるようになったのです。
このように「失敗のコスト」が、低減することでチャレンジが促され、成功確率は変わらなくても、チャレンジの回数が増えることで、成功の回数も増えつつあります。その結果、イノベーションは促進され、適用業務領域を拡大しています。また、SaaSやPaaSの普及により、高度なシステム機能を1から作り込まなくてもクラウド・サービスとして利用し、これを組み合わせることで、新たなサービスを作れる時代になりました。これによりシステム開発や運用管理と言ったITの難しさは隠蔽され、IT利用者の裾野をこれまでになく拡大しつつあります。
これに伴い、ビジネスや日常におけるITの価値は、向上してゆきます。同時に、ITは、その存在自身を隠蔽化してしまうほどに、私たちの周囲や環境に溶け込む「ITのアンビエント化」をもたらしつつあると言えるでしょう。
このようにITの価値は、これまでにも増して大きくなってゆきます。しかし、このような価値を生みだすことを目的とせず、工数提供という手段を価値と捉えるビジネスは、ITの「サービス化」と、それに伴う「難しさの隠蔽」によって、ビジネス・チャンスを失ってゆくことを覚悟しなければならないでしょう。
クラウドの起源と定義
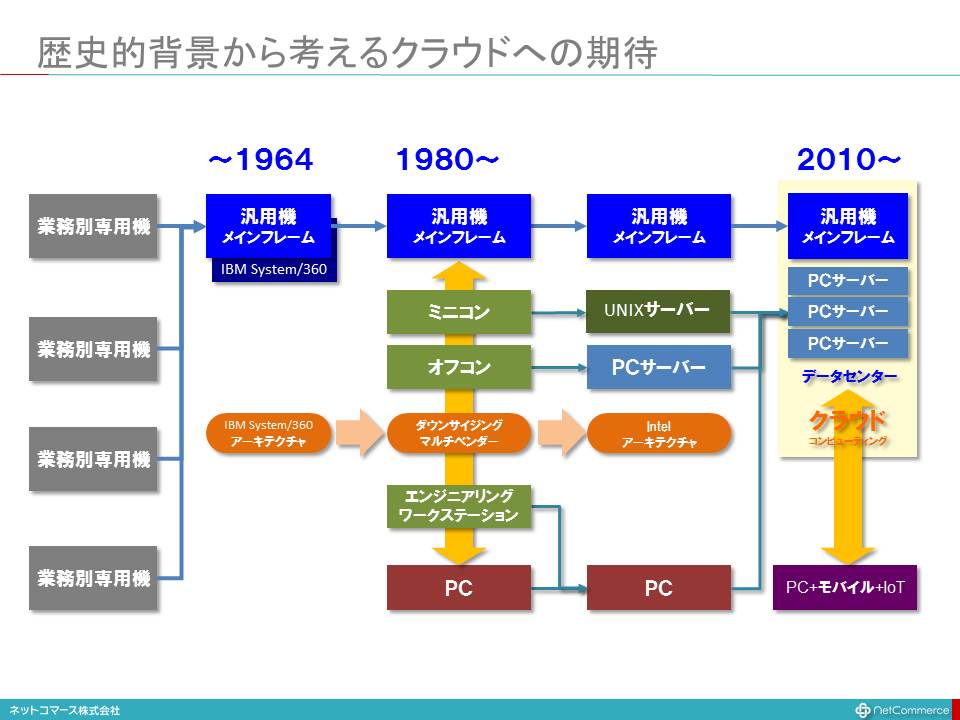
歴史的背景から考えるクラウドへの期待
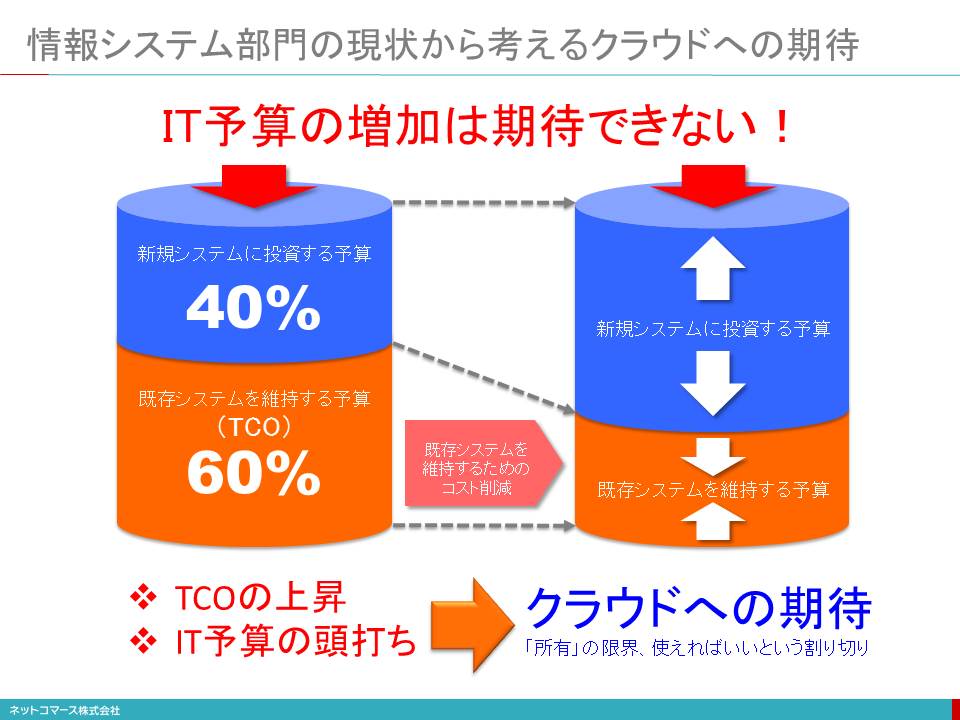
情報システム部門の現状から考えるクラウドへの期待
ITは、業務効率を高めるためには、既に欠かせないものとなっています。また、企業の成長や競争力を維持するためのグローバル展開や新規事業への進出のためにも、ITなしでは対応できません。
このように、IT利用の範囲が広がり、その重要性が高まるほどに、災害やセキュリティへの対応も、これまでにも増して強く求められるようになりました。また、モバイルやビッグ・データといった、新しいテクノロジーへの対応も業務の現場から求められています。
こんなIT需要の高まりとは裏腹に、企業内のITに責任を持つ情報システム部門は、ふたつの大きな問題を抱えています。そのひとつが、先ほど説明したTCOの増大です。
ITへの需要が高まれば、TCOが増大します。それでもIT予算が増えるのであれば、何とか対処できます。しかし、ITに関わるお金は、事業投資とはなかなか見做されず、経費として常に削減の圧力がかかっています。これが、もうひとつの問題です。
業務や経営の要請に応えたくても、「所有」している既存のシステムを維持管理するためのTCOにお金が掛かり過ぎて、応えることができません。しかも、IT予算が今後大きく増える見込みもありません。そんな問題を情報システム部門は抱えているのです。
ならば、「所有」することを辞め、自分達で、システム資源の面倒をみなければ、TCOは削減できるはずです。また、クラウドで提供されているプラットフォームやアプリケーションを使えば、開発工数の削減や、場合によっては開発さえも必要なくなります。そんな期待から、いま「使用」のクラウドへの注目が集まっているのです。
クラウドの起源と定義
「クラウド・コンピューティング」という言葉は、2006年、当時GoogleのCEOを努めていたエリック・シュミットのスピーチがきっかけで使われるようになったことは、前述のとおりです。新しい言葉が大好きなIT業界は、時代の変化や自分達の先進性を喧伝し自社の製品やサービスを売り込むためのキャッチコピーとして、この言葉を盛んに使うようになりました。そのおかげで、各社各様の定義が生まれ、市場に様々な誤解や混乱を生みだしてしまったのです。
2009年、こんな混乱に終止符を打ち、業界の健全な発展を意図し、米国商務省の配下にある国立標準技術研究所(National Institute of Standards and Technology : 通称NIST)が、「クラウドの定義(The NIST Definition of Cloud Computing)」を発表、いまでは、広く受け入れられています。この定義は、決して特定の技術や規格を意味するものではなく、考え方の枠組みとして、捉えておくといいでしょう。NISTの定義には、次のような記述があります。
「クラウド・コンピューティングとは、ネットワーク、サーバー、ストレージ、アプリケーション、サービスなどの構成可能なコンピューティングリソースの共用プールに対して、便利かつオンデマンドにアクセスでき、最小の管理労力またはサービスプロバイダ間の相互動作によって迅速に提供され利用できるという、モデルのひとつである」。
ひと言で言えば、「コンピューティング資源を必要なとき必要なだけ簡単に使える仕組み」ということです。さらに、様々なクラウドの利用形態を「サービス・モデル(Service Model)」と「配置モデル(Deployment Model)」に分類、また、クラウドに備わっていなくてはならない「5つの必須の特徴」をあげています。
それでは、これらについて、ひとつひとつ見てゆくことにしましょう。
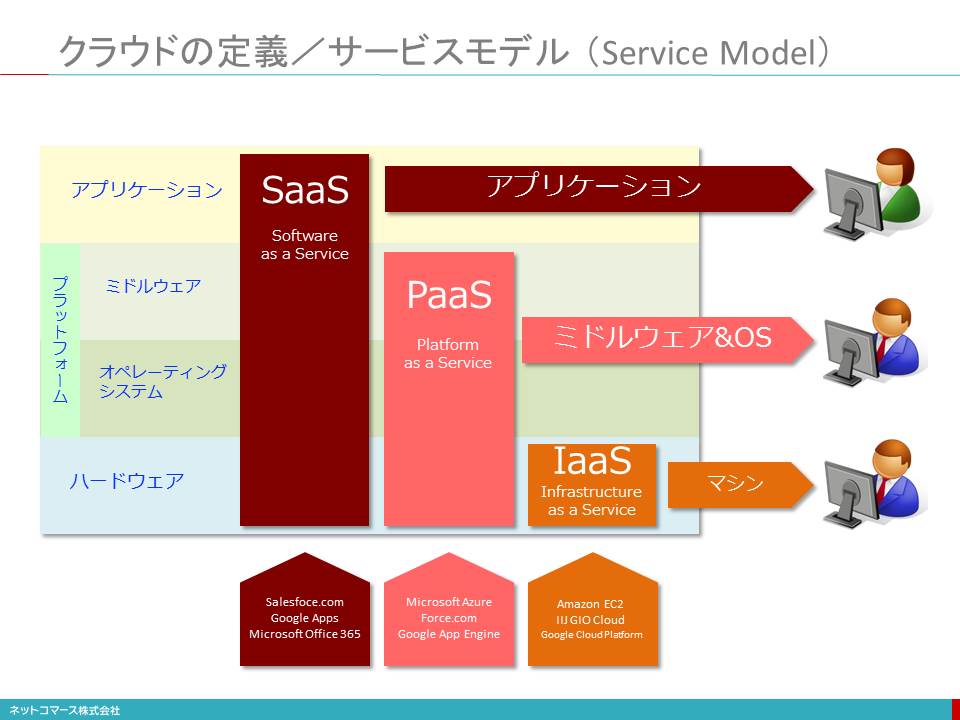
クラウドの定義/サービスモデル (Service Model)
クラウドをサービスとして提供するシステム資源の違いによって分類する考え方が「サービス・モデル(Service Model)」です。
SaaS(Software as a Service)は、電子メールやスケジュール管理、文書作成や表計算、財務会計や販売管理などのアプリケーションをネット越しに提供するサービスです。ユーザーは、アプリケーションを動かすためのハードウエアやOS、ミドルウェアの知識がなくても、アプリケーションについての設定や機能を理解していれば使うことができます。
例えば、Salesforce.com、Google Apps、Microsoft Office 365などがあります。
PaaS(Platform as a Service)は、アプリケーションを開発や実行するためのシステム機能をサービスとして提供します。データベース、開発フレームワーク、実行時に必要なライブリーやモジュールを提供します。ユーザーは、インフラ構築や設定に煩わされることなく、アプリケーションを開発し、実行することができます。
例えば、Microsoft Azure Platform、Force.com、Google App Engineなどがあげられます。
IaaS(Infrastructure as a Service)は、サーバー、ストレージなどのシステム資源を提供するサービスです。ユーザーは、自分でOSやミドルウェアを導入し、設定を行わなくてはなりません。その上で動かすアプリケーションも自分で用意します。
「所有」するシステムであれば、その都度、ベンダーと交渉し、手続きや据え付け導入作業をしなければなりません。しかしIaaSを使うと、メニュー画面であるセルフサービス・ポータルから、設定するだけで使うことができます。また、ストレージ容量やサーバー数は、必要に応じて、簡単に増減できます。そのスピードと変更に対する柔軟性は、比べものになりません。
例えば、Amazon EC2、IIJ GIOクラウド、Google Compute Engineなどがあげられます。
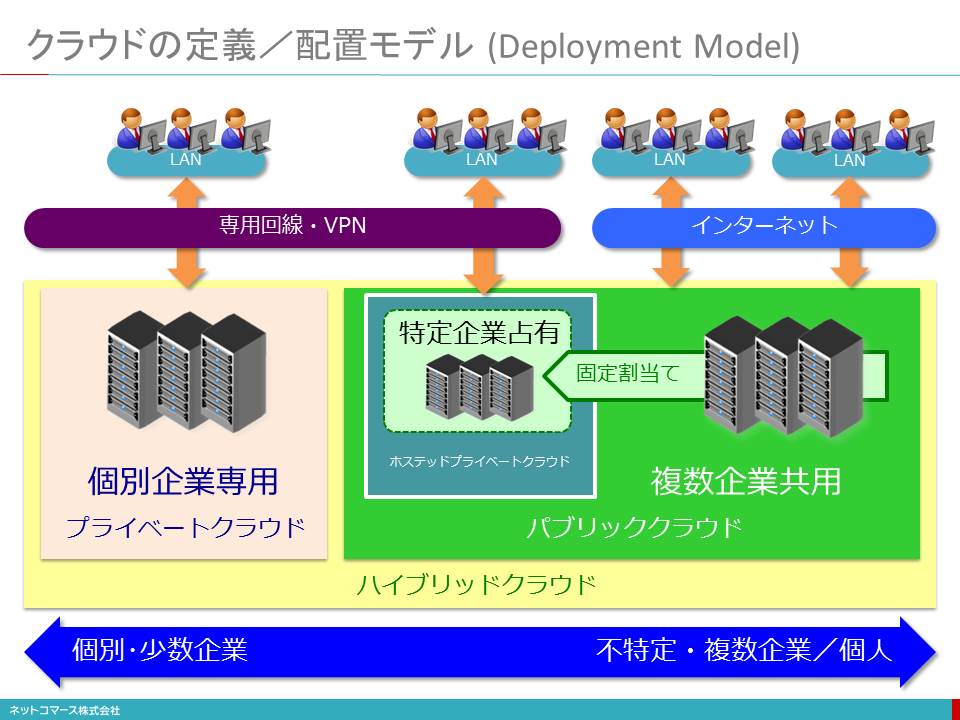
クラウドの定義/配置モデル (Deployment Model)
次は、「配置モデル(Deployment Model)」です。システムの設置場所の違いによって、分類しようという考え方です。
ひとつは、複数のユーザー企業がインターネットを介して共用するパブリック・クラウドです。これに対して、企業がシステム資源を自社で所有し、自社専用のクラウドとして使用するプライベート・クラウドがあります。
もともとクラウド・コンピューティングは、先に紹介したエリック・シュミットの言葉にもあるように、パブリック・クラウドを説明するものでした。しかし、クラウドの技術を自社で占有するシステムに使えば、利用効率を高め、運用管理の負担を軽減できるとの考えから、プライベート・クラウドという言葉が生まれました。
他にもNISTの定義には含まれてはいませんが、「バーチャル・プライベート・クラウド」または、「ホステッド・プライベート・クラウド」という言葉が、最近では使われるようになりました。
「パブリック・クラウドのコストパフォーマンスを享受したいが、他ユーザーの影響を受けるようでは、使い勝手が悪い。また、インターネットを介することでセキュリティの不安も払拭できない。しかし、プライベート・クラウドを自ら構築するだけの技術力も資金力もない。」
こんなニーズに応えようというものです。これらは、パブリック・クラウドのシステム資源の一部を特定のユーザー専用に割り当て、他ユーザーには使わせないようにし、専用線や暗号化されたインターネット(VPN: Virtual Private Network)で接続して、あたかも自社専用のプライベート・クラウドのように利用させるサービスです。
パブリックとプライベートのふたつを組み合わせて利用する形態をハイブリッド・クラウドといいます。
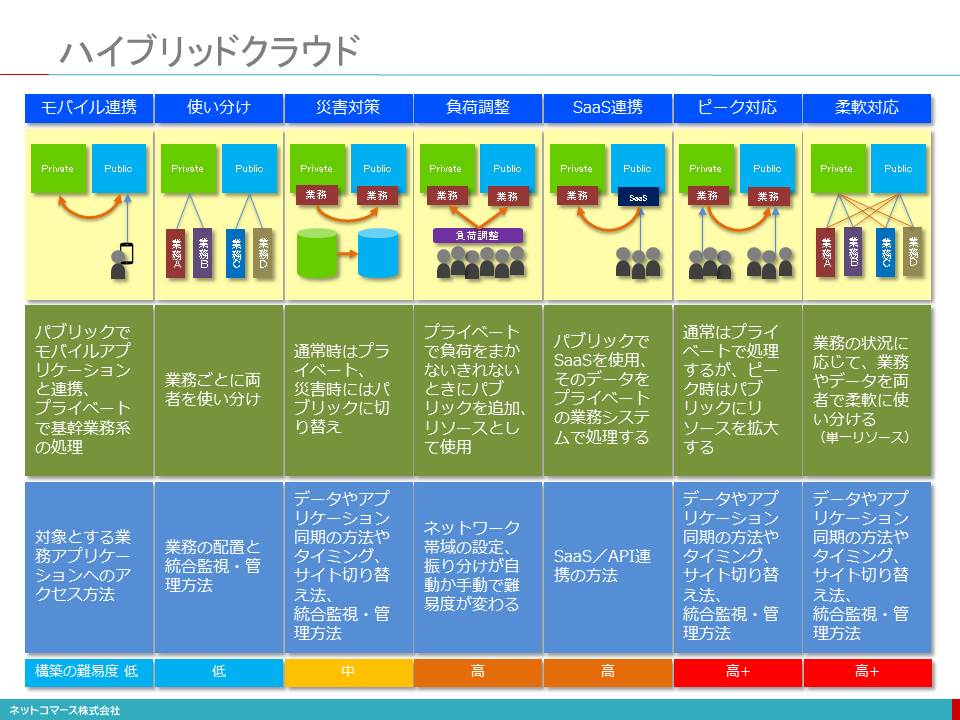
ハイブリッドクラウド
【図解】コレ1枚でわかるハイブリッドクラウド
パブリックとプライベートを組み合わせ、それぞれの得意不得意を補完し合いながら両者を使い分ければ、コストパフォーマンスの高いシステムの使い方ができます。
例えば、電子メールや情報共有などのコラボレーション機能など、自社の独自性がないものは、パブリック・クラウドのSaaSを利用し、セキュリティを厳しく管理しなければならない人事情報や個人認証は、プライベート・クラウドでおこない、その情報を使ってSaaSを利用できるようにするという使い方があります。
また、モバイルで、世界中どこからも使える経費精算サービスをパブリック・クラウドのSaaSとして利用し、そのデータを、プライベート・クラウドの自社専用の会計システムに取り込んで処理するという使い方も考えられます。
他にも、アプリケーション・システムを開発する際、社外のプログラマーと共同で作業を進めることや、開発に便利なツールを簡単に利用できるパブリックを使い、本番は自社専用のプライベート・クラウドに移して稼働させるといった使い方もあります。
さらに、災害への対応を考え、通常はプライベート・クラウドを使用し、データのバックアップや災害時の代替システムをパブリック・クラウドに置いておき、災害のためにプライベート・クラウドが使えなくなったら切り替えて使用し、業務を継続させようという使い方もあります。
このように、パブリックとプライベートそれぞれの得意をうまく組み合わせ、利便性やコストパフォーマンスの高いシステムを実現しようというのが、ハイブリット・クラウドについての一般的理解です。
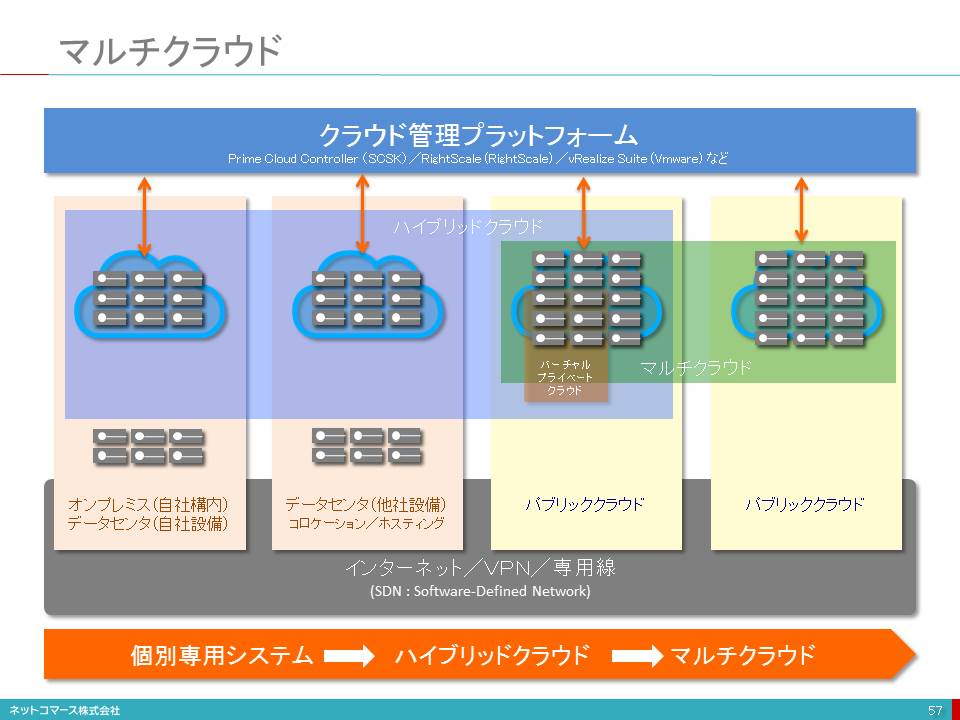
マルチクラウド
【図解】コレ1枚で分かるマルチ・クラウド
クラウド・コンピューティングとは、何かを改めて整理してみると次のようになります。
・コンピューティングリソース(ネットワーク、サーバー、ストレージ、アプリケーション、開発実行環境など)を共用する。
・物理的なハードウェアの設置や接続などの作業を必要とせず、ソフトウエア的な設定だけで調達や構築ができる。
・ネットワークを介して、利用できる。
そんなサービスのことです。
この仕組みを特定の企業や組織で占有利用する場合を「プライベート・クラウド」といいます。
例えば、企業や組織にとって独自性の高いアプリケーションの運用に際し、その運用方法やリソースの管理について、独自のやり方にこだわりたい場合や、コンプライアンス上の理由からデータやシステムのハードウェア基盤を他の企業や組織と共用することが赦されない場合などは、この方式が選択されます。ただ、独自にシステム基盤を所有し、これを運用管理しなければならないための投資や、構築、運用管理のためのスキルや人材を自ら確保する必要があります。また、システムを設置する場所や設備を自ら所有するか、自分達専用にデータセンターを借り受けなければなりません。
一方、異なる複数の企業や組織(テナントと言います)で共用する場合を「パブリック・クラウド」と言います。
システムの構築や運用管理は、クラウド・サービス・プロバイダーから提供される機能やサービスの範囲で、自社の業務要件やシステム要件に合わせて設定し、利用します。利用者にとっては、初期の設備投資は不要となり、運用管理の多くもプロバイダーに任せることができるので、少ない運用管理負担で使うことができます。もちろん、複数テナントで利用してもセキュリティを確保し、安定して運用するための機能や仕組みは備わっています。ただ、それぞれのパブリック・クラウドの標準に従い、これら機能や仕組みを使いこなすためのスキルは必要です。
プライベートもパブリックも、運用の自動化やシステム・リソースの調達や構成変更を簡単にしてくれる機能が備わっている点では同じです。アプリケーション毎にハードウェアを導入し運用管理する場合に比べて、遥かにシステム・リソースの調達や構築、構成変更や運用管理が容易になります。
仮想化は、このようなクラウド・コンピューティングを支える技術のひとつです。
仮想化の技術を使えば、ハードウェア的な作業を必要とせず、システムの調達や構築が可能になります。ただ、仮想化の技術だけでは、調達や構築、運用管理に関わる様々な設定は、エンジニアが自分でやらなければなりません。クラウドは、これらを自動化することで、その負担を大幅に削減し、エンジニアの生産性を高めてくれます。なお、仮想化は、IaaSのようにサーバーやストレージなどのシステム・インフラをサービスとして提供する場合には使われますが、PaaSやSaaSのようにインフラを隠蔽し、ユーザーには意識させない使い方の場合は、他の方法で複数のテナントに共用させる仕組みが使われる場合が、一般的です。
このクラウドを機能や役割に応じて組み合わせる利用形態を「ハイブリッド・クラウド」と呼んでいます。
両者は、個別独立して運用されますが、使われる技術基盤を標準化された共通の仕組みで作っておければ、データとアプリケーションを容易に移動し、負荷や役割に応じて使い分けることができます。例えば、セキュリティ的に慎重に管理しなければならいデータやアプリケーションは、プライベート・クラウドを使い、汎用的でグローバルなネットワークが必要となるアプリケーションはパブリック・クラウドを使い、両者を必要に応じて連携するなどの使い方です。
このようなクラウドを構築するために必要な機能を集めたオープンソースのパッケージ・ソフトウェアとして、OpenStackやCloudStackなどがあります。
これらを使うことで、クラウド基盤の構築が容易になるだけではなく、パブリックとプライベートで同じものを使っていれば、ハイブリット・クラウドの実現も容易になります。
また、異なるパブリック・クラウド、例えば、Amazon Web Services、Google Cloud Platform、Microsoft Windows Azure Platformなどには、それぞれに得意とする機能やサービスがありますが、これらを目的に応じて組合せ、自分達にとって最適なサービスを実現するクラウドの利用形態を「マルチ・クラウド」と呼びます。
ユーザーにとって大切なことは、自分達にとって機能やコスト、使い勝手において最適なサービスを実現することです。その背後でどのようなシステムが使われるかは、必ずしも重要なことではありません。システムを提供し、その管理を担う人たちは、パブリック・クラウドやプライベート・クラウド、ハイブリッド・クラウドやマルチ・クラウドを使い分けてゆくことが大切になります。
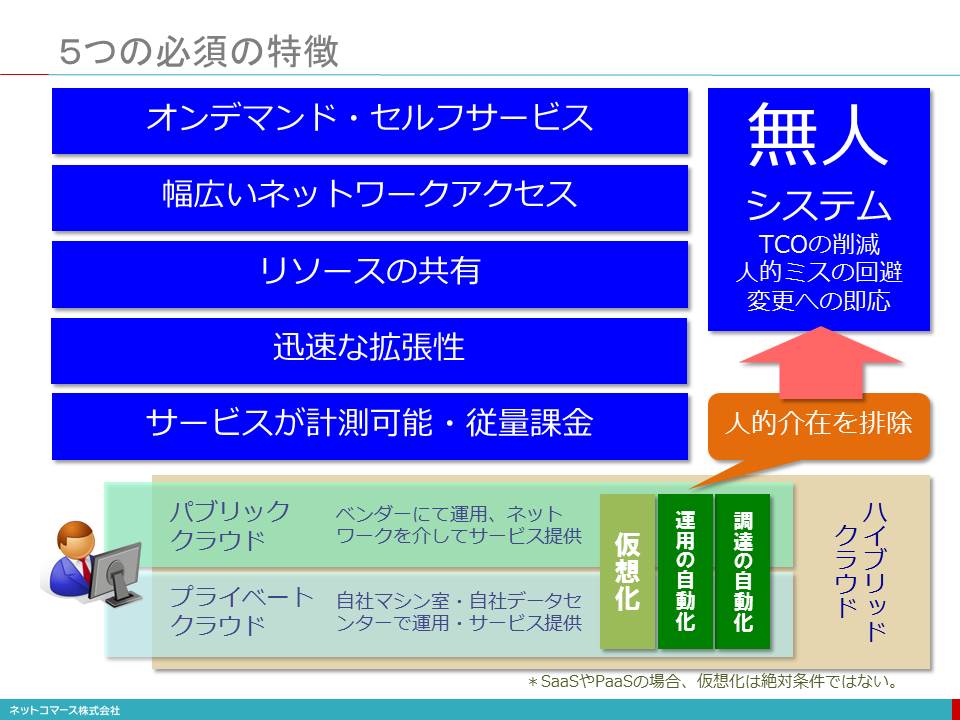
5つの必須の特徴
次に、NISTのクラウドの定義で述べられている「5つの必須の特徴(Five Essential Characteristics)について、説明しましょう。
オンデマンド・セルフサービス :
ユーザーがWeb画面(セルフサービス・ポータル)からシステムの調達や各種設定を行うと人手を介することなく自動で実行してくれる仕組みを備えていること。
幅広いネットワークアクセス :
PCだけではない様々なデバイスから利用できること。
リソースの共有 :
複数のユーザーでシステム資源を共有し、融通し合える仕組みを備えていること。
迅速な拡張性 :
ユーザーの要求に応じて、システムの拡張や縮小を即座に行えること。
サービスが計測可能・従量課金 :
サービスの利用量、例えばCPUやストレージをどれくらい使ったかを電気料金のように計測できる仕組みを持ち、それによって従量課金(使った分だけの支払い)が可能であること。
これらを実現するため、システム資源をソフトウェア的な設定だけで構築や変更できる「仮想化」、人手をかけずに運用管理できる「運用の自動化」、ユーザーに難しい設定をさせないための「調達の自動化」の技術が使われています。
これを事業者が設置・運用し、ネット越しにサービスとして提供するのがパブリック・クラウド、自社で設置・運用し、自社内だけで使用するのがプライベート・クラウドです。
これにより、徹底して人的な介在を排除し、人的ミスの排除、調達や変更の高速化、運用管理の負担軽減を実現し、人件費を削減、テクノロジーの進化に伴うコストパフォーマンスの改善を長期継続的に提供し続けようとしているのです。
「5つの必須の特徴」は、クラウド・コンピューティングの本質的な価値を実現する要件と言えるでしょう。
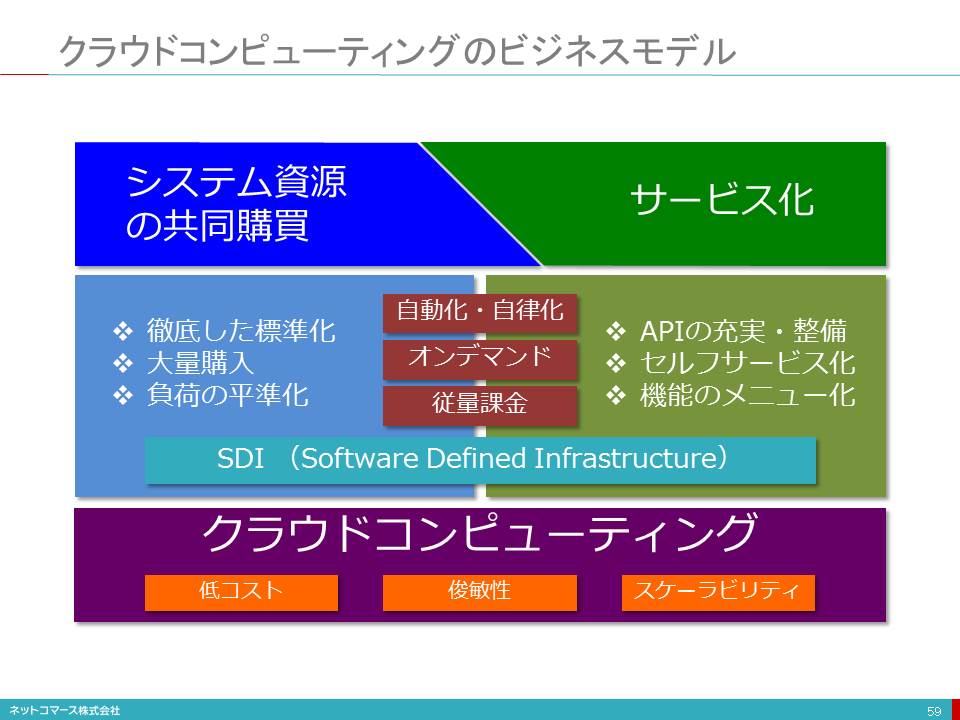
クラウドコンピューティングのビジネスモデル
【図解】コレ一枚で分かるクラウド・コンピューティングのビジネス・モデル
クラウド・コンピューティングをビジネス・モデルとして捉えてみると、「システム資源の共同購買」の仕組みと、それを容易に利用できるようにするための「サービス化」の仕組みの組合せと考えることができる。
「システム資源の共同購買」とは、一社あるいはひとつの組織でシステム資源を調達するのではなく、共同で大量購入し調達コストを下げると共に、共用することで設備や運用管理のコストを低減しようということだ。そのため、システム機器類の徹底した標準化をすすめ大量購買することで低コストでの調達を実現し、運用管理負担の低減を図っている。
例えば、AWSの場合、数百万台のサーバーを保有していると言われているが、サーバーの故障や老朽化に伴う入れ替えや追加増設を考えると、年間十数万台から数十万台のサーバーを購入していると考えられる。世界におけるサーバーの年間出荷台数が、1000万台程度であることから考えると、その多さは驚異的と言えるだろう。当然、市販品を購入することはなく、ODM(Original Design Manufacturing)での調達となることから、量産効果も期待できさらに低コストでの調達を実現している。
http://itpro.nikkeibp.co.jp/atcl/news/14/112001992/
また、多くの企業との共同利用となることから負荷の分散や平準化が期待できる。そのため、企業が個別に調達することに比べ調達台数の抑制も期待でき、低コスト化にも貢献していると考えられる。
一方、「サービス化」は、このシステム資源をサービスとして利用できることだ。つまり、物理的な作業を伴わずソフトウェアの設定だけでシステム資源の調達や構成変更を可能にしている。これを支えている仕組みが、SDI(Software-Defined Inftastracture)の技術だ。こちらについては、下記の記事を参考にしていだきたい。
>> 【図解】コレ1枚で分かるSDI
http://blogs.itmedia.co.jp/itsolutionjuku/2015/05/sdi.html
この仕組みにより、運用や調達の自動化・自律化を実現し、必要な時に必要なリソースをオンデマンドで調達できるようにしている。さらに、従量課金により使った分だけの支払いとなることから、システム資源調達における初期投資リスクを回避することができる。
クラウド・コンピューティングは、このような「システム資源の共同購買」と「サービス化」により、システム資源の低コストでの調達を実現し、変更への俊敏性を確保し、需要の変動にも即応できるスケラビリティを確保している。
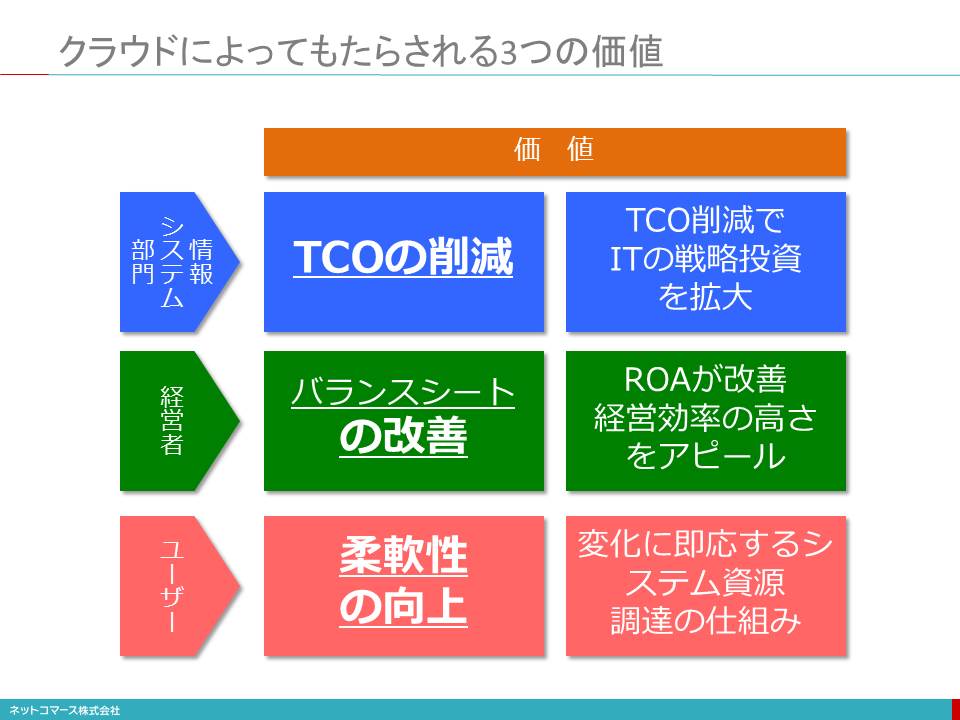
クラウドによってもたらされる3つの価値
情報システム部門 : TCOの削減
ビジネスのグローバル化やデジタル化が、求められる時代になり、ITへの要求も増え続けています。しかし、IT予算が伸びる見通しはなく、TCOの増加が重くのしかかっている情報システム部門にとって、TCOの削減は、予算面でのメリットを享受できます。
経営者 : バランスシートの改善
パブリック・クラウドであれば、システム資産を増やすことなく経費として処理できます。また、プライベート・クラウドであれば、システムの利用効率が高まり、少ない資産ですみますから、ROA (総資産利益率)やROI(投資収益率)などの経営効率の改善に寄与します。
ユーザー : 柔軟性の向上
ビジネスの不確実性の増大は、システムの機能や構成をあらかじめ決めることを難しくしています。その一方で、一旦決まれば、即応が求められ、変更にも俊敏に対応しなければならなりません。クラウドは、システム資源や業務機能を必要な時に必要なだけ利用でき、費用も使っただけ支払うことで対応でき、必要なくなれば、いつでも辞めることができるので、システムを購入し資産として所有しなければならない従来のやり方に比べ、初期投資リスクは少なく変化への対応も柔軟になります。
残念ながら、クラウドを使うだけでこのような価値を引き出せる訳ではありません。開発や運用のやり方も「所有」を前提とする手法をそのまま使っていては、難しいでしょう。例えば、性能を十分に出せなかったり、使用料金が嵩んでしまったりと、いったことになりかねません。また、従量課金になりますから、予算の取り方も変わります。
クラウドを使用すること言うことは、クラウドについての理解を十分に深め、確固たる決心と信念、工夫によって、その価値を引き出す努力が必要になるのです。
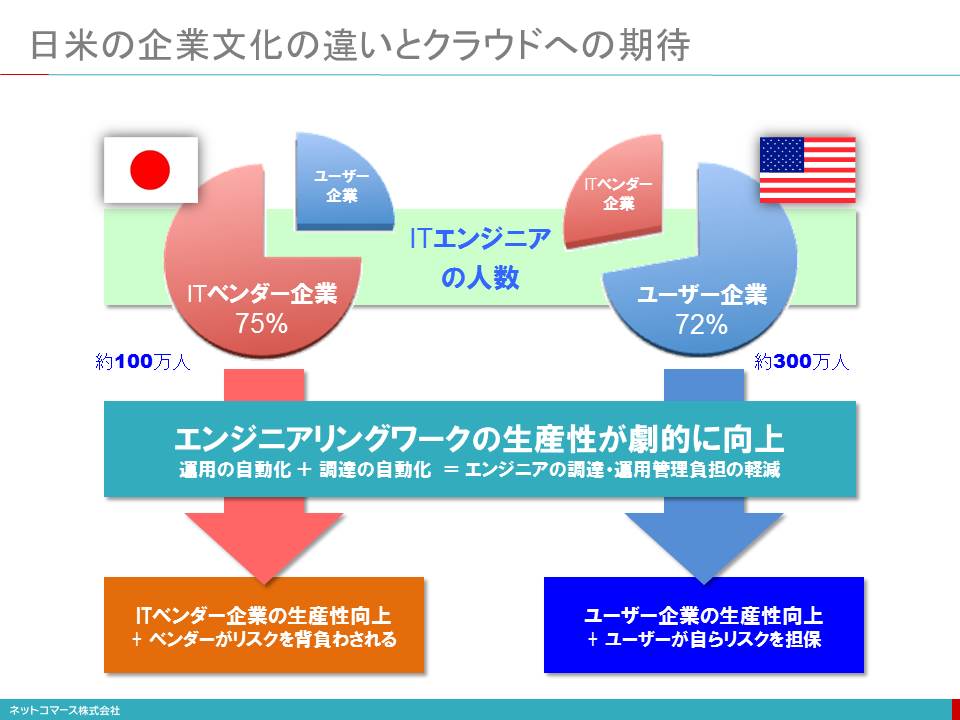
日米の企業文化の違いとクラウドへの期待
【図解】コレ1枚でわかる日米のビジネス文化の違いとクラウドコンピューティング
クラウド(ここでは、IaaSについて話をします)は、ITエンジニアの7割がユーザー企業に所属する米国で生まれた情報システム資産を調達する仕組みです。
クラウドは、リソースの調達や構成の変更など、ITエンジニアの生産性を高め、コスト削減に寄与するものです。とすると、ITエンジニアを社内に多く抱える米国では、クラウドはユーザー企業の生産性を高めることに直結しています。
一方、我が国のITエンジニアは、7割がSI事業者やITベンダー側に所属しています。従って、このような仕事は、システムの構築や運用を受託しているSI事業者側に任されています。ですから、クラウドは、SI事業者の生産性を向上させます。しかし、これはSI事業者にとっては、案件単価の減少を意味し、メリットはありません。また、調達や構成の変更はリスクを伴う仕事です。米国では、そのリスクをユーザーが引き受けていますが、我が国ではSI事業者が背負わされています。
このことから見えてくることは、SI事業者にとってクラウドは、案件単価が下がりリスクも大きくなることを意味し、利益相反の関係にあるという事実です。我が国のクラウド・サービスの普及が、米国ほどではないと言われていますが、その背景には、このような事情があるのかもしれません。
エンジニア構成の配分が、このように日米で逆転してしまっているのは、人材の流動性に違いがあるからです。米国では、大きなプロジェクトがあるときには人を雇い、終了すれば解雇することもさほど難しくありません。必要とあれば、また雇い入れればいいわけです。一方、我が国は、このような流動性はありません。そこで、この人材需要の変動を担保するためにSI事業者へのアウトソーシングを行い、需要変動の振れを担保しているのです。
ところで、クラウドを使う場合、リソースの調達や構成の変更は、「セルフ・サービス・ポータル」と言われるウエブ画面を使って行われます。必要なシステムの構成や条件を画面から入力することで、直ちに必要なシステム資源を手に入れることができます。
従来、このような作業は、業務要件を洗い出し、サイジングを行い、システム要件を決め、それにあわせたシステム構成と選定を行うことが必要でした。そして、価格交渉と見積作業を経て、発注に至ります。その上で、購買手配が行われ、物理マシンの調達、キッティング、据え付け、導入作業、テストを行っていました。この間、数ヶ月かかることも珍しくはありません。このような作業を必要とせずウエブ画面から簡単に行うことができるわけですから、生産性は大いに向上します。
しかし、我が国のユーザー企業は、先ほどの理由から、このような作業の多くをSI事業者に依存してきました。従って、いまさら自分でやれと言われても、簡単に対処できることではありません。SI事業者も受注単価が下がり、人もいらなくなるわけですから積極的にはなれません。ここに、暗黙の利害の一致が生まれており、これもまたクラウド利用を促進させる足かせとなっていると考えられます。
このような現実があるわけですから、我が国においては、米国と同じシナリオでクラウドの価値を訴求することは困難といえるでしょう。
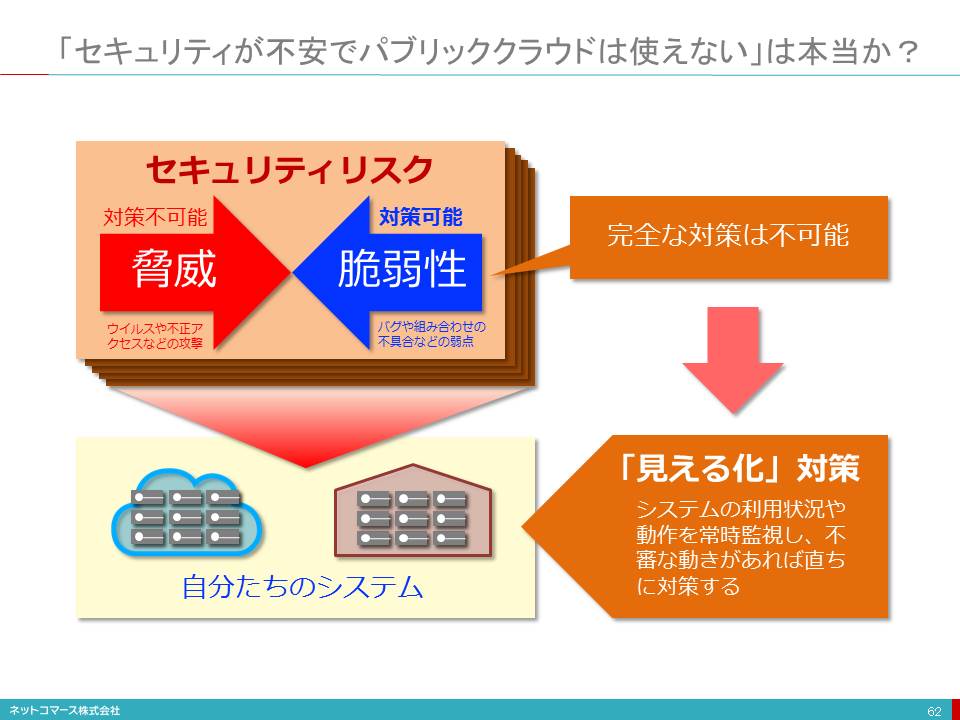
「セキュリティが不安でパブリッククラウドは使えない」は本当か?
【図解】コレ1枚でわかるクラウドのガバナンス
「ガバナンスが不安なので、パブリック・クラウドは使えない」という話を聞くことがあります。
本来、ガバナンスとは、「命令や指示などなくても、普段通りの業務をこなしていれば、業務や経営の目的が達成されるビジネス・プロセスを構築し、それを運用すること」です。セキュリティを確保するあるいは、コンプライアンスを守るといったことも、これに含まれます。
決して、指示され、命令され、自らも負担を感じてルールや規律を守ることではありません。このような行為は、指示・命令する側にとっても、守る側にとっても大きな負担です。また、結果として、「やらされる」側の人たちの中には、楽をしようと考えてセキュリティやコンプライアンスに反する行為を行うことにもなりかねません。さらに、マニュアルの整備、研修、管理・監視など、コスト的にも作業的にも大きな負担となってしまいます。このような行為は、「ガバナンス」ではありません。
本来のガバナンスとは、日常の業務を普通にこなしていれば、「効率」も上がり、「コスト」も抑制され、「リスク」も低減され、「利便性」も向上する。そんな業務の仕組みを作り運用することなのです。
しかし、この理想を完全に実現することは、コスト的にも技術的にも容易なことではありません。そこで、どこまでなら許容できるかの「許容水準」とどこまでできたら達成とするかの「達成基準」を設定し、最適な施策を打つことになります。そのためには、「効率」、「コスト」、「リスク」、「利便性」の4つの状況がいつでも見えていて、その状況を必要に応じて調整・変更できなくてはなりません。このような仕組みが整っていていることを、「ガバナンスが担保されている」と言います。
この視点でパブリック・クラウドを評価すると、どうなるのでしょうか。
一元管理され利用状況を計測でき、利用ログを把握できる。
必要な時に必要な機能/性能/資源を調達・利用できる。
管理の対象が少なく、管理負担が少ない。
なるほど、パブリック・クラウドはガバナンスを担保するための要件を満たしているようです。むしろ、一元管理もされず個別バラバラに導入されているシステムのほうが、よほどガバナンスは担保されていません。
こう考えるとパブリック・クラウドでは、ガバナンスが担保できないと断じることは、できないことが分かります。
だからと言って、これら仕組みがあるから、「パブリック・クラウドは、ガバナンスが担保できる安心・安全なシステム」だと断じることもまた短絡的な発想です。パブリック・クラウドは、カバナンスを担保するための「見える化」の仕組みや「調整・変更」が容易にできる仕組みが整っているということにすぎません。それらを使いこなさなければ、パブリック・クラウドといえども、ガバナンスを担保できるわけではありません。この点については、自社で所有し管理するシステムについても同様であり、この点において本質的な違いはないのです。
サービス事業者とユーザーの役割分担
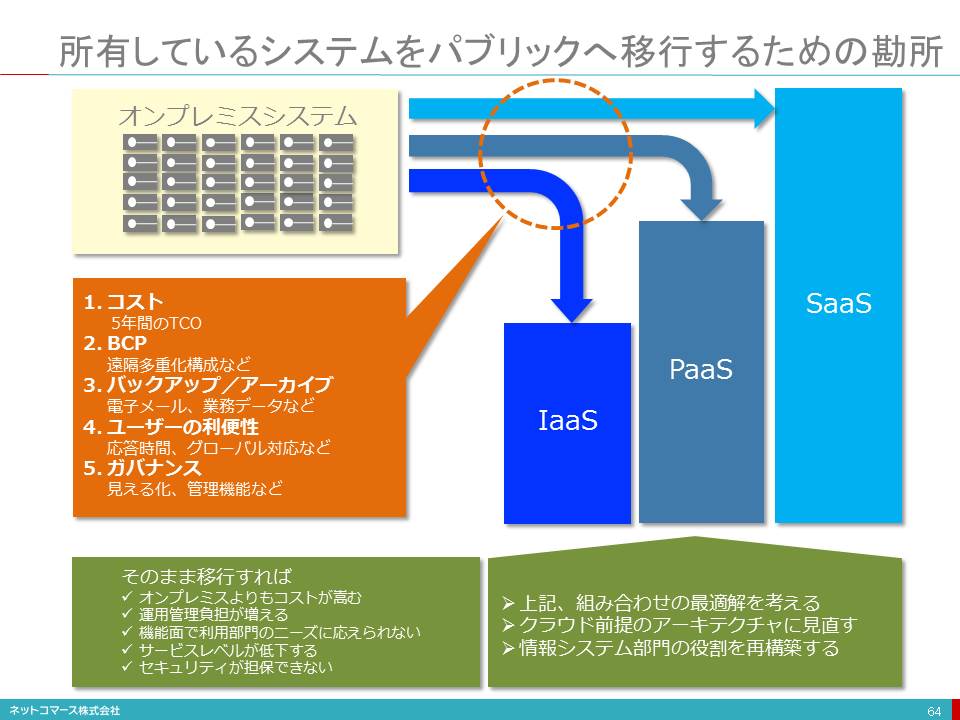
所有しているシステムをパブリックへ移行するための勘所
第4章 モバイルとウェアラブル
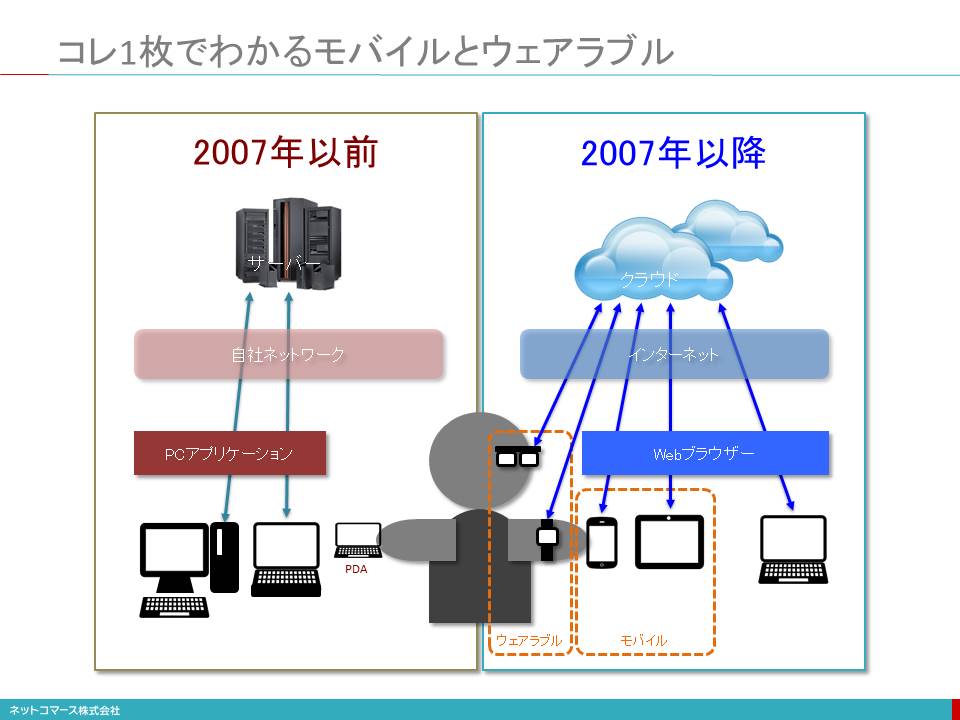
コレ1枚でわかるモバイルとウェアラブル
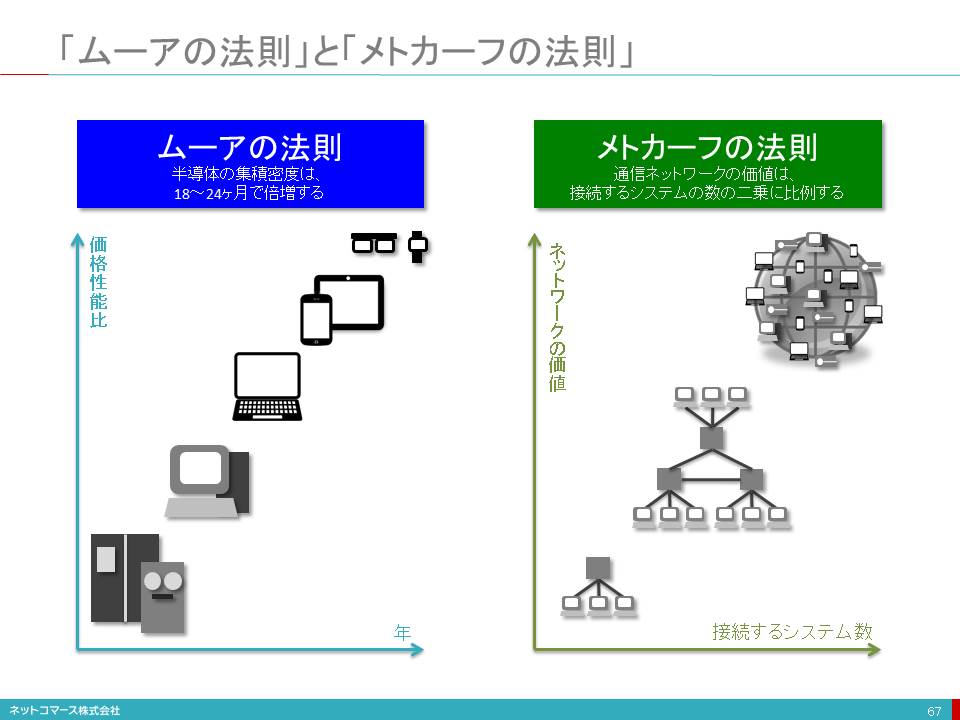
「ムーアの法則」と「メトカーフの法則」
ITトレンドを理解する上で、「ムーアの法則」と「メトカーフの法則」は、理解しておくといいでしょう。ともに経験則ではありますが、ITの進化を説明する法則として、広く知られています。
ムーアの法則
インテルの創業者、ゴードン・ムーア氏は、1965年に「半導体の集積密度は18~24ヶ月で倍増する」という法則を提唱しました。
ただ、ムーアの法則は半導体の微細加工技術の発展を根拠としているため、微細化が原子レベルにまで到達してしまうと通用しなくなるとも言われていますし、もはやそれが現実になろうとしています。しかし、「集積密度」を「性能向上」に置き換えて考えると、設計手法や実装技術の革新も相まって、この法則は、まだこれからも通用するとの考えもあるようです。
確かに、巨大なメインフレーム・コンピュータの時代から、それを遥かに凌ぐ性能を持った小さなスマートフォンやウェアラブルへと発展してきた歴史を考えると、まさにこの法則の通りだったことが分かります。
メトカーフの法則
イーサネット発明したロバート・メトカーフ氏は、1995年に「通信ネットワークの価値は、接続するシステムの数の二乗に比例する」という法則を提唱しました。
彼がこの法則を提唱したのは、ネットワークが、まだ、デスクトップ・コンピューターやファックス、固定電話機などで構成されていた時代でした。しかし、今では、インターネットの普及により、数十億のデバイスがネットワークにつながっています。また、ウェアラブルやIoTの普及は、この勢いを加速しています。
これに伴い、ネットワークの価値は、これまでにも増して飛躍的に高まり、IT全体の価値をも高めてゆくことになるでしょう。
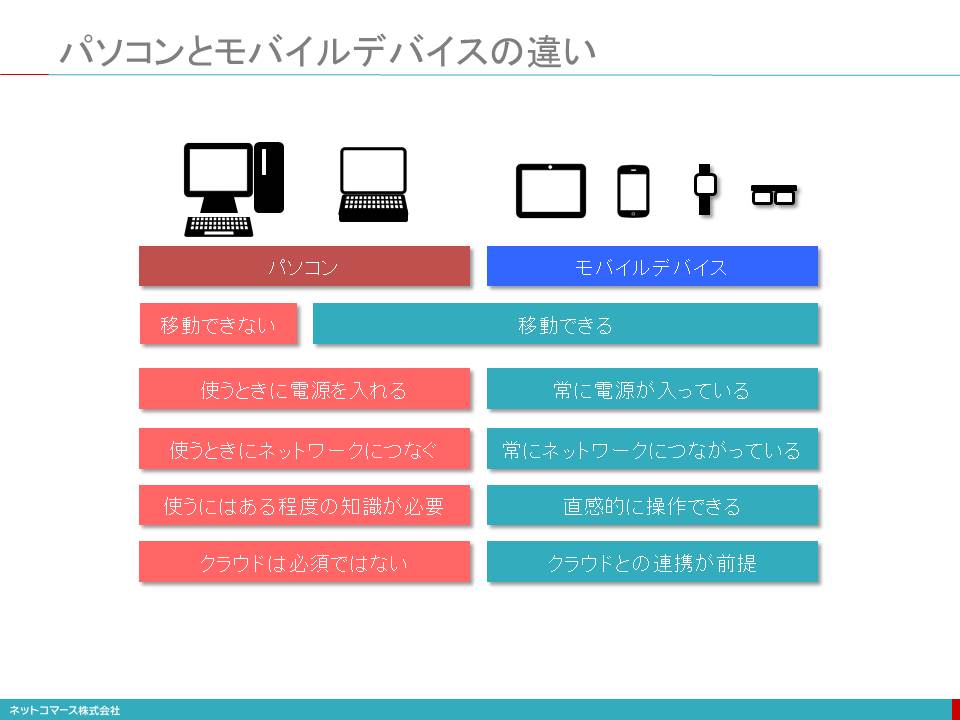
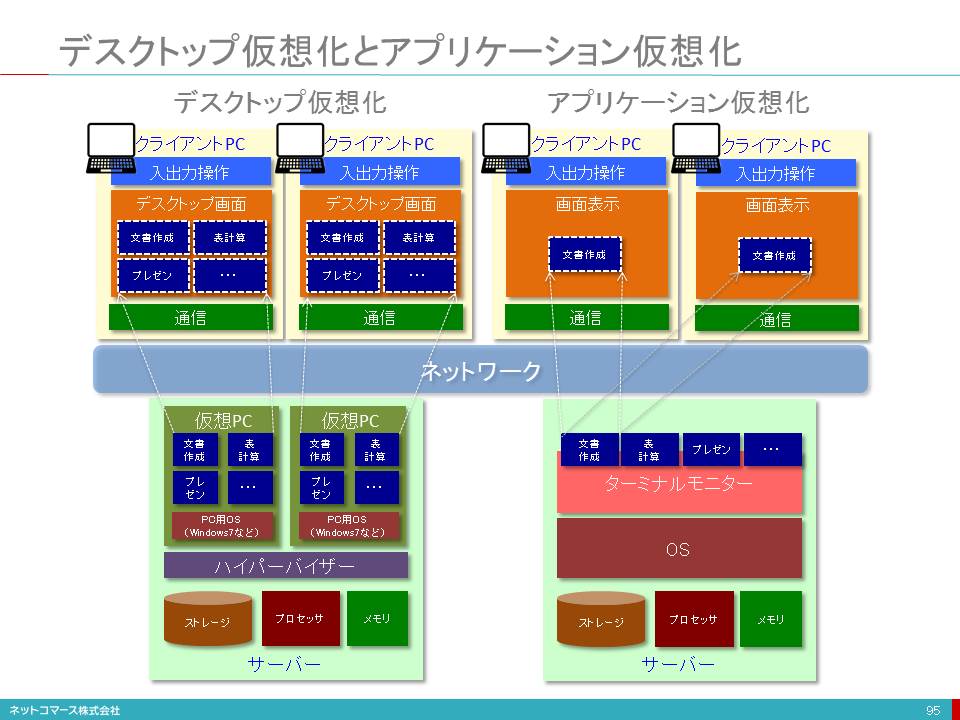
パソコンとモバイルデバイスの違い
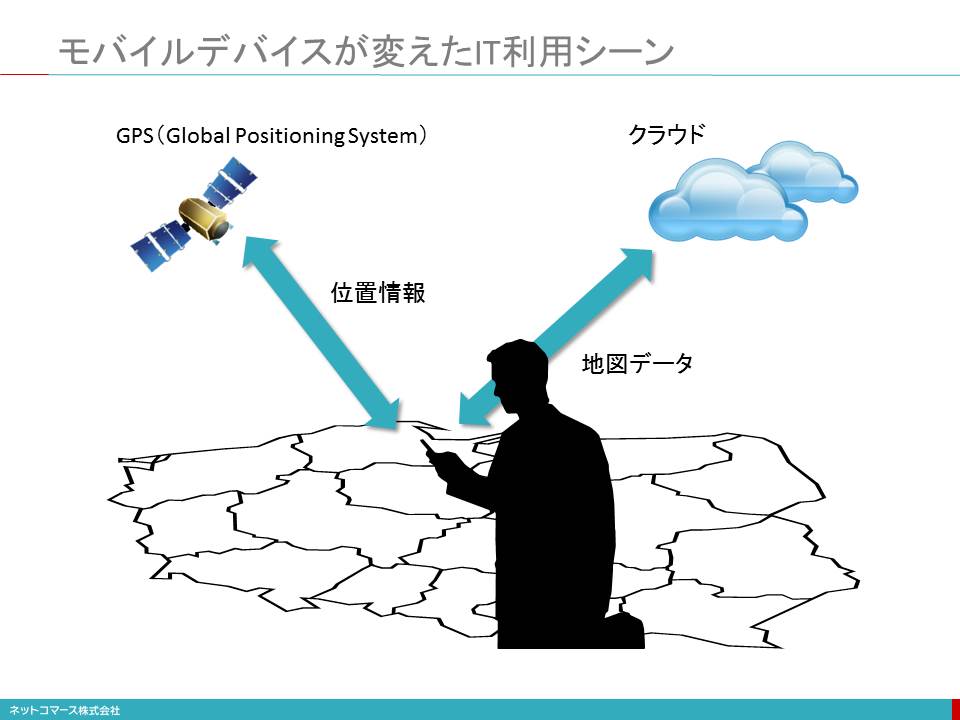
モバイルデバイスが変えたIT利用シーン
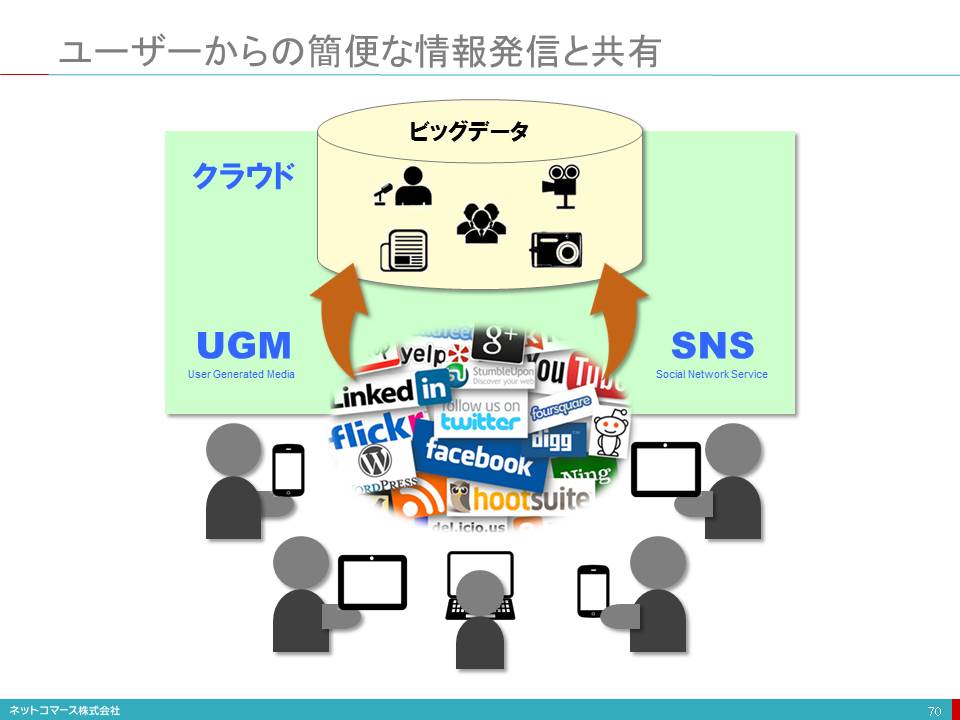
ユーザーからの簡便な情報発信と共有
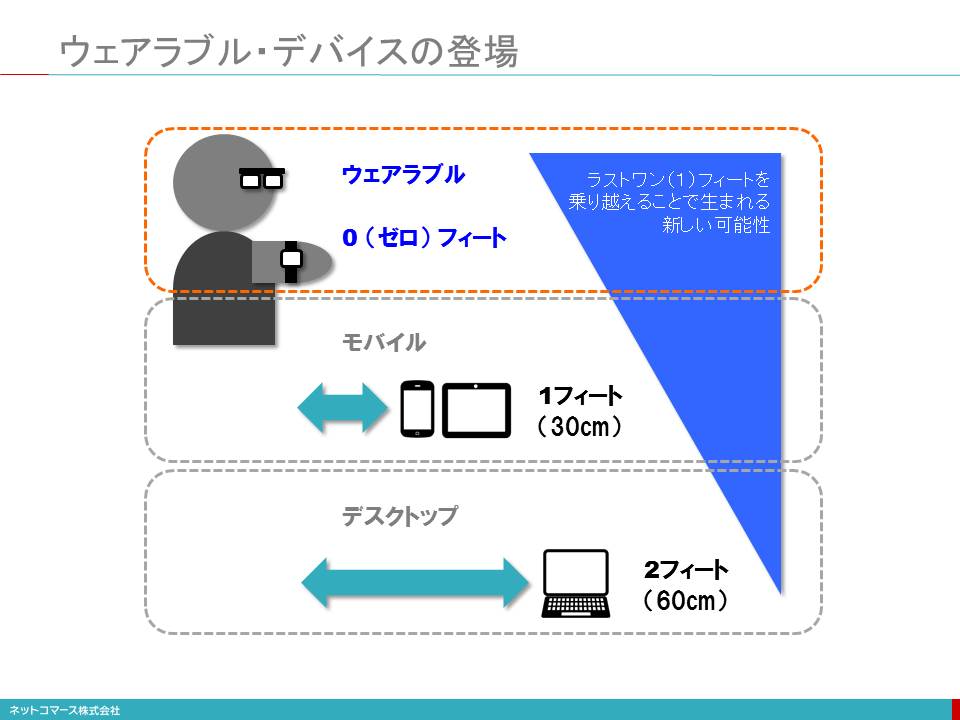
ウェアラブル・デバイスの登場
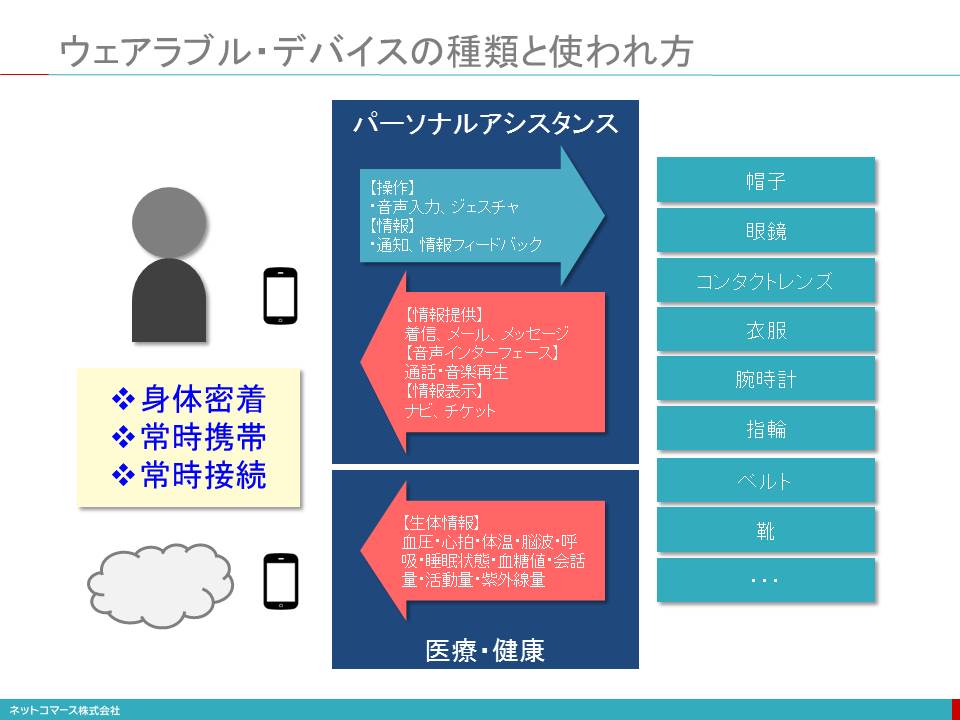
ウェアラブル・デバイスの種類と使われ方
身につけるデバイスと言っても、人はそれほど多くのものを身につけているわけではありません。一般的には、衣服、眼鏡、時計くらいで、ウェアラブル・デバイスもこれらを代替するものが大半です。変わったところでは、靴に取り付けランニングの距離やスピードを、ゴルフ・クラブに取り付けてスイングの状態を、テニス・ラケットのグリップ・エンドに取り付けてスイングや身体の動きを取得するといったアクティビティ・トラッカーも広い意味ではウェアラブル・デバイスと言えるかもしれません。これらデータは、スマートフォンのアプリや、その先につながるクラウド・サービスに送られ様々な機能を提供します。
ウェアラブルは、本格的な活用が始まったばかりです。現在はスマートフォンに着信した電話やメールを音や振動で通知したり、音声認識を使って簡単なメッセージを返信したりする機能が主流ですが、それに留まらない大きな可能性を秘めています。
特に、今後の新しい使い方として注目されているのが、生体情報の利用です。脈拍や血圧、発汗量などを収集して健康管理や予防医療に役立てる取り組みが始まっています。Googleは、コンタクトレンズ型の血糖値センサーを開発し、コンタクトレンズ・メーカーと一緒になって、その実用化を進めています。
一方で、新しいデバイス故の問題点も指摘されています。カメラ機能を持った眼鏡型デバイスをかけた人が、プライバシーへの配慮からレストランへの入店を断られるといったことや、生体情報といったセンシティブな情報をどう取り扱うかも気になるところです。新しいデバイスであるが故のルールの整備やコンセンサスの醸成は、今後の課題となるでしょう。
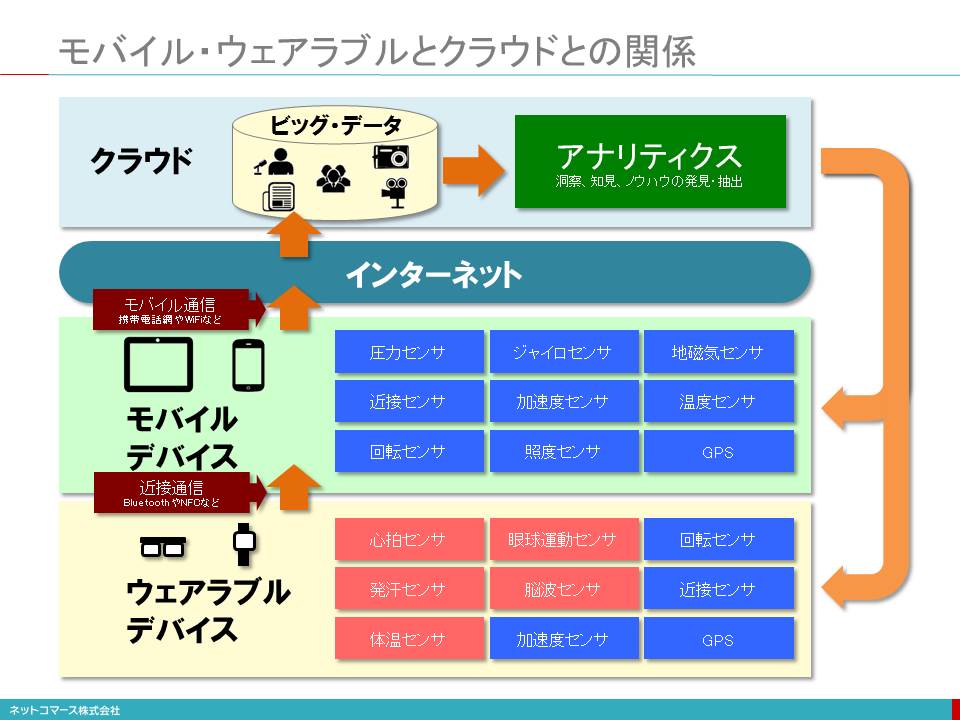
モバイル・ウェアラブルとクラウドとの関係
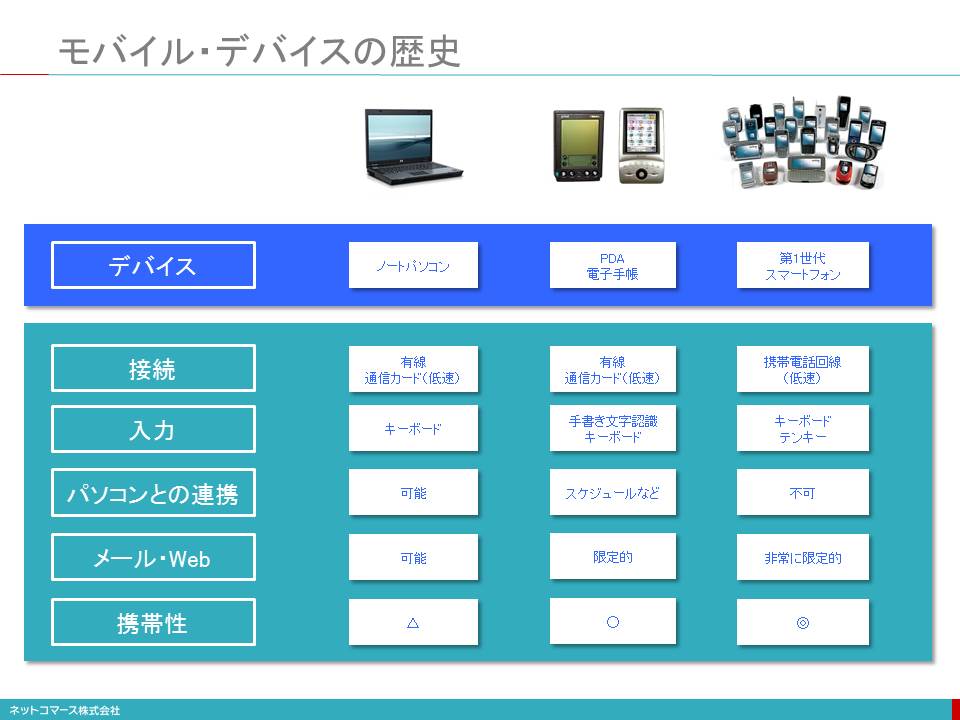
モバイル・デバイスの歴史
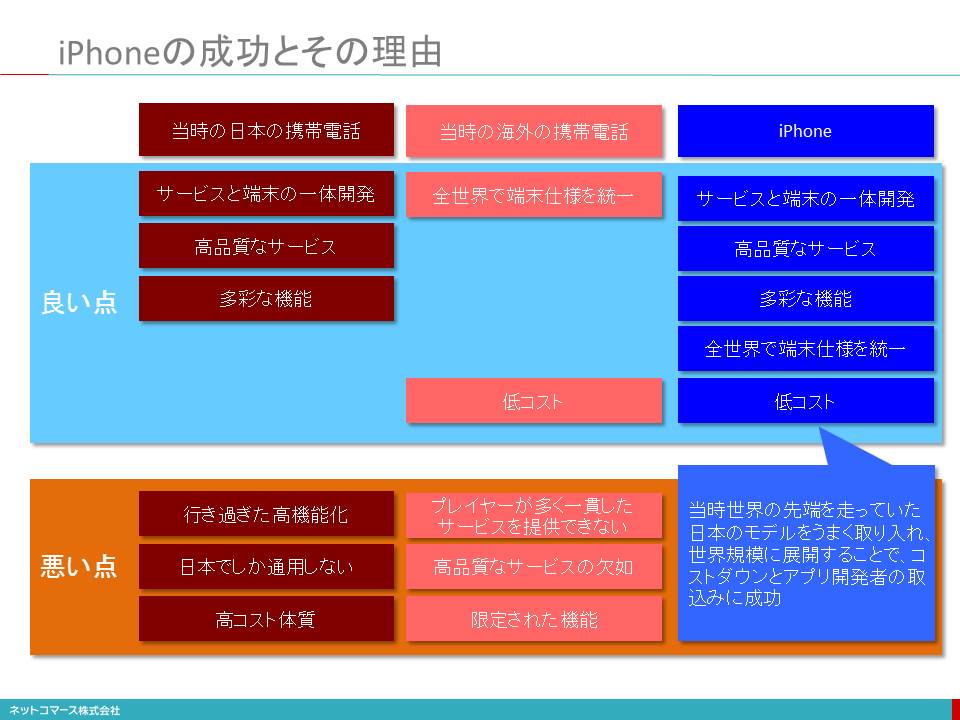
iPhoneの成功とその理由
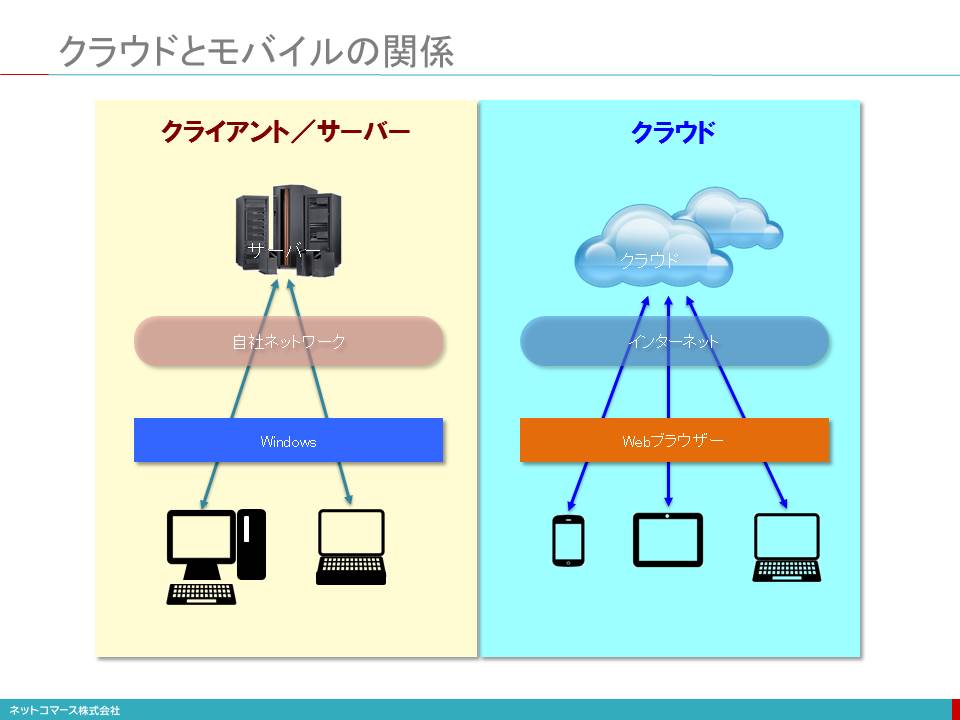
クラウドとモバイルの関係
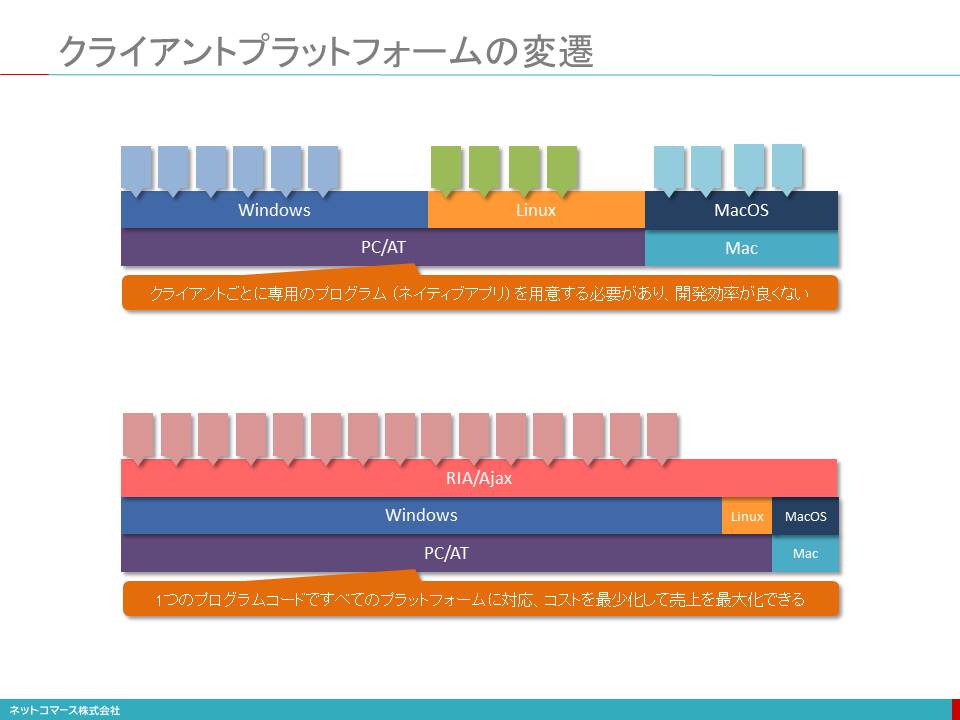
クライアントプラットフォームの変遷
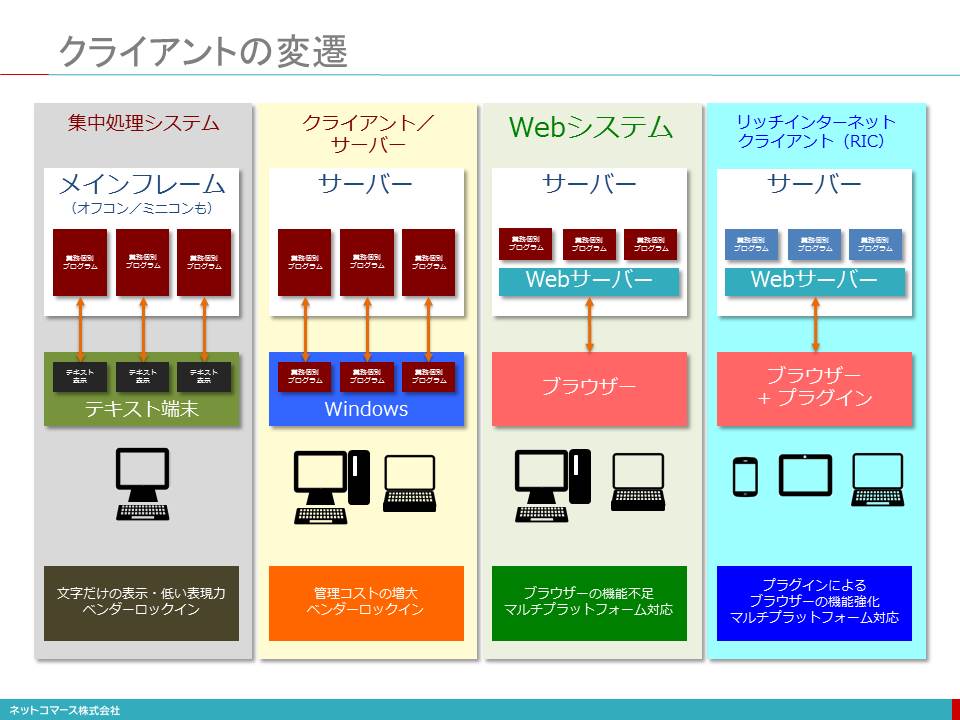
クライアントの変遷
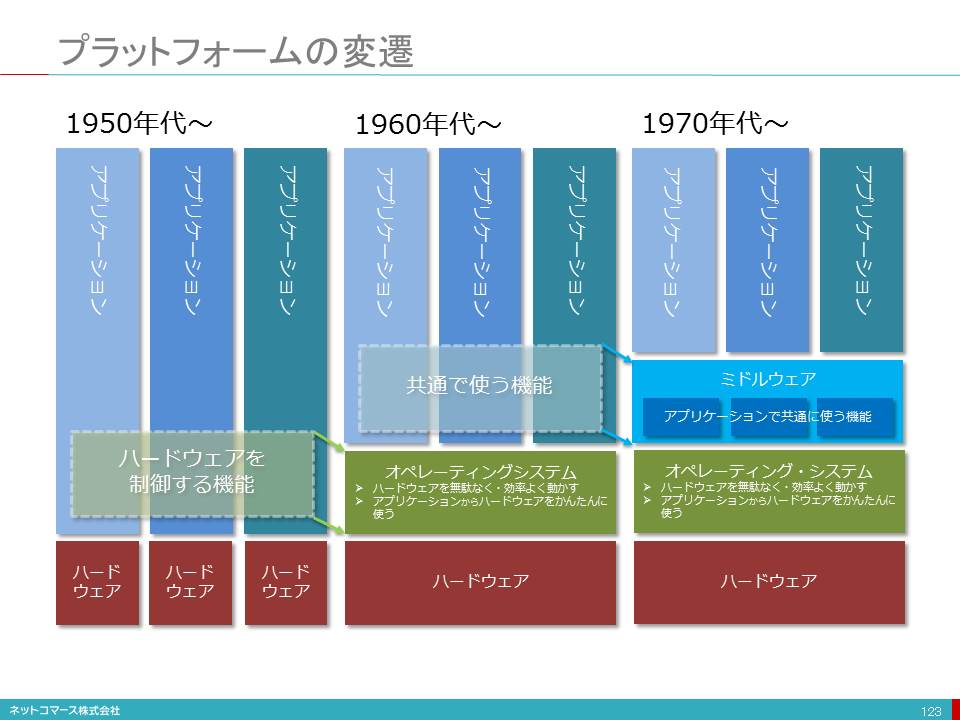
【図解】コレ1枚でわかるクライアントの歴史
1950年代、ビジネス・コンピューターの黎明期、ユーザーインターフェイスは、キーボードとプリンターが一体となったテレタイプ端末と言われるものが主流だった。その後、1970年代に入り、タイムシェアリングの普及と共にブラウン管式のディスプレイ端末が使われるようになる。しかし、表示できるのはモノクロの文字だけだった。その後、カラーで文字表示できる端末も登場したが、いずれも「文字(テキスト)」という限られた範囲での表現力しか持たなかった。
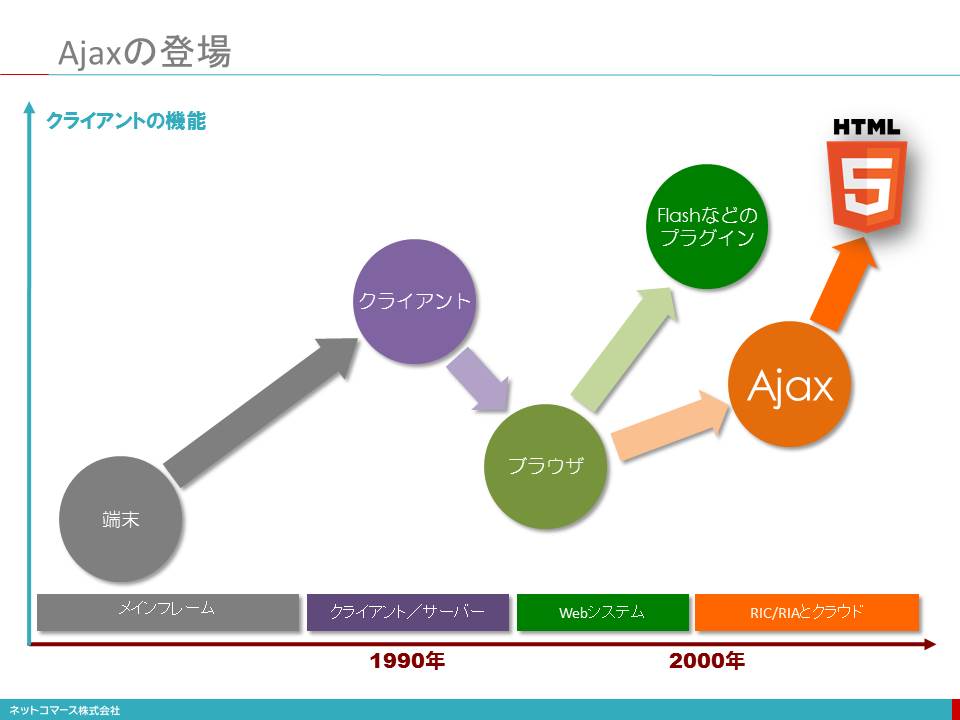
1980年代に入り、ビジネスの現場でパーソナル・コンピューターが使われるようになる。そこで、このPCを当時主流となっていた大型のメインフレーム、オフコンやミニコンと言われた小型コンピューターの端末として使われるようになる。当初は、PC上に端末エミュレーターを動かし「テキスト端末」として使われるのが一般的だった。その後、ミニコンやオフコンに加え、PCサーバーが登場する頃になると、主要な業務処理や組織で共有すべきデータの保管は、上位のコンピューターに任せ、入力画面のレイアウトやデータの加工・編集といった比較的軽いアプリケーション処理やユーザーインターフェイスに関わる処理はPCに任せ、上位のコンピューターと役割分担するクライアント・サーバー方式が普及した。
当時、ネットワークの速度は遅く、コンピューターの処理能力も高くなかった。そのため、上位のサーバー・コンピューターで表現力豊かな画面データを生成し送るのは、現実的ではなかったためだ。そこで、ユーザーの手元にあるPCの処理能力を活かし、高い表現力を手に入れようとした。その代表的なソフトウェアのひとつが、1989年に登場したグループウェアLotus Notesだ。
クライアント・サーバー方式の登場により、ユーザーは高い表現力を手に入れることができたが、その一方で、サーバー・アプリケーション毎にクライアントPCに対応するアプリケーションを導入しなければならない。そのため、各アプリケーションについてバージョンアップやプログラム修正のたびに全てのクライアントPCをアップデートしなければならないため運用管理負担が増大することになる。このような多くのクライアント・アプリケーションを抱え込んだPCは、「Fat Client(でぶっちょクライアント)」とも言われている。
1995年、Windows95が、登場する。これには、WebブラウザーであるInternet Explorerが、無償で付いてきた。そこで、このブラウザーをクライアント機能として使おうというWebシステムという考え方が生まれてきた。
ブラウザーを使えば、テキスト端末より高い表現力が得られる。しかも、PCには、ブラウザーを導入するだけなので、クライアント・アプリケーションの運用管理負担から解放される。そんな理由から、Webシステムが、普及することになった。しかし、当時のブラウザーは、静的な文書の閲覧が主な用途であり、また、回線の速度も遅かったことからサーバー・コンピューターから大きな画面データを送ることは現実的ではなかった。そのため、レイアウトの自由度や画像を使うなどにより、テキスト端末より表現力は高まったもののクライアント・サーバーほどの表現力を持たせることはできなかった。そのため、クライアント・サーバーと併存することになる。なお、1996年、クライアント・サーバーで一世を風靡したLotus NotesもLotus Notes/Dominoという名称で、ブラウザーから使える機能をリリースしている。
回線速度の向上やインターネットの普及とともに、ブラウザーで高い表現力を実現しようという動きが始まる。それが、プラグイン・プログラムを使う方法だ。ブラウザーは、それ自体、静的な文書の閲覧のためのものだった。ただ、外部プログラムとのインタフェイスをオープンにしていたことから、これを使って高い表現力を実現しようという方法が生まれた。1996年に登場したFlashは、その先駆けとなった。Flashの登場により、ブラウザーであってもPCネイティブと遜色のない表現力を実現できると言うことで、その後Flashは広く普及してゆく。Flash同様のプラグインとして、その後、SilverlightやCurlなどが登場する。
これらプラグイン・プログラムで動作するアプリケーション・プログラムをRIA(Rich Internet Application)、そのクライアントとなるプラグインが動作するブラウザーをRIC(Rich Internet Client)と呼ぶ。
このような方法で表現力を高めたブラウザーではあるが、その表現を規定するHTML言語は、1997年に正式勧告されたHTML4.0、1999年に若干の修正が加えられたHTML4.01以降、大きな変更が加えられないままに使われてきた。それをプラグインで機能を補完してきたわけだが、回線の高速化やモバイル・デバイスの普及など当時の状況とは大きく変わってしまい、プラグインでの対応にも限界が見え始めた。そのため、2014年、プラグインを使わなくてもブラウザーの機能だけで高い表現力やモバイル・デバイスとの対応を可能にするHTML5.0が勧告されることとなった。
HTML5.0、その前身となったAjaxについては、後日「コレ1枚」で紹介する。
Ajaxの登場
ブラウザーの進化とAjax
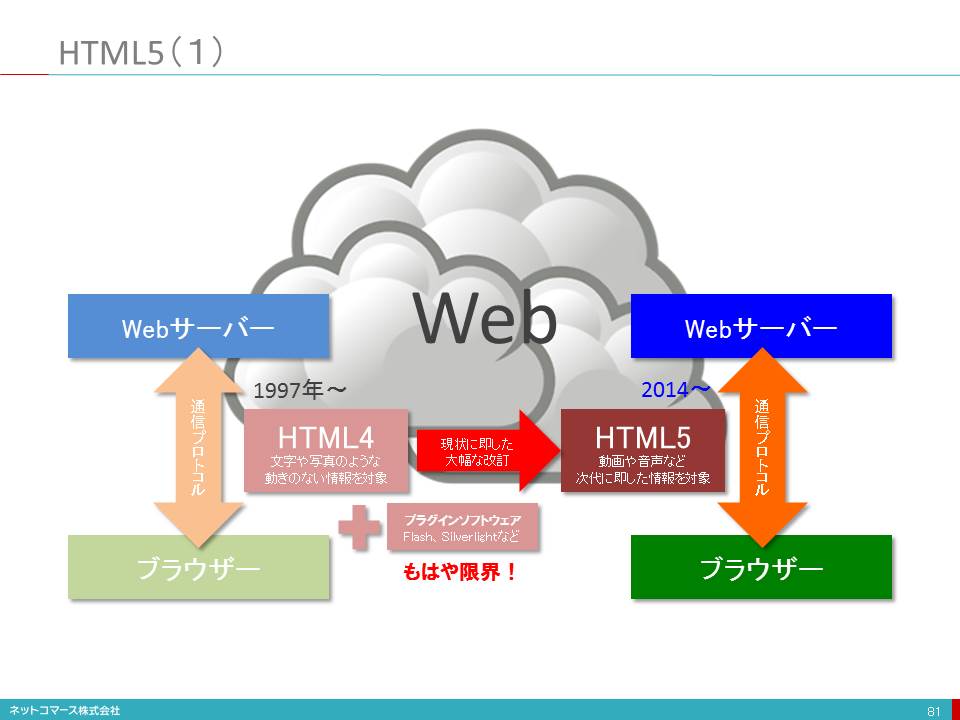
HTML5(1)
1990年代初頭、文字や写真のような動きのない情報を、インターネットを介して交換するための手段として登場したのがウェブです。しかし、現在では、動画再生やビデオ会議、ゲームなど動きのある対話型のアプリケーションが動作するプラットフォームとして利用されています。
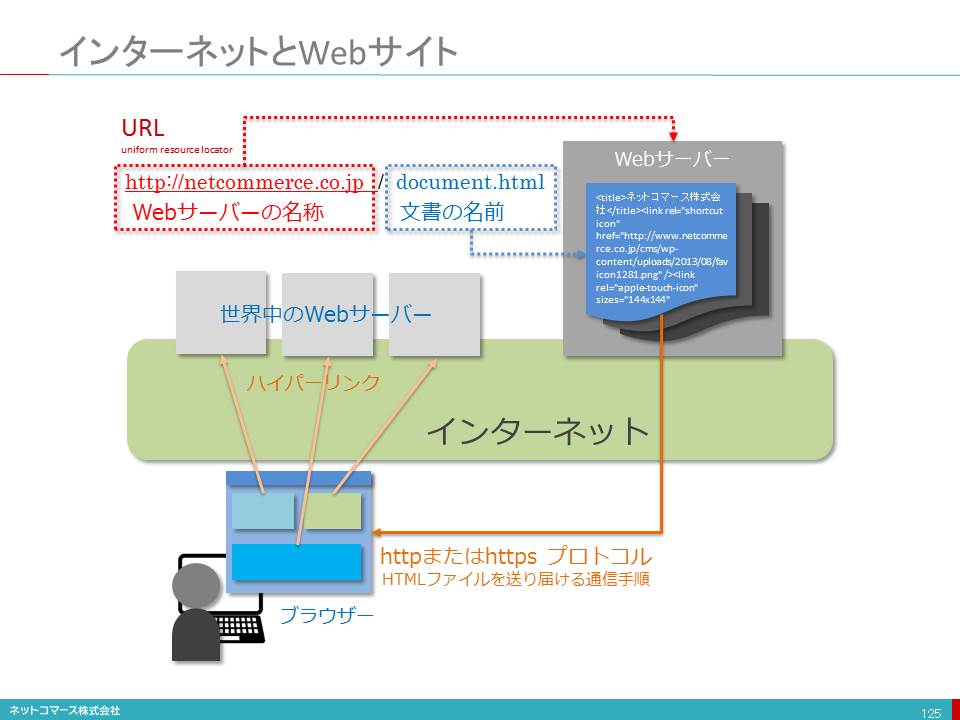
この仕組みを実現しているのが、情報を送り出すウェブサーバーと、その情報を表示するブラウザ、そして、情報をやり取りする手順である通信プロトコルです。この組合せは、ひとつではありません。例えば、ブラウザだけでも、MicrosoftのInternet Explorer、MozilaのFireFox、AppleのSafari、GoogleのChromeなどがあります。ウェブサーバーや通信プロトコルにもいろいろなものがあります。このように異なるソフトウェアを使ってもお互いに情報のやり取りができ同様の表現にできるのは、情報の構造やブラウザへ表示方法を指定するHTML(ハイパーテキストマークアップ言語)が標準化され、共通に利用できるからです。
しかし、このHTMLも1997年にバージョン4(HTML4)が定められ、1999年に4.01にマイナー・バージョンアップされて以降、大きな改訂もないままに今日まで使われてきました。その間、ネットワークの高速化やコンピュータの性能向上、GPSやセンサーが組み込まれたスマートフォンの出現など、当時とは利用環境が、大きく変わってしまいました。
この状況に対応するために、HTML4はそのままに、動画や音声を再生するなどのHTML4には含まれない機能をプラグイン(Flashなど)といわれるソフトウェアを追加して補完してきたのです。しかし、このような対処ではもはや限界が見えてきました。そこで、時代にふさわしい改訂が求められるようになり、次代を担うHTML5を定める取り組みが生まれたのです。
2014年10月、HTMLは、15年の歳月を経て新しいバージョンとしてW3Cより正式に勧告されました。今後は、このHTML5を基盤として新たな取り組みが進められることになります。
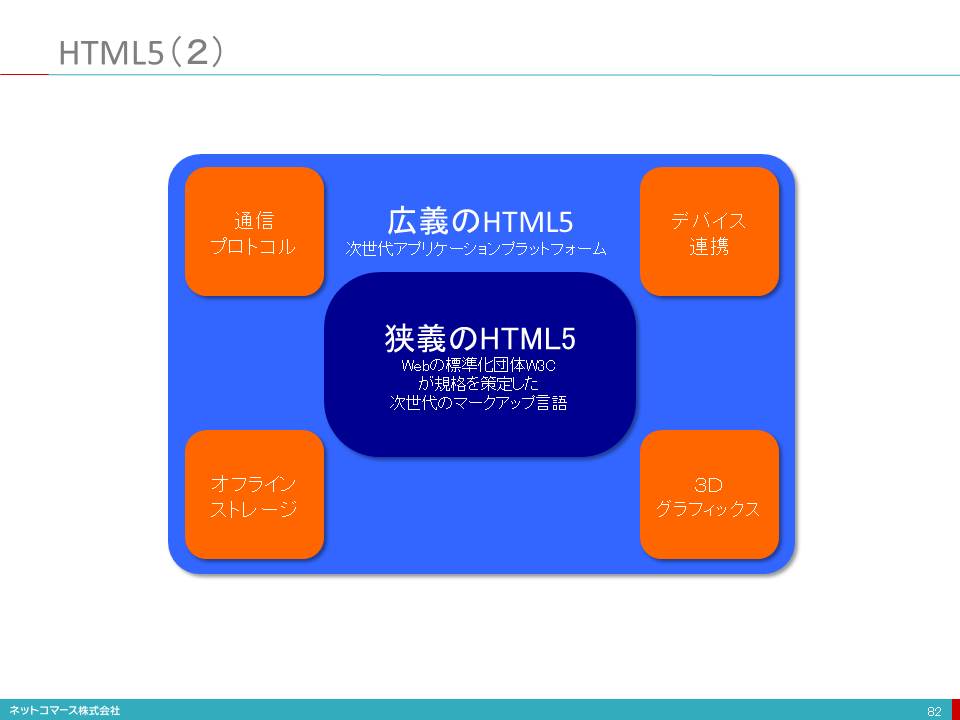
HTML5(2)
HTML5には、狭義と広義の意味があります。狭義には、ウェブの標準化団体「W3C(World Wide Web Consortium)」が規格を策定した次世代のマークアップ言語そのものを指しています。ブラウザで表示する内容の構成やレイアウトの指定、動画や音声、2次元グラフィックスの取り扱いなどを定めています。広義には、これに加えて、ネットワークに接続されていないときにもデータを加工・編集するためのオフラインストレージ、スマートフォンなどのハードウェアに内蔵されるGPSやセンサーをブラウザで扱うためのデバイス連携、豊かな表現を実現する3次元グラフィックスなど、ブラウザ上で高度で複雑なアプリケーションを動かすための機能の扱いまで含めています。つまり、次世代のアプリケーション・プラットフォームを実現するための方法や手順を標準化したものという意味で使われます。
広義の意味でのHTML5には、従来プラグインで実現していた機能の多くが含まれています。HTML5のゴールのひとつはここにありました。つまり、特定のメーカーが提供する技術に頼るのではなく、誰もが自由に利用できるオープンな標準として実現することです。
実際、2010年のAppleのiPhoneでAdobeのFlash(当時のウェブにおける動画や音声を利用するための事実上の標準となっていたプラグイン)をサポートしないという発表はオープンではないことの課題を露呈しました。その後、iPhoneやiPadが広く使われるようになり、HTML5による動画や音声の配信が一気に普及したのです。
現在では、HTML5はウェブだけでなく、スマートフォン向けアプリケーションや企業向けシステムなどの開発にも利用されるようになり、マルチデバイス時代のアプリケーション技術として普及しつつあります。
モバイルファースト・モバイルシフトの波
第5章 ITインフラストラクチャと仮想化
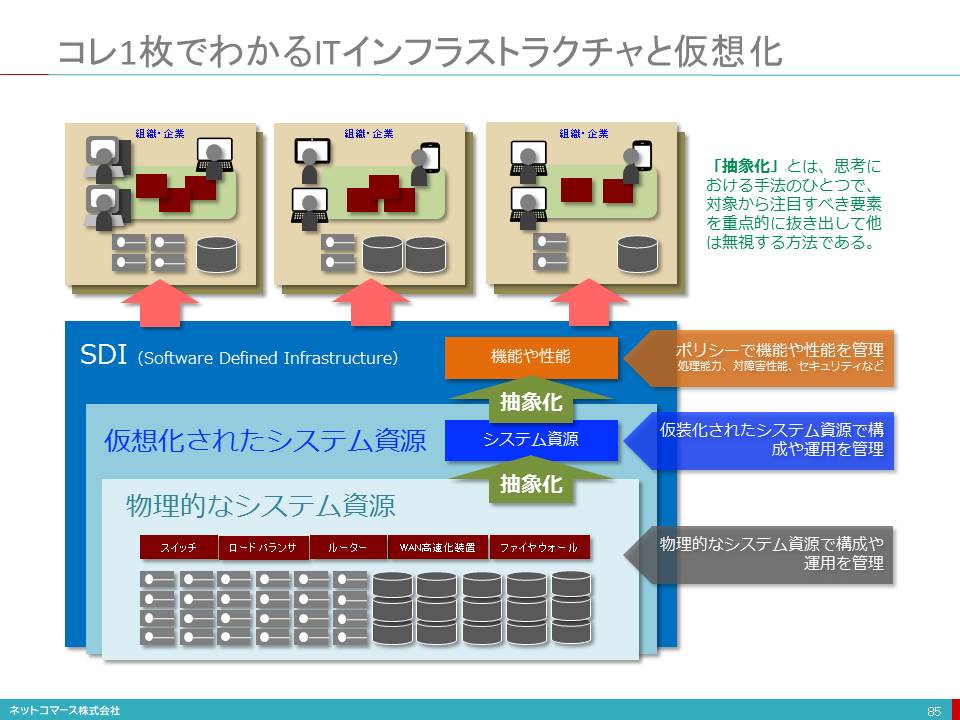
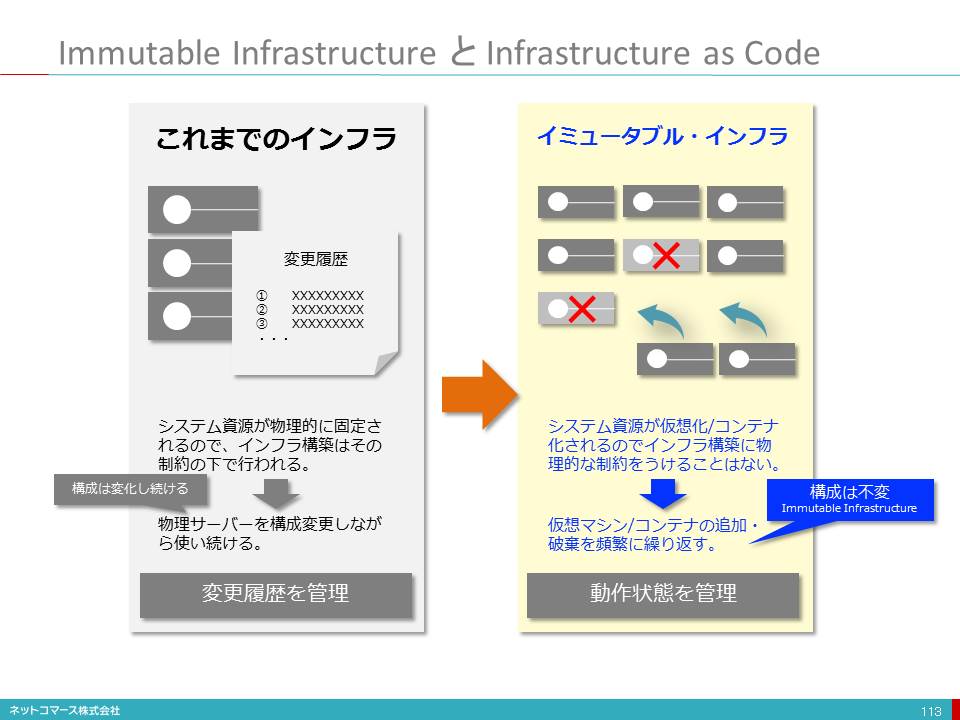
コレ1枚でわかるITインフラストラクチャと仮想化
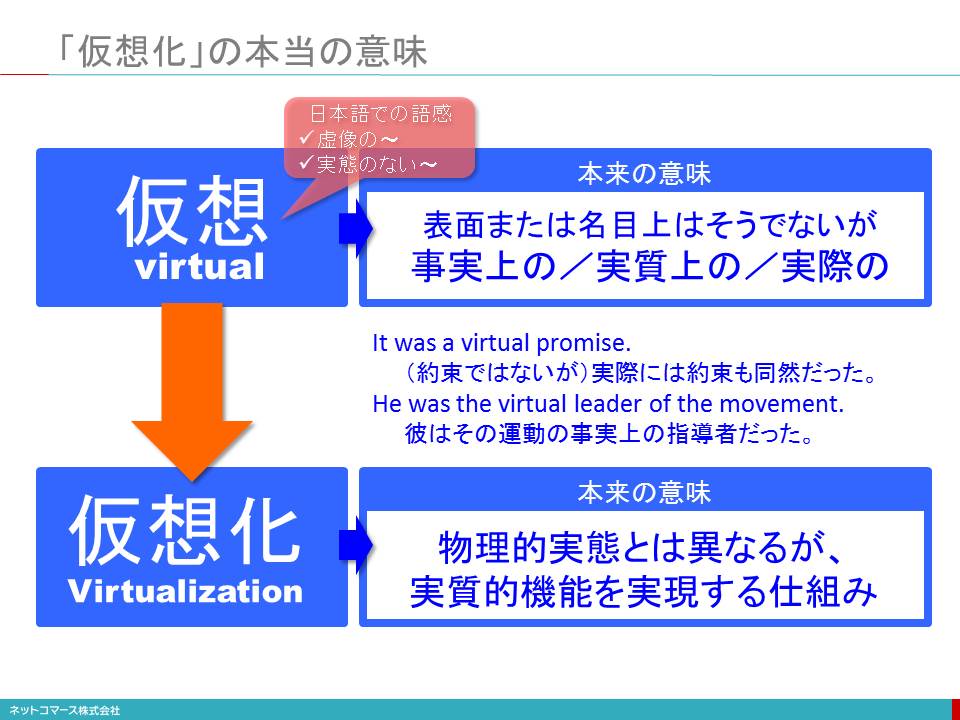
「仮想化」の本当の意味
日本語の「仮想」という言葉を聞くと、「虚像の」、「実態のない」という意味を思い浮かべてしまいます。ところが、この言葉の元となった英語の「Virtual」は、どうもそういう意味ではないらしいのです。調べてみると、「(表面または名目上はそうでないが)事実上の/実質上の/実際の」という意味があるようです。また、ラテン語の語源を見ると「力のある〜」と記されています。
辞書を引くと英語の文例には、次のような記述がありました。
It was a virtual promise.
(約束ではないが)実際には約束も同然だった。
He was the virtual leader of the movement.
彼はその運動の事実上の指導者だった。
He was formally a general, but he was a virtual king of this country.
彼は公式には「将軍」ではあったが、彼はこの国の実質的国王だった。
このように見ていくと、私たちがITの用語として使っている「仮想化=Virtualization」は、次のような意味と理解するのが、自然かも知れません。
「物理的実態とは異なるが実質的機能を実現する仕組み」
仮想化は決して、「虚像で実態のないシステムを作り出す仕組み」ではないのです。
つまり、サーバーやストレージ、ネットワークの物理的な構成や機能、性能とは異なる形態をしているが、実質的には、これと同様の役割を果たす仕組みを実現する技術と考える方が現実に即しています。
私たちは、物理的な実態がそこになければ、その存在を認めにくいものです。しかし、考えてみれば、物理的実態にかかわらず、必要な機器構成や機能、性能と同等のものが、実質的に使えるのならば十分です。
「仮想化」とは、まさに物理的なシステム資源とは異なるが「実質的」には、物理的なシステム資源と同等の扱いができるものを実現し、ユーザーに提供する仕組みなのです。
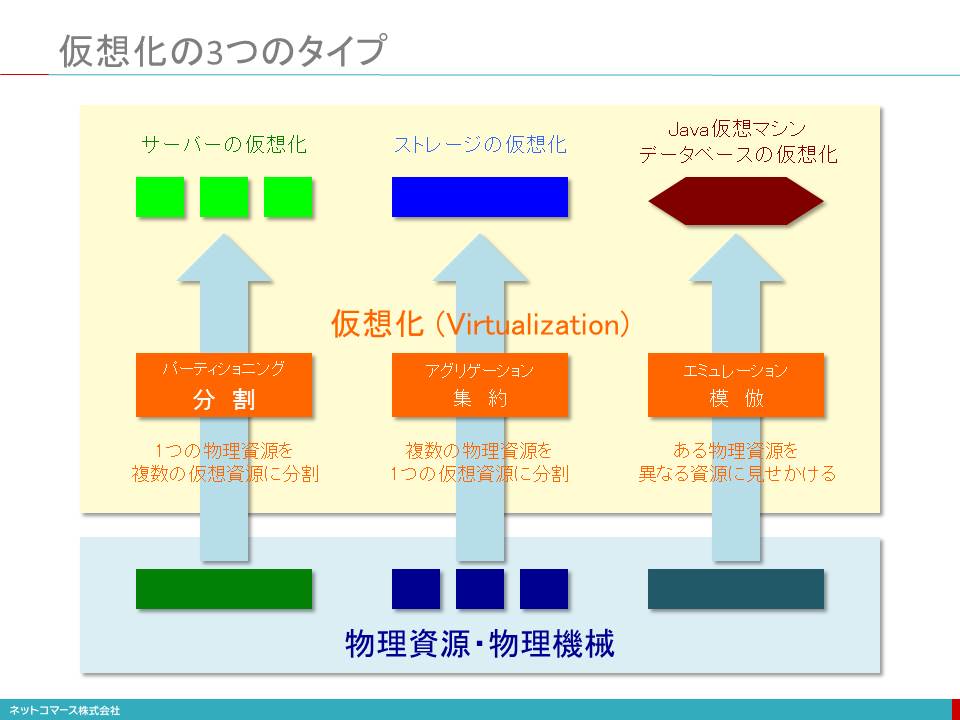
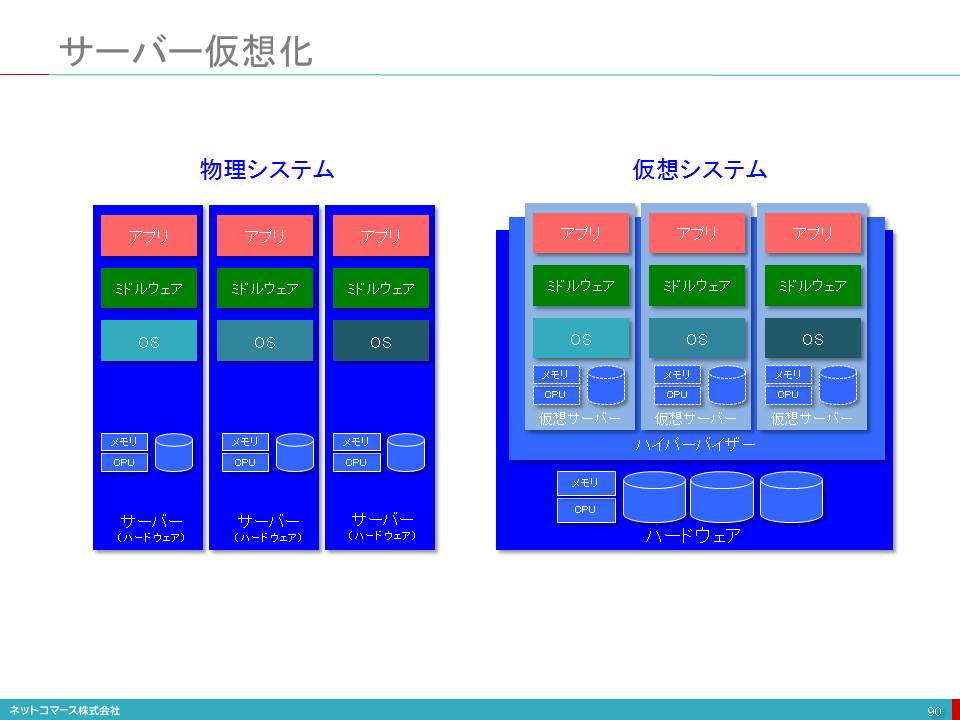
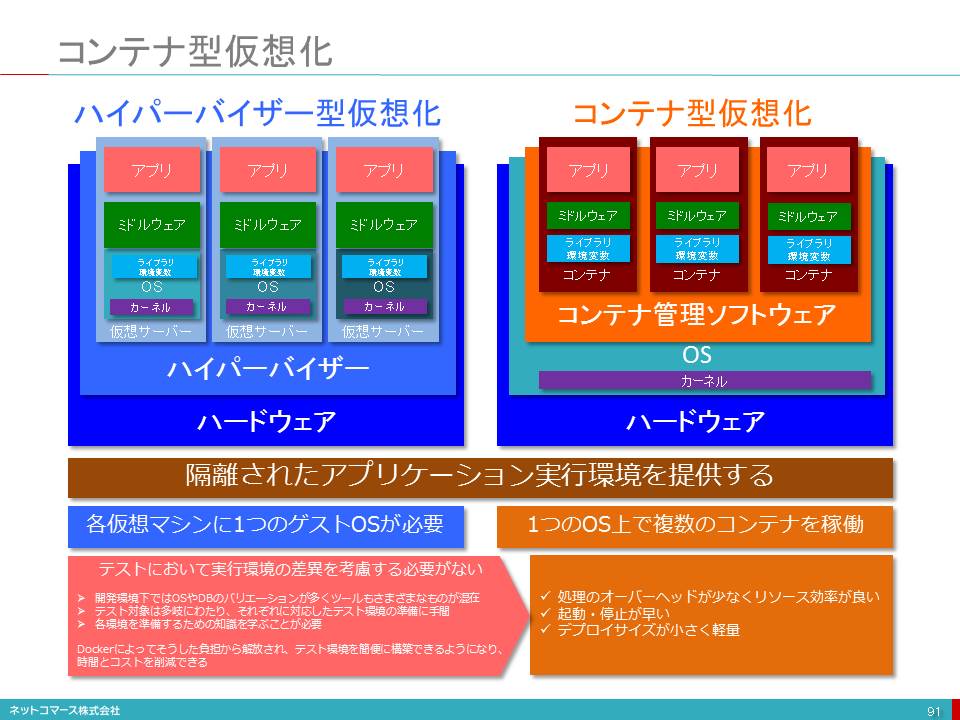
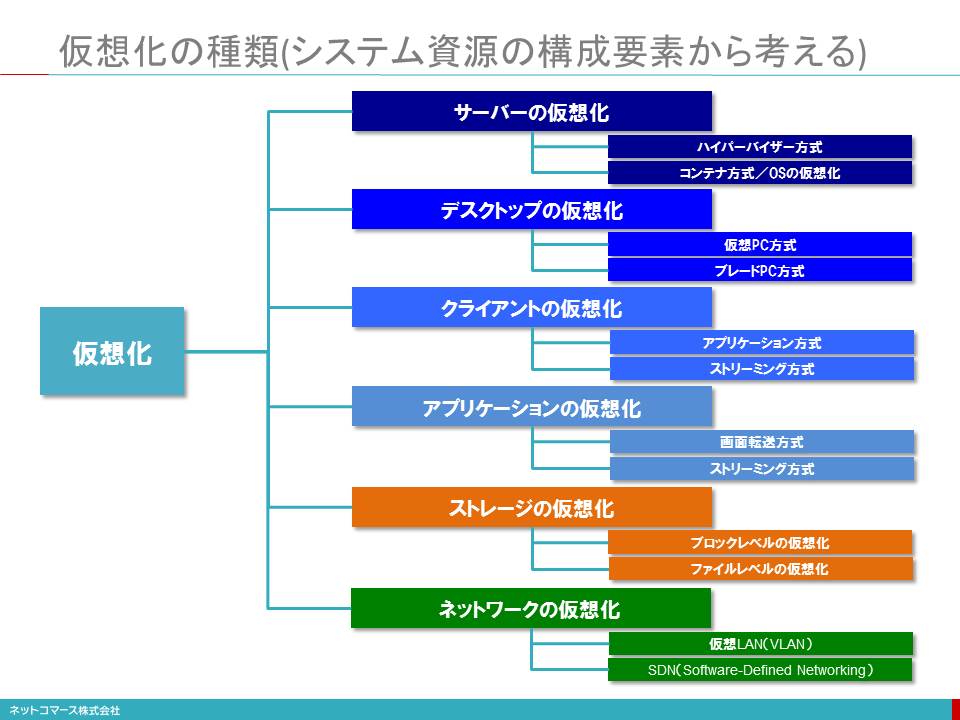
仮想化の3つのタイプ
【図解】コレ1枚で分かる仮想化の3タイプ
仮想化とは、物理的な実態とは異なるものの、あたかもその物理的な実態がそこにあるかのように機能させるソフトウェア技術のことです。
仮想化には、次の3つのタイプがあります。
パーティショニング(分割)
ひとつのシステム資源を複数の独立した個別の資源として機能させます。例えば1台のサーバーを、10台の個別・独立したサーバーが存在しているかのように機能させる場合などです。
この方法を使えば、1ユーザーだけでは能力に余裕のある物理サーバー上に、見かけ上複数のサーバーを稼働させ、複数のユーザーが、それぞれを自分専用のサーバーとして扱うことができます。また、システム資源を余らせることなく有効活用することができます。
アグリゲーション(集約)
複数のシステム資源をひとつのシステム資源のように機能させます。例えば、複数の異なるストレージを1つの大きなストレージに見せかける場合などです。この機能を使わなければ、ユーザーは、複数の別々のストレージの存在を意識し、煩雑な操作や設定を行わなければなりません。しかし、この機能により、そんなことは気にすることなく、またメーカーや機種を意識することなく、1つのストレージとして扱えますので、使用上の利便性は大いに高まります。
エミュレーション(模倣)
あるシステム資源を異なるシステム資源として機能させます。例えば、PC上で、スマートフォンの基本ソフトウェアが稼働し、スマートフォンに模した画面を表示させることができます。スマートフォンにはない、大きな画面とキーボードで同様の操作ができるようになり、アプリケーション開発やテストの利便性を高めることができます。
仮想化というと、「サーバー仮想化」つまり、「パーティショニング(分割)」についてだけ、語られることが少なくありませんが、それだけではありません。ユーザーにとっては、物理的な実態はどうであろうと、必要な機能が実現できればいいわけです。それをソフトウェアの設定だけで実現しようという技術の総称が仮想化というわけです。
以前紹介した、「SDI(Software Defined Infrastructure)」もこの技術が土台にあります。つまり、物理的な実態は、インフラを構成するハードウェアの集まりである「リソース・プール」ですが、そこからソフトウェアの設定だけで必要なインフラ機能を取り出し、構築することができる仕組みです。仮想化を分割の仕組みと捉えると本質を見失いかねませんので、注意が必要です。
ソフトウェア化する世界
【図解】コレ1枚で分かるソフトウェア化する世界
私たちはいま、ソフトウェアというフィルターを通して、世界を見ることが増えつつあります。
例えば、データセンターに設置されたサーバーやストレージ、ネットワーク機器などの様々なシステム資源は、Hyper-VやKVMなどの仮想化ソフトウェア、OpenStackやVMware vCloud、MesosなどのクラウドOSによって管理され、利用者は物理的な機器類を見ることも意識することもなく、必要なシステムの能力を利用できます。
このクラウド・コンピューティングという仕組みにより、物理的にはひとつの大きなシステム資源であるにもかかわらず、利用者にとっては個別の専用システムとして扱うことができます。そして、必要な時に必要なだけのシステム資源を即座に調達することができ、手間のかかる運用管理の大部分もソフトウェアに任せることができるようになりました。
このようなソフトウェアによってハードウェアや設備などの物理的実体を覆い隠し、利用者の利用目的や利用シーンに合わせて、わかりやすく見える化することで、利用者の利便性を高め、作業負担を減らし、しかも柔軟に構成や使い勝手をカスタマイズできる仕組みが、クラウド以外にも私たちの日常や社会に拡がりつつあります。
例えば、物流倉庫では、様々なお客様からの荷物を大量に預かっています。それらを予めお客様毎に物理的に区分けした場所に置くとなると、スペースに無駄が生じ、作業効率も低下します。そこで、倉庫として最も効率よく運用できるように荷物を配置し、それらをソフトウェアで管理することで、利用者にとっては、あたかも自分専用の倉庫を使っているように見える化し、運用や管理も利用者にとって、わかりやすいやり方で使ってもらうことができます。
また、個人が所有する様々な資産、例えば自家用車や自宅の空き部屋、トラックの荷台の空きスペースなどをスマートフォンから登録し、それらをクラウドで共有することで、使いたい人が、使いたいときに依頼すれば、容易に提供できる仕組みも登場しています。これなどもまた、物理的な実体をソフトウェアで管理し、利用者の便宜に応じて提供する仕組みです。
このような大きな仕組みばかりでなく、テレビや電子レンジ、カメラや時計などの家電製品や日用品も、その実体はハードウェアとソフトウェアの組合せによって実現しています。ハードウェアはソフトウェアによって、その取り扱いの難しさを覆い隠され、使いやすくわかりやすいように見える化され、操作も容易になるように工夫されています。
このように物理実体が高機能、高性能になり、その扱いが複雑で手間のかかるものになっても、ソフトウェア化されることで、使い勝手や利便性を高めつつ、その価値を最大限に引き出すことができるような仕組みが、拡がりつつあるのです。
ITインフラと利用形態の歴史的変遷
1950年代、コンピューターがビジネスで利用されるようになりましたが、非常に高価であり、個人が占有して使うことは不可能でした。そこで大型コンピューター(メインフレーム)を共同利用するために、「バッチ」処理が登場します。バッチは処理目的ごとの「プログラムとデータのひとまとまり(ジョブ)」ごとに順次処理するのですが、前の処理が終わるまで次の処理が始められません。
1960年代にはいり、インタラクティブ(対話的)に複数ユーザーが同時に使える「タイムシェアリング(時分割)」が考案されます。これはCPUの処理時間を細かく区切り、その単位でユーザーを切り替えることで、一時点では1ユーザーですが、あたかも同時に複数ユーザーが使えるようになりました。
1960年代後半、この時分割された処理単位毎にハードウェア機能の割り当てや設定を切り替えることで、一台のハードウェアで複数のハードウェアが同時に動いているように機能させる「仮想化」が登場、これにより高価な自分専用機を購入しなくても、専用機を占有するような使い方を実現しました。
1980年代に入り、PCやミニコン、オフコンといった安価なコンピューターが登場したことで、使用上の制約も多いメインフレームの仮想化ではなく、業務ごとに個別に購入して使おうという動きが生まれました。この分散化により企業が抱えるコンピューター台数は増え、バージョンアップやトラブル対応、運用といった維持管理に関わる手間やコストが膨れあがってゆきます。
2000年代に入り、この事態に対処しようと複数のハードウェアを集約できる「仮想化」が再び注目されます。この仮想化されたコンピューターを運用管理とともにインターネット越しに貸し出そうというサービス(IaaS)も登場します。
ただ、仮想化されたコンピューターは、それ毎にOSや設定のためのデータを個別に持ち動かさなくてはなりません。そのためメモリーやストレージなどの資源を大量消費します。そこで同じOSを使い、ユーザーやアプリケーション毎の個別設定だけを保持し、少ない消費資源で個別のコンピューターのように機能させる「コンテナ」方式が登場しました。コンピューターが様々な業務で使われ、変更に即応できるコンテナは、広く普及の兆しを見せ始めています。
サーバー仮想化
サーバーとして使われるコンピュータは、プロセッサー、メモリ、ストレージといったハードウェアによって構成されています。
このハードウェアをオペレーティング・システム(OS)と言われるソフトウェアが制御し、業務を処理するアプリケーションやデータを管理するデータベース、通信制御やユーザー管理を行うシステムなど、様々なプログラムに、ハードウェア資源を適宜割り当て、ユーザーの求める処理を効率よく確実に実行させるように機能します。このOSには、Windows ServerやLinuxなどがあります。
「サーバー仮想化」は、このハードウェアに搭載されているプロセッサーやメモリの使用時間やストレージの容量を細かく分割して複数のユーザーに割り当てます。ユーザーは、割り当てられたシステム資源をそれぞれ占有使用することができます。このような仕組みにより、物理的には一台のハードウェアであるにもかかわらず、自分専用の個別のサーバーがユーザー毎に提供されているように見せかけることができるのです。この見かけ上のひとつひとつのサーバーを「仮想サーバー」または、「仮想マシン」と言い、これを実現するソフトウェアは、ハイパーバイザー(Hypervisor)と呼ばれています。VMware vSphereやMicrosoft Hyper-V、Citrix Xen Server、Linuxに組み込まれているKVMといった製品が広く使われています。
仮想サーバーは、実際の物理的なサーバーと同様に振る舞い、機能します。ですから、サーバー毎に独立したOSを載せ、個別にアプリケーションを実行させることができます。ユーザーは、まるで専用のハードウェアを与えられたような自由度と利便性を享受しつつ、全体としては、ハードウェアの使用効率を高めることができるのです。
コンテナ型仮想化
「サーバー仮想化」の手段として、広く使われているのが、ハイパーバイザを使った仮想化です。ハイパーバイザとは、仮想化を実現するソフトウェアのことで、ハードウェアに搭載されているプロセッサーやメモリの使用時間やストレージの容量を細かく分割して複数のユーザーに割り当てる機能を持っています。ユーザーは、割り当てられたシステム資源をそれぞれ占有使用することで、物理的には一台のハードウェアであるにもかかわらず、自分専用の個別サーバーが割り当てられているように見せかけることができるのです。この見かけ上のひとつひとつのサーバーを「仮想サーバー」または、「仮想マシン」と言い、それを実現するソフトウェアには、VMwareのESXi、CitrixのXen Server、MicrosoftのHyper-Vなどがあります。
「サーバー仮想化」を実現するもうひとつのやり方として、コンテナを使う方法があります。この方法は、ひとつのOSにコンテナと言われる「独立したサーバーと同様の振る舞いをする区画」を複数作り、それを個別のユーザーやサービスに割り当てます。利用するユーザーやサービスから見れば、あたかも独立した個別サーバーのように、別々のサーバーが動いているように見える点は、ハイパーバイザを使う場合と同様です。しかし、同じOS上で実現するので、全てのコンテナは同じOSしか使えません。ハイパーバイザならそれより一段下のレベル、つまりハードウェアのサーバーと同じ振る舞いをする仮想サーバーを実現しますので、仮想サーバー毎に別々のOSを稼働させることができますので、この点は異なります。
その一方で、コンテナは、ハイパーバイザのように、個別にCPUやメモリ、ストレージなどを割り当てる必要がないためシステム資源のオーバーヘッド(仮想化のために割り当てられる資源や能力)が少なくてすみます。そのため、同じ性能のハードウェアであれば、より多くのコンテナを作ることができます。また、コンテナは、それを起動させるためにハイパーバイザ型のように仮想マシンとOSを起動させる手間がかからないため、極めて高速で起動できます。さらにハイパーバイザのように仮想マシンごとにOSを用意する必要がないのでディスク使用量も少なくて済みます。
ひとつのコンテナは、OSから見るとひとつのプロセスとみなされます。プロセスとは、プログラムが動いている状態のことです。そのため、他のサーバーにコンテナを移動させて動かすに当たっても、OS上で動くプログラムを移動させるのと同様に、元となるハードウェアの機能や設定に影響を受けることが少なくてすみます。ハイパーバイザでは、元となるハードウェアの機能や構成に依存し、設定情報も引き継がなくてはなりませんが、コンテナは、その必要がなく、マルチ・クラウドやハイブリッド・クラウドのように、異なるクラウドやサーバー間で実行環境を移動させることも容易です。
このようなコンテナを実現するソフトウェアを「コンテナ管理ソフトウェア」と言います。そのひとつとして、Dockerが注目されています。Dockerとは、Docker社が提供するLinux用のコンテナ管理ソフトウェアです。
Dockerが注目されるようになったのは、そのコンテナを生成する設定を「Dockerfile」として公開し、それを他のユーザーと共有できる仕組みを設けた点にあります。これによって、他のユーザーが作ったソフトウェアとそれを動かすソフトウェア構築プロセスをそのままに他のサーバーで実行し、同じコンテナを労せずして自分のサーバー上で実現して、ソフトウェアをインストールできるようになったことです。そのためハイブリッド・クラウドやマルチ・クラウドといった利用形態に於いては、大変便利な仕組みです。
そのため、Dockerは、AWSやGoogleなどのクラウド・サービス・プロバイダーをはじめ、VMware、IBM、Dell、RedHatなどの大手ITベンダーが採用を表明しています。また、Microsoftも自社のクラウド・サービスであるWindows Azure Platformや次期Windows Serverでの採用を表明しており、コンテナ型仮想化として広く普及してゆくものと思われます。
サーバー仮想化による3つのメリット
【図解】コレ1枚で分かるサーバー仮想化の3つのメリット
物理マシンの集約
物理マシン、つまり機械の台数を減らせることができます。仮想化されていないサーバーは、その機械が持っている能力最大に使われることはあまりなく、また使用率にばらつきがあるのが一般的です。こういうサーバーを束ねて集約することで、一台の機械の能力を無駄なく使えば、使用率は高まり、機械の台数を減らすことができます。
使用率が高く性能が低い旧式機械を使っている場合、その機械の何台分もの能力を持つ新しい機械に集約することで、台数を減らすことができます。
使用する機械の台数を減らせば、購入費用の抑制、電気代やCO2の削減、データセンターを借用している場合は、その使用料を削減できます。
ソフトウェア定義
機械の設置や配線とった物理的な作業を伴わずにサーバー機能や性能の調達、構成の変更が実現します。運用管理者は、画面のメニューやコマンドを使って設定するだけです。もちろん仮想サーバーとして使用しようとしている能力の合計が、物理マシンの能力の上限を超えないことが前提ですが、その範囲内であれば、仮想サーバーの調達や複製、構成変更は、設定だけで可能です。
これにより、仮想サーバーの調達や構成変更が柔軟、迅速に、しかも稼働中にできるようになり、運用管理業務の作業効率を高めることができます。
ライブマイグレーション
仮想サーバーの実体は「設定ファイル」にあります。この設定ファイルにはプロセッサーの能力、メモリーの容量、ネットワークのアドレス番号などの仮想サーバーの設定に関わる情報が書き込まれています。この設定ファイルを、サーバー仮想化を実現するソフトウェア(Microsoft Hyper-VやLinuxのKVMなど)に読み込ませると、物理マシンから必要な機能や性能を取り出し、仮想サーバーを実現してくれます。
この設定ファイルを2台の物理マシンで共有する構成にしておきます。そして、その物理マシンで稼働する仮想化ソフトウェアがお互いの物理マシンの稼働状況を監視させておくとします。もし一方が障害を起こし停止したら、一方の動いている物理マシンが、その仮想サーバーの設定情報を読み出し、動いている方で仮想サーバーを立ち上げてくれます。これにり利用者は物理マシンの障害の影響を受けることなく、仮想サーバーを利用し続けることができます。
障害時ばかりではなく、保守点検で機械を停止させなければならないときなどは、この方法を利用して予め仮想サーバーを別の物理マシンに移動させておき、保守点検が終わったら元に戻すことで、利用者に影響を与えないで物理マシンを停めることができます。
さらに、ある物理マシンの使用率が高まったとき、能力に余裕のある物理マシン仮想サーバーを移動させれば、全体としての負荷の平準化が実現します。
このように、仮想サーバーを停めることなく移動させることもサーバーの仮想化によって実現できます。
仮想化とクラウド(IaaS)との違い
【図解】コレ1枚で分かる仮想化とクラウド(IaaS)の違い
「仮想化」と「クラウド(IaaS)」は、何が違うのでしょうか。
仮想化(Virtualization)は、サーバーやストレージ、ネットワーク機器などのシステム・インフラに関わるシステム資源を、ソフトウェアによる設定や定義によって調達したり、構成を変更したりする技術のことです。例えば、ある一台のハードウェアであるサーバーを、あたかも複数のサーバーが存在し、機能しているように見せかけたり、パラメーターの設定変更で、その機能や構成を変更したりできるようにする仕組みです。
サーバーを仮想化するソフトウェアとしては、MicrosoftのHyper-V、VMwareのvSphere ESXi、LinuxのKVMなどがあります。また、サーバー以外にも、ストレージやネットワーク機器などを仮想化するための製品があります。
ただ、ハードウェアを仮想化しても、その起動やシャットダウン、バックアップやリカバリー、 リソースの変更や監視といった運用や管理のための作業は必要です。また、ユーザーが、どのようなシステム構成にするかを選択し、その設定に従って、機能や性能を調達したり、構成変更したりする作業も必要となります。
IaaSは、仮想化の仕組みを土台に、上記のような運用管理や調達、構成の作業を自動化し、それらを一体として提供するサービスのことです。これは、以前紹介したSDI(Software Defined Infrastructure)の仕組みそのものです。このサービスを特定の企業や組織で占有する場合をプライベート・クラウド、この仕組みを事業者が構築し、複数の企業や組織で共用することを前提に提供するサービスが、パブリック・クラウドです。
このような運用管理や調達、構成の機能を提供しIaaSを構築するソフトウェアを「クラウドOS」と呼ぶ場合があります。例えば、OpenStackやCloudStackなどのオープンソースとして提供されるものや、MicrosoftのAzure StackやVMware のvCloud Suiteなどの商用ソフトウェア(プロプイエタリ)が、あります。
ハードウェアへの直接的な操作をユーザーからは隠蔽し、ソフトウェアの設定だけで、ハードウェアの機能を操作し使えるようにするという点で、WindowsやLinuxのようなOSと似ていることから、そのように呼ばれています。
なお、PaaS(ミドルウェアをサービスとして提供するクラウド・サービス)やSaaS(アプリケーションをサービスとして提供するクラウド・サービス)については、必ずしも仮想化を使わないので、その点は注意が必要です。
IaaSは、ハードウェアの機能や性能を仮想化して利用するサービスであるため「仮想化」は、前提となります。しかし、PaaSやSaaSからは、ハードウェアは、ユーザーにとっては、見えなくてもいい存在です。つまり、PaaSであれば、データベースや開発・実行環境が、複数の企業や組織(テナント)で共有、利用できればいいわけで、仮想化の技術を必ずしも使う必要はないのです。仮想化は、テナント毎に仮想マシンを構築し、OSを起動させなくてはならず、メモリーやCPUなどのシステム資源の消費量が大きくなってしまいます。そこで、ハードウェアをユーザーに意識させる必要のないPaaSやSaaSでは、もっとシステム資源の消費が少ない方法で、複数のテナントに対応できるよう工夫が凝らされている場合も少なくないのです。
仮想化の種類(システム資源の構成要素から考える)
「サーバー仮想化」の他にもシステム資源を仮想化する技術があります。
「デスクトップ仮想化」では、ユーザーの使用するPCを共用コンピュータであるサーバーの上に「仮想PC」として動かし、そのディスプレイ、キーボード、マウスをネットワーク越しに使えるようにします。ユーザーは手元のPCを操作しながらも、実はサーバー上の仮想PCのプロセッサーやストレージを使っているのです。このためディスプレイ、キーボード、マウスそしてネットワーク接続などの必要最低限の機能に限定したPC「シンクライアント」から使うこともできます。ちなみに「クライアント」とは、「サーバーから提供されるサービスを利用する」コンピュータという意味ですが、ここでは、「一時点でひとりのユーザーが占有して使用するコンピュータ」と理解しておけば良いでしょう。
「アプリケーション仮想化」では、MicrosoftのWordやExcelといった、本来ユーザーPC上で稼働するアプリケーション・プログラムをサーバー上で動かし、ネットワークを介して複数のユーザーで共同使用するものです。デスクトップ仮想化と同様にシンクライアントを使うこともできます。
「クライアント仮想化」では、一台のPCにWindowsやMac OSといった異なるOSを同時に稼働させます。
「ストレージ仮想化」では、ストレージ(記憶装置)といわれるデータやプログラムを格納しておく装置を複数のコンピュータで共用し、利用効率や利便性を高めるものです。
「ネットワーク仮想化」では、ネットワークの接続ルートやルーターやスイッチと言われるネットワーク機器の構成をソフトウェアの設定だけで調達、変更できるようにします。
それでは、それらについて見てゆくことにしましょう。
デスクトップ仮想化とアプリケーション仮想化
【図解】コレ1枚で分かる「デスクトップの仮想化」と「アプリケーションの仮想化」
「デスクトップ仮想化」は、サーバー仮想化と同様の技術で、サーバー上にユーザー個別の「仮想PC」を稼働させ、ネットワークを介して、その「仮想PC」の画面を手元のディスプレイに転送・表示させ、キーボード、マウスなどの入出力装置を利用させる技術です。「VDI(Virtual Desktop Infrastructure)」とも呼ばれています。ちなみに「デスクトップ」とは、PC画面のことです。
例えば、仮想PCで、普通のPCと同様にWindowsを動かし、WordやExcelを使い、作成した文書や表は、自分の仮想PCに割り当てられたストレージに保存します。ユーザーは、手元にあるPCのディスプレイ、キーボード、マウスを操作しますが、実際に使うプロセッサーやストレージは、サーバーのものです。
一方、「アプリケーション仮想化」は、PCの全機能ではなく、特定のアプリケーションだけをサーバーで動かし、ネットワーク越しに複数ユーザーで共用する技術です。さらに、ネットワークがつながっていないときでも操作を継続できるようにしたソフトウェアも登場しています。
例えば、MicrosoftのIE(Internet Explorer)6でなければ動かないアプリケーションがあり、同時に最新IEも利用したいとき、IE6を「アプリケーション仮想化」で使用し、PCでは最新IEを動かせば対処できます。また、コンプライアンス上データやアプリケーションを持ち出せないアプリケーションの場合に、自社のデータセンターに設置されているサーバーでこれを動かし、その操作を外部から行うといった使い方もできます。
どちらも管理されたデータセンターに設置されたサーバーで動かすため、データの持ち出しは困難です。また、盗難や置き忘れで手持ちのPCがなくなってしまっても、管理者が、そのPCから仮想PCへのアクセスを遮断してしまえば使えなくなります。さらに、忘れがちなバックアップやセキュリティ対策など、運用管理者が、サーバーに対して一括でできることから、安全安心の担保、運用管理負担の軽減にも役立ちます。
また、自宅で仕事をする場合、自宅のPCからネットワークを介して会社で使っている仮想PCのデスクトップを呼び出せば同じ環境をそのまま使えます。これは、災害や事故でPCが破損してしまっても使えることから、事業継続の観点からも注目されています。
シンクライアント
「デスクトップ仮想化」と「アプリケーション仮装化」は、手元のPC側にOSやアプリケーションを導入する必要はありません。ならば、ネットワークに接続でき、画面表示や入出力操作の機能を動かすことができるだけの必要最小限のメモリやプロセッサでも十分です。また、プログラムや作成した文書や表などのデータをPC側に保管する必要がないので、ストレージも不要です。
そこで、「デスクトップ仮想化」と「アプリケーション仮装化」の使用を前提に機能を最小限に絞ったクライアントPCが作られました。これをシンクライアント(Thin Client)と言います。Thinとは、「やせた」という意味です。ちなみに、通常のPCを、Fat(太った)Clientと呼ぶことがあります。
最近では、タブレットやスマートフォンのアプリで、シンクライアントの機能を実現しているものも登場しています。
シンクライアントは、高い処理能力や大容量のストレージを搭載した一般のPCに比べて大幅に安価です。また、ユーザー個別の設定やアプリケーション、データはサーバー側で管理していますので、仮に機械が故障しても、復旧作業を行わず取り替えるだけで使用を再開できるのでユーザーの管理負担は少なくてすみます。
また、シンクライアントにはデータは保管できませんから、サーバーに接続する手順が分からなければ、盗難に遭ってもデータが盗まれる危険はありません。セキュリティの観点からも安心です。
「シンクライアント」は、このような機能を絞り込んだPCの名称として使われていますが、「シンクライアントが利用できる仮想化方式」すなわち、「デスクトップ仮想化」と「アプリケーション仮装化」の総称としても使われる場合があります。
Chromebook
【図解】コレ1枚で分かるChromebook
今、Chromebookという新しいタイプのノートPCが、注目されています。米Gartner は、2015年、全世界の Chromebook の販売台数は、730万台に達し、PCやタブレットが、二桁を超えて大幅な減少している中、2014年に比べ27%の成長になると予測しています。
Chromebookとは、Googleが開発したChromeブラウザを動かすことに特化した基本ソフトChrome OSを搭載したノートPCのことです。
ブラウザしか動かないというシンプルな機能に特化することで、高速なCPUや大量のメモリが不要となりました。また、アプリをPCにインストールせず、ブラウザを介して、クラウド・サービスとして利用するため、プログラムやデータをPCに保管する必要はなく、大容量のストレージもいりません。同時にデータ流出の危険も減り、バックアップも不要です。さらに、機能がシンプルなために、脆弱性が少なくウイルスに狙われる危険も減り安全性も高まります。また、ユーザーが使えるアプリケーションの選択やデータの範囲などの権限設定も管理者が、一括して管理画面から行うことができるなど、PCを個別に配布することに比べ、運用管理負担を大幅に削減することができます。
これまで「何でもできる」ことを追求し開発されてきたWindowsなどの汎用OSには、快適に動かすためには高性能なハードウェアが必要でしたが、あえて機能を絞り込むことによって、軽量で安価なノートPCを実現したのです。
かつて、メール、表計算や文書作成などは、PCに導入されたアプリに頼っていましたが、今ではブラウザを介してクラウドで利用できるようになっています。その他の業務アプリケーションもクラウドで利用できるものが増えています。
多くのPCユーザーを抱える企業や教育機関は、セキュリティ上の心配が少なく、運用管理側の負担も少ないChromebookに注目しています。まだPCでなければできないことや使い勝手で、従来型のノートPCが必要だとの声も少なくはありませんが、ネットワーク環境やクラウド・サービスの充実とともに、新たな選択肢としてその地位を確立してゆくことになるでしょう。
クライアント仮想化
クライアントの仮想化は、ひとつのクライアントPC上に複数の異なるオペレーティング・システムを同時に稼働させる技術です。
本来、ひとりのユーザーに占有使用されるクライアントPCに、複数の仮想マシンを動かし異なるオペレーティング・システムを稼働させるのは、プログラムやデータの互換性を確保するためです。
例えば、Window 7と言われるPC用のオペレーティング・システム上で、「XPモード」と呼ばれる仮想化の機能が動きます。この機能はWindows 7の前のバージョンであるWindows XPを動かすことができる仮想PCをWindows7の中に作ります。この上で、Windows XPを動かせば、一台のPCの上で、同時にWindows 7とWindows XPを同時に稼働させることができます。
このようなことが必要になるのは、Windows XPでは動くがWindows 7では動かないソフトウェアがあるからです。バージョンアップのためにこれを移行するとなると、プログラムの修正やテスト、購入したパッケージ・ソフトウェアであれば、バージョンアップしなければなりません。そのための作業の手間や費用は、台数が多ければ多いほど、大きな負担となります。しかし、この機能を使えば、XP用として開発、購入したソフトウェアを無駄にしないですむのです。
また、AppleのMac OS上でWindowsを動かすクライアント仮想化のソフトウェアもあります。これを使えば、一台のMac PCでMac OSとWindowsを同時に動かすことができます。そのため、それぞれでしか動かないが、どちらも使いたいと言ったときに、ふたつのPCを用意する必要はありません。また、データも相互にやりとりできますので、大変便利です。
ストレージ仮想化
【図解】コレ1枚で分かるストレージの仮想化
ストレージ仮想化は、ハードウェアの物理的な制限・制約からの解放するために使われる技術です。
例えば、ストレージの容量は、使っている/いないに関わらず、「128GB」というように物理的に決まってしまいます。これをサーバー個別に割り当て、そこでしか使えないのでは、複数サーバーを使っている場合などは非効率です。そこで、複数ストレージをひとつにまとめ複数サーバーで共用し必要な容量だけを割り当てることで使用効率を高めることができます。
また、シンプロビジョニングや重複排除という技術で使用効率や利便性をさらに高めることができます。
シンプロビジョニングは、物理ストレージの容量を実際より多くあるようにサーバー上のアプリケーションに見せかける技術です。これまでなら、物理ストレージの容量が変われば、サーバーやアプリケーションへの設定変更が必要でした。しかし、この技術を使えば、サーバーやアプリケーションには、最初から大きな容量で設定しておき、実際にはその時点で使う容量だけを用意し、足らなくなった容量を物理的に補充するだけで設定の変更が不要になります。これにより容量を節約できると共に運用負担が軽減できます。
重複排除は、データの重複している部分を削減し、ストレージの使用効率を高める技術です。例えば、電子メールでファイルを添付して同時に複数の人に送信すると、同じファイルのコピーがいくつも作られてしまいます。この重複データを削除してデータ容量を削減する一方で、ユーザーには、これまでと変わらず複数のファイルがそこにあるように見せかけることができます。このように、ユーザーに意識させずストレージの容量を減らすことができるのです。
ビッグデータの時代となり、ストレージの需要が高まる中、効率よくストレージを利用し、運用や管理の負担を軽減することへの需要は、益々高まってくるでしょう。
コンバージド・システムとハイパーコンバージド・システム
インターネットに繋げば、いつでも何処でも望む情報が手に入り、アプリケーション・サービスをうけられるようになりました。その結果、必要となるシステム資源は、質的にも量的にも従来とは桁違いの規模となり、これが継続的に増大する状況が生まれています。これを「Webスケール」と呼んでいます。パブリック・クラウドは、このWebスケールに対応しなければなりません。
そのためには、CPUやメモリ、ストレージなどのハードウェア能力をそれぞれ個別に増強する「スケールアップ」では、すぐに物理的な限界に達してしまいます。そこで、同様のハードウェアを並列に追加してゆき、全体の規模を拡大して、並列処理させることで能力を増強する「スケールアウト」での対応が、一般的です。スケールアウトにすれば、継続的な需要の増大に際しても、ハードウェアを追加してゆくことで、容易に能力を増強できるのです。
スクリーンショット 2015-06-11 7.42.30.png
このようなスケールアウトの考え方をパブリック・クラウドではなく、プライベート・クラウドのインフラとして提供しようという製品が登場しています。これらは、「ハイパー・コンバージド・システム」と言われ、Nutanix、EVO:RAIL、Simplivity、VCEのVxRackなどの製品が登場しています。これら製品は、サーバー、ネットワーク、ストレージで1単位の標準化されたモジュールで構成され、これを追加してゆくことで、すなわち、スケールアウトでシステムの能力を増強することができます。
これまでも、サーバー、ネットワーク、ストレージをひとつの筐体に収め、システムの接続や基本的な設定を予め済ませて出荷する「コンバージド・システム(垂直統合システム)」と言われる製品はありました。例えば、Oracleの Exalogic Elastic Cloud、IBMのPureFlex System、VCEのvBlock、HP のConvergedSystemなどがあります。
しかし、能力の拡張となると構成要素毎に個別対応しなければならず、しかも、接続や設定などが複雑になります。規模や構成を変えないことを前提に使うには、導入や設定、運用も容易なのですが、スケールアウトには簡単に対応できないものでした。
一方、「ハイパー・コンバージド・システム」は、標準化されたモジュールを追加することで、能力をスケールアウトに拡張でき、その構成や設定も自動で行われます。能力の拡張を迅速かつ段階的に行う必要があるインフラ用途として有効です。また構成や設定を全てソフトウェアで行えるSDI(Software Defined Infrastructure)を構築する手段としても注目されています。
スクリーンショット 2015-06-11 7.42.56.png
米Gartnerは、「2015年の戦略的テクノロジ・トレンドのトップ10」にWeb Scale ITとして、これを取り上げ、注目しています。
SDN(Software Defined Networking)
【図解】コレ1枚で分かるSDN
従来、ネットワークの構築は、異なる役割や機能を持つ多数の機器をケーブルで接続し、それぞれの機器に手間のかかる設定が必要でした。この常識を変えたのが、SDN(Software-Defined Networking)です。
SDNとは、ルーターやスイッチなどのネットワーク機器の構成や機能、ネットワーク接続ルートなどを、物理的な機器の導入や配線などの作業をしなくても、ソフトウェアへの設定だけで実現する技術の総称です。
例えば、異なる複数企業のシステム機器が混在して設置されているデータセンターの場合、従来であれば、独立性を保証するため各社毎に機器もネットワークも物理的に分離して別々に管理しなければなりませんでした。しかし、SDNであれば、全てをひとつの物理的なネットワークでつなぎ、設定だけで分割して個別独立のネットワークに見せかけることができます。また、ルーターやスイッチ、ファイヤーウォールなどの機能や役割の違う物理的な機器が必要でしたが、物理的には同じ機器を使って、設定だけで必要とする機能構成を実現することもできます。このような仕組みをNFV(Network Functions Virtualization:ネットワーク機能の仮想化)と言います。
また、ネットワーク全体を一元的に集中制御できるので、個々のネットワーク機器の設定に時間を取られません。
さらに、利用目的に応じた「ポリシー」に応じてネットワークの特性を自由に制御できるようになりました。ポリシーとは、どのように扱うかの方針や制約条件を体系的かつ具体的に定めた規範のことです。
例えば、セキュリティを高度に保ちたい、負荷分散を行いたい、音声や映像は途切れないように優先的に処理したいといった、アプリケーションに応じたポリシーを設定し、それに応じてネットワーク全体の挙動を制御できるようになったのです。
かつては、運用管理者が、アプリケーションのポリシーに応じて、手作業で個々のネットワーク機器の構成や設定を行っていました。しかし、SDNに対応したハードウェアやソフトウェアの登場により、これらの作業をネットワーク全体に対して一括して、あるいは、アプリケーションからの要求に応じて自動的で対応できるようになったのです。
これにより、ネットワークの運用管理負担が軽減されると共に、アプリケーションの変更に即応できる柔軟なネットワークが実現したのです。
SD-WAN(Software-Defined Wide Area Network)
ブロックチェーン
【図解】コレ1枚でわかるブロックチェーン
ブロックチェーン(blockchain)とは、複数のシステムで取引履歴を分散管理する技術のことです。これには暗号技術とP2Pネットワーク(通信ノード間で中継を介さず直接通信する)技術が使われており、第三者機関による証明がなくても取引の正当性を証明でき、データの改ざんを困難にしています。
ブロックチェーンは、もともと「政府や中央銀行による規制や管理を受けることなく、誰もが自由に取引でき、改ざんなどの不正ができないインターネット上の通貨」として開発されたビットコイン(Bitcoin)の信頼性を担保するための基盤技術として、サトシ・ナカモトと名乗る人物が論文中で初めて原理を示したことが誕生の切っ掛けとなっています。
この論文に基づいて有志の協力によりオープン・ソース・ソフトウエア(OSS)としてビットコインが開発され、2009年より運用が始まっています。運用が開始されて以降、改ざんなどの被害を受けることなく取引が継続されており、その仕組みの有効性・信頼性については認められつつあります。なお、日本にあったビットコインの取引所Mt.Goxのシステムが2014年に外部からの不正侵害による窃盗行為によるものとして取引が停止され大きな社会問題になりましたが、これはビットコインそのものの問題ではなく、ビットコインの取引を仲介するシステムの問題であり、これによってビットコインそのものの信頼性が侵害されたわけではなく、両者は分けて考えなくてはなりません。
さて、このビットコインの信頼性を担保する基盤となったブロックチェーンは、「複数のシステムで取引(トランザクション)の履歴を分散共有し監視し合うことで、取引の正当性を担保する仕組み」といえるでしょう。
一般的な取引では、法律や規制、あるいは実績によって信頼される第三者機関/組織が取引の正当性を保証し、その取引の履歴を一元的に管理することで、信頼性が担保されていました。
ブロックチェーンの技術を使うと、
ブロックチェーンのネットワークに参加する全てのノードに取引が通知され、だれもがその取引の内容を知ることができる。
定められたルール(コンセンサス[合意]するための手順)に従って特定のノードが取引のまとまりである「ブロック」を分散共有された台帳に登録することが許され、登録します。ここでいう台帳とは、取引のまとまりである「ブロック」を時間軸に沿ってチェーンのようにつないだもので、これが「ブロックチェーン」と呼ばれる所以です。
この台帳に取引記録が追加されると(=ブロックチェーンに新たなブロックが追加されると)、これに参加する全てのノードで新しいブロックチェーンが共有されます。
この一連の仕組みにより、膨大な複数のノードにより取引の履歴は分散共有され、取引の存在と正当性が特定の第三者に頼らなくても証明されるのです。また改ざんしようとしても、分散共有された膨大な数のブロックチェーンの特定のブロックをほぼ同時に改ざんしなければならず、結果として改ざんが不可能になっているのです。例えば、ビットコインの場合は、膨大な数のノードが四六時中ブロックチェーンの更新を行っており、この全てのノードの51%以上を改ざんしなければ、改ざんは成立しません。これは、強力なスパーコンピューターを駆使しても改ざんができない規模となっており、現実的には改ざんができないようになっているのです。
また、ブロックチェーンでは取引者の情報は暗号化されているため、取引の内容は公開されても取引者の具体的な情報に紐付けされていないので匿名性は担保されています。
ブロックチェーンは、ビットコインに代表されるパブリックな取引への適用ばかりではありません。改ざんを困難にする仕組みや、低性能なシステムを分散ノードとして使用し無停止で運用可能なことから、銀行取引や契約などの中核となっている元帳管理に適しているとして、プライベートなシステムでの適用にも注目されるようになってきました。例えば、銀行の預金や為替、決済などの勘定系業務、証券取引、不動産登記、契約管理などへの適用についての検討や研究が進められています。
例えば、米株式市場のNASDAQは、「ブロックチェーン」を使った未公開株式取引システム「Nasdaq Linq」を発表、また三菱UFJフィナンシャル・グループ(MUFG)が、ブロックチェーン技術に強みを持つスタートアップ企業米R3が主催し、英バークレイズ銀行、米シティグループなど世界的大手金融機関22行が参画する「Distributed Ledger Group」に参加、さらにIBMがIoTのスケーラビリティとセキュリティを確保する技術「ADEPT(Autonomous Decentralized Peer-to-Peer Telemetry)」にブロックチェーンの技術を適用するなどの取り組みが始まっています。
このようにブロックチェーン技術は、実用に向けた様々な取り組みが積極的にすすめられており、今後ますます注目されるようになってゆくでしょう。
多層防衛
【図解】コレ1枚でわかる多層防衛
ITシステムは、その適用範囲を拡大すると同時にセキュリティ侵害の危険性を高めてしまいました。また、技術の進化は、攻撃の技術をも進化させ、その対策を難しくしています。
例えば、PCがウイルスに感染して情報が漏洩してしまうことを想定した場合、ウイルス対策ソフトを導入してPC自体のセキュリティを強化することが行われます。しかし、ウイルス対策ソフトをくぐり抜ける高度な攻撃を受けてしまえば、被害はシステム資源全体に及ぶ危険性もあります。
このような事態に対処する手段として「多層防御」という考え方が生まれました。
多層防御とは、PC自体のセキュリティ対策だけではなく、ネットワークやサーバーなど、PCにウイルスが侵入する経路をも考え、その経路上でも対策を施し、ITシステム全体のセキュリティ強度を向上させようというものです。それは、単に技術的な対策に留まるものではなく、運用方法や操作方法、ビジネス・プロセスや戦略まで含んだ広範な取り組みです。
例えば、ウイルス対策ソフトが破られてもネットワークで防ぎ、それが突破されてもサーバーで防ぐといったように、幾重にも防御を施し、システム全体でセキュリティ侵害を防ぐことができます。また、対策を多層にすることで、セキュリティ侵害に手間をかけさせ時間を稼ぐことで、事態を発見しやすくすることも可能になります。
技術面の対策としては、IDやバスワードを認証したり、許可された使われ方をしていない端末を遮断したりと言った「認証対策」、ウイルス対策ソフトの導入、セキュリティ更新プログラムの適用、不正なプログラムの起動防止、不正な通信の禁止、盗難・紛失による情報漏洩防止といった「デバイス対策」、暗号化などの「データ対策」が挙げられます。
もちろん、このような技術的な対策だけでは完璧ではありません。セキュリティを侵害する技術は、日々進化し攻撃力を増しています。また、スマートフォンやタブレットは、ビジネスの現場でこれまでにも増して使われるようになり、BYOD(Bring Your Own Device:個人のデバイスを業務目的で使用すること)も普及し、対策すべきリスクも高まります。
これに対処するには、技術面に頼るだけではなく、事故や外部からの侵害を招かないための業務手順を整備することや、事故や侵害が起きてもすぐに気付くことがでる体制や手順を整えること、事故や侵害が起きたときの対策を予め準備しておくなどなどの総合的な対策が、重要になります。
CSIRT(Computer Security Incident Response Team)
【図解】コレ1枚でわかるCSIRT
「標的型攻撃」や「リスト型攻撃」などのサイバー攻撃は、巧妙化の度合いを増しています。そのため、どんなに堅牢に防御しても、セキュリティ事故(セキュリティ・インシデント)を完全に防ぐことはできません。
そこで、「インシデントは必ず起きるもの」という前提で、対応体制を構築し、備えておくことが求められています。このような情報セキュリティ対応の中核を担うのがCSIRT(Computer Security Incident Response Team)です。
CSIRTは、自社へのサイバー攻撃を検知し、セキュリティ事故が発生すれば直ちに緊急対応します。インシデントに対応する「火消し役」と考えるとわかりやすいかもしれません。主な役割は、次3点です。
社内対応:セキュリティ情報の提供や指示・命令系統の整備・管理
社外対応:社外からの問い合わせやインシデント情報についての統一した対外窓口(POC : Point of Contact)
情報連携:外部のセキュリティ組織や他社のCSIRTと連携し、セキュリティに関する情報を共有
インシデントに対抗するためには、セキュリティ対策を施したシステムの構築や運用管理、セキュリティに関する啓蒙活動や制度上の整備などが不可欠です。しかし、対策に完全はあり得ません。そのために、インシデントが発生すれば、直ちにそれを検知し対策を講じる体制としてCSIRTが必要になるのです。
CSIRTは、恒常的な部門として組織されることもあります。しかし、そのための要員やスキルを維持し続けることは容易なことではありません。そこで、必要に応じて招集される組織する場合もあります。前者は、「消防署」であり、後者は「消防団」のような組織に例えるとわかりやすいかもしれません。
また、社内の要員だけでは、日々高度化、巧妙化するサイバー攻撃に対抗することは困難です。そこで、セキュリティ対策を専門とする企業や、セキュリティ情報を共有、あるいは、支援してくれる外部組織との連携も必要です。
CSIRTの歴史は古く、インターネット黎明期の1988年、アメリカで甚大な被害を与えたマルウエア「Morris worm」対策のため、情報共有や組織間で連携する必要性が高まり、その連絡調整を担う組織として「CERT/CC(Computer Emergency Response Team / Coordination Center)」という組織が、米カーネギーメロン大学内に設置されました。これが世界で最初のCSIRTと言われています。
その後、世界各国で同様のCSIRTが作られるようになり、各国のCSIRTをまとめ、他国との情報の収集や共有を行うための世界的な非営利組織FIRST(Forum of Incident Response and Security Teams)が、1990年に設立されました。1996年、我が国でも「JPCERT/CC」という組織が設立され、インシデント情報の共有、対策の研究やガイドラインの作成、取り組みについての啓蒙などが行われています。
セキュリティ・インシデントは、増え続けています。この現実から逃れる術はありません。この事態に対応するために、企業はCSIRTを設置し、適切に機能させることで、例えインシデントが発生しても被害を最小限に食い止め、再発防止にも貢献することが、求められているのです。
第6章 開発と運用
これからのシステム開発
ビジネス環境は不確実性を増し、変化のスピードは加速しています。ビジネスはこの変化に柔軟・迅速に対応できなくてはなりません。そんな変化への即応力こそが、強い経営基盤となるのです。
そんなビジネスは、ITとの一体化がすすんでいます。もはやITは、ビジネス・プロセスを支える基盤として欠かすことのできない存在です。もしITが使えなければ、ビジネス活動が大混乱に陥り、業務が停止してしまうかもしれません。また、ITを武器にビジネスを差別化する「デジタル・ビジネス」への取り組みも拡大しています。そうなると、ビジネス環境の変化に、柔軟・迅速に対応するためには、ITもまた、同じスピードで対応できなければなりません。
このような状況にあって、
時間をかけて業務要件を定義し、仕様を固める。
工数と見積金額で競合させて業者を選定する。
仕様凍結し、その仕様書に従ってコーディングとテストを行う。
数ヶ月を経て、ユーザーにリリースし、改修箇所・追加機能を洗い出す。
改修作業や機能の追加、変更のために作業する。
インフラや実行環境を、アプリケーションに合わせて構築・調整する。
十分なテストを行った後、ユーザーにリリースする。
こんなやり方で、加速するビジネス・スピードに対応することはできないのです。
ビジネス・スピードが緩やかだった時代は、このようなやり方でも対応できました。しかし、ビジネス・スピードが加速し、日々めまぐるしく変化するいま、業務要件も日々変わってしまいます。あるいは、業務要件も決まらない先に、開発を先行しなければならないこともあります。さらに、インフラやプラットフォームの仕様をアプリケーションに合わせて決定し、調達、構築していては、開発途中でアプリケーションの仕様が変わっても対応できません。もはや従来までのやり方では、いまのビジネス・スピードに対応できないのです。
「仕様書や手順に従い情報システムを開発・運用することではなく、情報システムを使ってビジネスの成果に直接貢献する」
そんな取り組みが求められています。そのためには、次の3つの条件を満たさなくてはなりません。
ビジネス・ニーズに迅速に対応でき、その変更にも柔軟に対応できること。
アプリケーションでの変更を、直ちに本番環境に反映できること。
予期せぬ負荷の増大や縮小に直ちに対応できること。
この条件を満たすために、次のような取り組みが始まっています。
■アプリケーション開発・変更に迅速に対応するアジャイル開発
アジャイル開発が生まれるきっかけは、1986年に経営学者である野中郁次郎と竹内弘高が、日本の製造業の高い効率と品質を研究した論文をハーバード・ビジネスレビュー誌に掲載したことにあります。それを読んだジェフ・サザーランド(Jeff Sutherland)らが、システム開発への適用を考え、1990年代半ばにアジャイル開発の方法論としてまとめました。
ですから、アジャイル開発には、伝統的な日本の「ものづくり」にある、「不断の改善により、品質と生産性の向上を両立させる」という精神が、埋め込まれているといっても良いでしょう。
その精神の根本には、現場重視の考え方があります。現場とは、「業務」と「製造」の現場です。
「業務の現場」であるユーザーと「製造の現場」である開発チームが、ビジネスでどのような成果をあげたいのか、そのために何をしたいのか、その優先順位や使い勝手はどうなのかを共有し、不断の工夫と改善によって無駄を省き、迅速・柔軟に、コストを掛けずに高品質なシステムを開発しようというのです。
「仕様書通りのシステムを手間暇掛けて開発し、工数を稼ぐ」ビジネスとは相容れません。少ない工数と短い期間で、ビジネスの成果に直ちに貢献できるシステムを開発する。アジャイル開発は、そんな取り組みと言えるでしょう。
■本番環境への迅速な移行、継続的なデリバリーを実現するDevOps
開発チームが、アプリケーションの開発や変更に即応できても、本番環境に反映できなければ、その成果を業務の現場が享受することはできません。一方、運用チームは、システムを安定稼働させる責任を負っています。開発できたからといって、すぐに受け入れて本番環境に移行させることで、安定稼働ができないとなると大問題です。そこで慎重に検証し、システムの調達や設定などの対応をし、大丈夫となれば本番移行を受け入れます。それには相応の時間が必要であり、加速するビジネスのスピードに対応できません。
そこで、開発チーム(Development)と運用チーム(Operations)が、お互いに協調し合い、また運用や本番移行を自動化する仕組みなどを積極的に取り入れ、開発と運用が途切れることなく連続する仕組みを実現し、ビジネスを止めずに、継続的にデリバリーする取り組み「DevOps」が、注目されています。
■迅速な調達を実現するインフラ、高速開発と実行を支えるプラットフォーム
DevOpsを実現するためには、インフラ資源の調達・変更も柔軟・迅速でなくてはなりません。そのためにサーバーやストレージなどの物理資源を個々のアプリケーションに合わせて導入、設定している余裕はありません。そこでインフラはSDIや、そのクラウド・サービスであるIaaSが前提となります。
それでもまだインフラを意識して、アプリケーションを開発しなくてはなりません。そんなことに気をかけることなく開発、実行できれば、その柔軟性と迅速性は高まります。
そのためには予め用意された機能部品を組合せ、連係させてアプリケーションを開発実行させる仕組みや、業務プロセスを記述し、画面や帳票を定義すれば、プログラム・コードを生成してくれるツールなども登場し、開発スピードだけではなく、変更への柔軟性を担保できるようになりました。
こんな様々な取り組みが、これからの開発や運用を支えようとしています。
アジャイル開発(1)
【図解】コレ1枚でわかるアジャイル開発
ユーザーの要求は時間とともに変化します。ビジネス・スピードが加速するなか、この要求が変化するスピードもまた速まっています。いま、情報システムの開発には、このような変化への即応性がこれまでになく求められているのです。
しかし、従来は、作るべきシステムの要件を「すべて」決めてしまってから開発をスタートする「ウォーターフォール」手法が主流でしたが、このようなやり方では対応できない事態も増えてきたのです。そこで、注目されているのがアジャイル開発です。
アジャイル開発の本質は、「全部作らない」ことです。これが、ウォーターフォール開発と本質的に異なる点です。アジャイル開発は、「業務上必要性が高い機能や業務プロセスを選別し、優先順位を決めて、そこにリソースを傾注することで、本当に使うシステムのみを作り上げよう」という考え方です。結果として、短期間、高品質での開発が実現するのです。
一方、ウォーターフォール開発は、「全部作る」を前提とします。そのため、ユーザーの要求がすべて決まらなければ開発に着手できません。そのため、将来使うかもしれない機能とともに、推測を交えて仕様を固めてゆきます。また、いったん作り始めると、途中で変更することは難しく、すべてを作り上げることが優先されます。変更や品質保証は全部コードを書き終えた最後の最後に対応しなければなりません。
アジャイル開発の手法を使っても、「全部作る」のであれば、ウォーターフォールと本質的には何も変わりません。アジャイル開発は「全部作らない」かわりに、短期間・高品質・変更への柔軟性を担保しようというもので、「全部作る」こととトレードオフの関係にあのです。
アジャイル開発では、「ビジネス価値の高い=業務を遂行上必須」のプロセスを実現する機能に絞り込んで開発対象を決めてゆきます。「必要かどうかわからない」、「あったほうがいいかもしれない」は、作りません。そして、おおよその工数と期間の見通しを立てて開発を始めます。
ビジネス価値で優先順位を決められた機能を順次完成させてゆくため、途中で優先順位が変われば入れ替えることができるので、変更要求に柔軟に対応できるのです。
重要なところから完成させるので、重要なところほど早い段階から検証されバグは徹底して潰されます。また、後期になるほど重要度が低くなるので、問題が生じても全体への影響は少なく品質は高まります。
アジャイル開発の狙いを整理すれば、次の3つになるでしょう。
予測できない未来を推測で決めさせず、本当に使うシステムだけを作ることでムダな開発投資をさせない。
変更要求に柔軟に対応し、納得して使えるシステムを実現する。
納得できる予算と期間の中で最善の機能と品質を実現する。
そもそもアジャイル開発が生まれるきっかけは、1986年に日本の経営学者である野中郁次郎氏と竹内弘高氏が、日本の製造業の高い生産性と効率を研究した論文をハーバード・ビジネスレビュー誌に掲載したことにあります。それを読んだジェフ・サザーランド(Jeff Sutherland)氏らが、システム開発への適用を考え、1990年代半ばにアジャイル開発の方法論としてまとめました。ですから、アジャイル開発には、伝統的な日本の「ものづくり」にある、「不断の改善により、品質と生産性の向上を両立させる」という精神が、埋め込まれているといっても良いでしょう。
アジャイル開発(2)
超高速開発ツール
DevOpsとは何か?
DevOpsとコンテナ管理ソフトウェア
【図解】コレ1枚でわかるDocker
コンテナ管理ソフトウェアが、ハードウェアやOS毎の違いを吸収してくれるため、既にアプリケーションやミドルウェアの稼働が確認されているコンテナであれば、他のサーバーに移して動かしても確実に動くことが保証されます。
<参照>【図解】コレ1枚で分かる仮想マシンとコンテナの違い
http://blogs.itmedia.co.jp/itsolutionjuku/2016/12/post_340.html
この特性を利用すれば、アプリケーション開発者は、OSやインフラの違いを意識することなく、アプリケーションを開発することができます。また、運用管理者は、「コンテナ管理ソフトウェア」でOSやインフラの安定稼働を保証しておけばいいわけで、これまでのようにアプリケーション開発者と運用管理者がアプリケーション毎に本番環境への移行を個別に相談し対応しなくてもよくなります。
アプリケーション開発者は迅速にアプリケーションを開発、変更しユーザーに提供する、一方、運用管理者はシステムを安定稼働させるといったそれぞれの責任を独立して果たすことができるようになり、本番環境へのデプロイメント(移行作業)は迅速、頻繁に行えるようになり、アプリケーション開発や変更のメリットをユーザーが直ちに享受できるようになるのです。
このようなコンテナを実現する「コンテナ管理ソフトウェア」のひとつとして、ほぼ業界標準となっているのがDocker社の提供する「Docker」です。
Dockerが注目されるようになったのは、Dockerで動作が保証されているコンテナを生成する設定を「Dockerfile」として公開し、それを他のユーザーと共有できる仕組みを設けた点にあります。これによって、他のユーザーが作ったソフトウェアとそれを動かす手順を他のサーバーでもそのまま再現できるようになったことです。そのためハイブリッド・クラウドやマルチ・クラウドといった異なるOSやインフラでも動作保証される便利さが注目されているのです。
このような機能を持つDockerは、AWSやGoogleなどのクラウド・サービス・プロバイダーをはじめ、VMware、IBM、Dell、Red Hatなどの大手ITベンダーが採用を表明しています。またDockerは、もともとはLinux用に作られたものですが、MicrosoftもWindows Serverや自社のクラウドサービスであるAzure Platformでの採用を表明しており、コンテナ管理ソフトウェアとして広く普及しつつあります。
Immutable Infrastructure と Infrastructure as Code
マイクロサービス(Microservices)
ソフトウェアは様々な機能を組み合わせることで、必要とされる全体の機能を実現します。
例えば、オンライン・ショッピングの業務を処理するソフトウェアは、ユーザー・インタフェースとビジネス・ロジック (顧客管理、注文管理、在庫管理など) という特定の業務を処理する機能を組合せることで実現します。必要なデータは、すべてのロジックで共有するデータベースに格納され、各ロジックはひとつのソフトウェアの一部として組み込まれます。もし、複数の注文があれば、その注文の単位でソフトウェアを並行稼働させることで対応できます。このようなソフトウェアをモノシリック(巨大な一枚岩のような)と呼びます。
ただ、このやり方では、商品出荷の手順や決済の方法が変わる、あるいは顧客管理を別のシステム、例えば外部のクラウド・サービスを利用するなどの変更が生じた場合、変更の規模の大小にかかわらず、ソフトウェア全体を作り直さなければなりません。また、変更を重ねるにつれて、当初きれいに分かれていた各ロジックの役割分担が曖昧かつ複雑になり、処理効率を低下させ、保守管理を難しいものにしてゆきます。さらにビジネスの拡大によって注文が増大した場合、負荷が増大するロジックだけ処理能力を大きくすることはできず、ソフトウェア全体の稼働数を増やさなくてはならず、膨大な処理能力が必要となってしまいます。
このようにビジネス環境が頻繁に変わる世の中にあっては、このやり方での対応は容易なことではありません。
この課題に対応しようというのが、マイクロサービス方式です。このやり方は、ソフトウェアを互いに独立した単一機能の部品に分割し、それらを連結させることで、全体の機能を実現しようとするもので、この「単一機能の部品」をマイクロサービスと呼びます。
個々のマイクロサービスは他とはデータも含めて完全に独立しており、あるマイクロサービスの変更が他に影響を及ぼすことはありません。その実行も、それぞれ単独に実行されます。
この方式を採用することで、機能単位で独立して開発・変更、運用が可能になること、また、マイクロサービス単位で処理を実行させることができるので、処理量の拡大にも容易に対応することができます。
イベントドリブンとコレオグラフィ
【図解】コレ1枚で分かるイベント・ドリブン方式
ある業務で一連のサービス(特定の業務を処理するプログラム)を連結させて全体の処理を行う方式に、オーケストレーション(Orchestration)とコレオグラフィ(Choreography)があります。
前者は、指揮者の指示に従って各演奏者が担当する楽器を演奏するように、全体の処理の流れを制御する指揮者にあたるプログラムが存在し、そこからのリクエストによってサービスを実行し、実行結果をレスポンスとして指揮者に返して処理を継続させる方式で、リクエスト・リプライ方式と呼ばれています。
各サービスは、そのサービスを制御する指揮者が受けもっている特定の処理のためだけに利用され、他の指揮者が制御する別の処理を引き受けて実行することはありません。そのため処理が増えれば、指揮者のプログラムもその数必要となり、同時に多くのサービスが駆動されます。
一方、後者は、演劇や踊りで演技者に予め振り付けが行われるように、個々のサービスに予め動作条件や次にどのサービスを起動させるかといった設定が与えられており、それに従って、各サービスが自律的に動作する方式です。
この方式は、何らかのイベントの発生によって特定の業務処理サービスが駆動される場合が多く、イベント・ドリブン方式と呼ばれています。イベントには、「新規注文が入った」、「商品が入庫した」、「新規顧客が登録された」などがあります。
リクエスト・リプライ方式は、指揮者が関知できないタイミングで行われた処理や、予期できないタイミングで発生したイベントを検知して対応することは難しく、処理ができなかったりタイミングが遅れたりといったことが起こります。一方、イベント・ドリブン方式では、イベントの発生時に次に続くサービスに即座に通知できますので、処理タイミングを遅らせることはありません。また、イベントが増えても、必要なサービスだけが起動されますので、システム資源の消費量は少なく、負荷の変動にも柔軟に対応できます。このサービスを先に紹介したマイクロサービスにしておけば、開発や運用を効率よく行うことができます。
FaaS(Function as a Service)
APIエコノミー
FinTech
お金は生活においてもビジネスにおいても欠かすことのできない存在です。その貸し借りや決済、通貨の流通は、絶対的な安心や安全が担保されなくてはなりません。そのために国家のお墨付きや企業規模と言った「権威」によってそれが保証されていました。しかし、ITの進化によりお金のやり取りがリアルタイムで把握できるようなった。
ソーシャル・メディアなどに個人が実名で様々な考えを表明したり行動が公開されたりと、借り手のことを詳しく知る新たな手立てが生まれた。
暗号化や匿名化の技術も進歩しインターネットでも安全、安心に取引できるようになった。
このような変化に呼応してお堅いとの印象もある銀行が、残高照会、入出金明細照会、口座情報照会といった情報を、インターネットを介して提供するための標準化への取り組み「BIAN(Banking Industry Architecture Network)」にも参加し、情報の提供をはじめようとしています。
さらに、それらデータを分析する手段として人工知能が使えるようになり、人間が手間をかけてデータを精査することなく信用の度合いを自動的に評価できるようになりました。また、このような仕掛けにより少額の取引でも十分に利益の出るビジネスや新たな金融サービスができるようになったのです。
また、インターネットを利用して金融機関に書類を提出しなくても手続きができるようになり、その利便性は大いに増し利用者の裾野を拡げています。
また、資金運用においても膨大な市場データを様々な角度から分析し、個人の要望にもきめ細かく答えられる人工知能やそれをいつでも、どこでも、わかりやすい画面で利用できるスマートフォンやWeb技術の進化もまた、FinTechビジネスの拡大に拍車をかけています。
「安全や安心が価値」というこれまでの常識から、「便利で手軽という価値」というこれからの新しい常識を利用者が求めるようになり、金融はいまあらたな可能性を求めて大きく変わり始めています。
運用技術者からSREへ
インフラにおける日々の運用業務は、クラウド事業者に任せられるようになりました。またインフラを使うために必要な設定は、クラウドであればツールやAPI(Application Program Interface)を介して使えるようになり、アプリケーション開発者にもできる時代です。
このような仕組みが、先に紹介したインフラを設定する全ての手順をコード化する「インフラストラクチャー・アズ・コード」です。
こんな時代に運用技術者に求められる役割も大きく変わろうとしています。例えば、これまで求められてきた業務は、次のような内容でした。
ITの実務上の利用方法について問い合わせを受けて対応する窓口業務
定められたオペレーションを繰り返し実施する定常業務
ITに関するトラブルに対応する障害対応業務
インフラに関する管理業務(構成管理やキャパシティ管理など)
このような業務は積極的にクラウド・サービスや自動化ツールに置き換え、どんどん変わるビジネス要件に柔軟・迅速に対応できるインフラ環境を作ることへと、業務の重点を移してゆくことが求められています。
具体的な業務は次のようなものです。
変更への即応性や信頼性の高いシステム基盤を設計
運用管理の自動化/自律化の仕組みを設計・構築
開発者が利用しやすい標準化されたポリシーやルールの整備 など
このような役割を担う技術者は「SRE(Site Reliability Engineer)」と呼ばれています。彼らは、開発者とサービス・レベルの目標値を共有し、協力しながら開発やテスト、本番稼働に必要なインフラ環境をすぐに使える組織横断的な仕組みを作ることに取り組みます。
インシデント対応やインフラの安定稼働といった守りの役割から、加速するビジネス・スピードの変化に対応し「ビジネスの成果に貢献する」することへと、運用技術者の役割は、大きく拡がろうとしているのです。
巻末 最新トレンドを理解するためのITの基礎知識
ITと情報システムの関係
情報システムの構造
プラットフォームの変遷
インターネットとは
インターネットとWebサイト
企業情報システム(エンタープライズアプリケーション)
個別業務システムとERPシステムの違い
SCM(Supply Chain Management)とは
CRM(Customer Relationship Management)
企業情報システム(エンタープライズアプリケーション)
CAE/CAD/CAMシステム
ITの専門家ではないお客様に語る力を持つ
SIビジネスの課題に向き合うためのポストSIの戦略とシナリオ
ITビジネス・プレゼンテーション・ライブラリー
主トピック 135